经典(java版)排序算法的分析及实现之一直接插入排序
2014-10-19 18:42
211 查看
预备知识
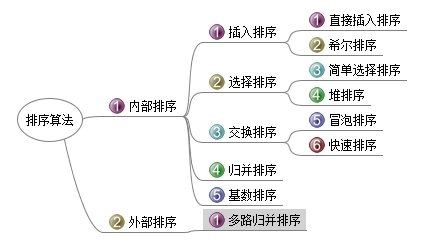
排序算法从功能上是对一个数据元素集合或序列重新排列成一个按数据元素某个相知有序的序列。从内存空间使用简单上看分为内部排序和外部排序。
内部排序是数据记录在内存中进行排序,适合不太大的元素序列。而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
排序算法稳定性是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。比如:Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就 是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,对基于比较的排序算法而言,元素交换 的次数可能会少一些。
插入排序―直接插入排序
基本算法:
每次从无序表中取出第一个元素,把它插入到前面已经排好序的子序列中的合适位置,使有序表仍然有序。即先将序列的第1个元素看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
直接插入排序示例:

直接插入排序有二种实现方式,带哨兵与不带哨兵。
带哨兵的插入排序中的哨兵元素有两个作用:
1、暂时存放待插入的元素,相当于临时存储元素。
2、可以防止数组下标越界,当待插入的元素小于已排序的子数组中的最小元素时,j=-1,越界,而采用哨兵,arr[0]<arr[j],当j=0时,就结束循环,不会出现越界(for循环只有一次判断,提高了效率)。
带哨兵需要注意一个问题:有方法传进来的数组时原始数组,则插入第一个元素时,a[0]会被覆盖,造成最终排完序的数组缺少了原始数组的第一个元素(bug)。
解决办法:在调用此方法之前,将数组做下处理,使其右移一个元素的位置,空出来的第0个元素初始化为0(或不做初始化)。
1、时间复杂度:O(n^2)
直接插入排序耗时的操作有:比较+后移赋值。时间复杂度如下:
1)最好情况:序列是升序排列,在这种情况下,需要进行的比较操作需(n-1)次。后移赋值操作为0次。即O(n)。
2)最坏情况:序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。后移赋值操作是比较操作的次数加上 (n-1)次。即O(n^2)。
3)渐进时间复杂度(平均时间复杂度):O(n^2)。
2、空间复杂度:O(1)
直接插入排序是在原输入数组上进行后移赋值操作的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
稳定性
直接插入排序是稳定的,不会改变相同元素的相对顺序。
算法优化:
二分查找插入排序的原理:是直接插入排序的一个变种,在有序区中查找新元素插入位置时,为了减少元素比较次数提高效率,采用二分查找算法进行插入位置的确定。
1、时间复杂度:O(n^2)
二分查找插入位置,因为不是查找相等值,而是基于比较查插入合适的位置,所以必须查到最后一个元素才知道插入位置。
二分查找最坏时间复杂度:当2^X>=n时,查询结束,所以查询的次数就为x,而x等于log2n(以2为底,n的对数),即O(log2n)。所以,二分查找排序比较次数为:x=log2n。
二分查找插入排序耗时的操作有:比较 + 后移赋值。时间复杂度如下:
1)最好情况:查找的位置是有序区的最后一位后面一位,则无须进行后移赋值操作,其比较次数为:log2n ,即O(log2n)。
2)最坏情况:查找的位置是有序区的第一个位置,则需要的比较次数为:log2n,需要的赋值操作次数为n(n-1)/2加上 (n-1) 次,即O(n^2)。
3)渐进时间复杂度(平均时间复杂度):O(n^2)。
2、空间复杂度:O(1)
二分查找插入排序是在原输入数组上进行后移赋值操作的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)。
稳定性
二分查找排序是稳定的,不会改变相同元素的相对顺序。
本文出自 “滴水穿石” 博客,请务必保留此出处http://honeybee.blog.51cto.com/9309920/1565692
排序算法从功能上是对一个数据元素集合或序列重新排列成一个按数据元素某个相知有序的序列。从内存空间使用简单上看分为内部排序和外部排序。
内部排序是数据记录在内存中进行排序,适合不太大的元素序列。而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
排序算法稳定性是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。比如:Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就 是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,对基于比较的排序算法而言,元素交换 的次数可能会少一些。
插入排序―直接插入排序
基本算法:
每次从无序表中取出第一个元素,把它插入到前面已经排好序的子序列中的合适位置,使有序表仍然有序。即先将序列的第1个元素看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
直接插入排序示例:
直接插入排序有二种实现方式,带哨兵与不带哨兵。
带哨兵的插入排序中的哨兵元素有两个作用:
1、暂时存放待插入的元素,相当于临时存储元素。
2、可以防止数组下标越界,当待插入的元素小于已排序的子数组中的最小元素时,j=-1,越界,而采用哨兵,arr[0]<arr[j],当j=0时,就结束循环,不会出现越界(for循环只有一次判断,提高了效率)。
带哨兵需要注意一个问题:有方法传进来的数组时原始数组,则插入第一个元素时,a[0]会被覆盖,造成最终排完序的数组缺少了原始数组的第一个元素(bug)。
解决办法:在调用此方法之前,将数组做下处理,使其右移一个元素的位置,空出来的第0个元素初始化为0(或不做初始化)。
/**
* 带哨所
*
* @param sortList
*/
public static void insertSort1(Integer[] sortList) {
int len = sortList.length;
for (int i = 2; i < len; i++) {
if (sortList[i] < sortList[i - 1]) {
int j = i - 1;
sortList[0] = sortList[i];// 设置哨所
