java 的深拷贝浅拷贝
2014-10-13 10:22
106 查看
一、引言
对象拷贝(Object Copy)就是将一个对象的属性拷贝到另一个有着相同类类型的对象中去。在程序中拷贝对象是很常见的,主要是为了在新的上下文环境中复用对象的部分或全部数据。Java中有三种类型的对象拷贝:浅拷贝(Shallow Copy)、深拷贝(DeepCopy)、延迟拷贝(Lazy Copy)。
二、浅拷贝
1、什么是浅拷贝
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
在上图中,SourceObject有一个int类型的属性 "field1"和一个引用类型属性"refObj"(引用ContainedObject类型的对象)。当对SourceObject做浅拷贝时,创建了CopiedObject,它有一个包含"field1"拷贝值的属性"field2"以及仍指向refObj本身的引用。由于"field1"是基本类型,所以只是将它的值拷贝给"field2",但是