while (sortList[0] < sortList[j]) {
sortList[j + 1] = sortList[j];
j--;
}
sortList[j + 1] = sortList[0];
}
}
}
/**
* 不带哨所
*
* @param sortList
*/
public static void insertSort2(Integer[] sortList) {
int len = sortList.length;
for (int i = 1; i < len; i++) {
if (sortList[i] < sortList[i - 1]) {
int j = i - 1;
int temp = sortList[i];
while (j >= 0 && temp < sortList[j]) {
sortList[j + 1] = sortList[j];
j--;
}
sortList[j + 1] = temp;
}
}
}算法复杂度1、时间复杂度:O(n^2)
直接插入排序耗时的操作有:比较+后移赋值。时间复杂度如下:
1)最好情况:序列是升序排列,在这种情况下,需要进行的比较操作需(n-1)次。后移赋值操作为0次。即O(n)。
2)最坏情况:序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。后移赋值操作是比较操作的次数加上 (n-1)次。即O(n^2)。
3)渐进时间复杂度(平均时间复杂度):O(n^2)。
2、空间复杂度:O(1)
直接插入排序是在原输入数组上进行后移赋值操作的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
稳定性
直接插入排序是稳定的,不会改变相同元素的相对顺序。
算法优化:
二分查找插入排序的原理:是直接插入排序的一个变种,在有序区中查找新元素插入位置时,为了减少元素比较次数提高效率,采用二分查找算法进行插入位置的确定。
/**
* 二分查找插入排序
* @param sortList
*/
public static void insertSort3(Integer[] sortList) {
int len = sortList.length;
for (int i = 1; i < len; i++) {
if (sortList[i] < sortList[i - 1]) {
//二分查找在有序区寻找插入的位置
int index = binarySearchIndex(sortList, i-1, sortList[i]);
if (i != index)
{
int temp = sortList[i];
// 后移元素,腾出arr[index]位置
for (int j = i - 1; j >= index; j--)
sortList[j + 1] = sortList[j];
// 将 arr[i] 放到正确位置上
sortList[index] = temp;
}
}
}
}
/**
* 二分查找要插入的位置得index
* @param sortList
* @param maxIndex
* @param data
* @return
*/
private static int binarySearchIndex(Integer[] sortList, int maxIndex, int data)
{
int iBegin = 0;
int iEnd = maxIndex;
int middle = -1;
while (iBegin <= iEnd)
{
middle = (iBegin + iEnd) / 2;
if (sortList[middle] > data)
{
iEnd = middle - 1;
}
else
{
iBegin = middle + 1;// 如果是相同元素,也是插入在后面的位置
}
}
return iBegin;
}算法复杂度1、时间复杂度:O(n^2)
二分查找插入位置,因为不是查找相等值,而是基于比较查插入合适的位置,所以必须查到最后一个元素才知道插入位置。
二分查找最坏时间复杂度:当2^X>=n时,查询结束,所以查询的次数就为x,而x等于log2n(以2为底,n的对数),即O(log2n)。所以,二分查找排序比较次数为:x=log2n。
二分查找插入排序耗时的操作有:比较 + 后移赋值。时间复杂度如下:
1)最好情况:查找的位置是有序区的最后一位后面一位,则无须进行后移赋值操作,其比较次数为:log2n ,即O(log2n)。
2)最坏情况:查找的位置是有序区的第一个位置,则需要的比较次数为:log2n,需要的赋值操作次数为n(n-1)/2加上 (n-1) 次,即O(n^2)。
3)渐进时间复杂度(平均时间复杂度):O(n^2)。
2、空间复杂度:O(1)
二分查找插入排序是在原输入数组上进行后移赋值操作的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)。
稳定性
二分查找排序是稳定的,不会改变相同元素的相对顺序。
本文出自 “滴水穿石” 博客,请务必保留此出处http://honeybee.blog.51cto.com/9309920/1565692

相关文章推荐
- 经典(java版)排序算法的分析及实现之一直接插入排序
- 经典(java版)排序算法的分析及实现之三简单选择排序
- 经典(java版)排序算法的分析及实现之二希尔排序
- 嵌入式系统上消息机制的实现(很经典的分析)
- 几种常用的排序算法的分析及java实现(希尔排序,堆排序,归并排序,快速排序,选择排序,插入排序,冒泡排序)
- Hadoop经典案例Spark实现(一)——通过采集的气象数据分析每年的最高温度
- 插入排序和归并排序实现以及时间复杂度分析
- 冒泡排序、选择排序、插入排序、快速排序算法的时间性能分析(java实现)
- JavaScript实现经典排序算法之插入排序
- 【经典算法】:基于中文字符分析的统计频率算法实现
- 【LeetCode-面试算法经典-Java实现】【147-Insertion Sort List(链表插入排序)】
- Java实现经典排序算法及复杂度稳定性分析
- Linux线程实现机制分析(绝对经典)
- 经典面试题分析之Google搜索之星(js实现)
- Hadoop经典案例Spark实现(一)——通过采集的气象数据分析每年的最高温度
- Java实现经典排序算法及复杂度稳定性分析
- 元素排序几种常用的排序算法的分析及java实现(希尔排序,堆排序,归并排序,快速排序,选择排序,插入排序,冒泡排序)
- 算法分析与设计——快排和插入排序的实现
- 经典面试题分析之归并排序的实现(js实现)
- 算法分析之插入排序——动态数组实现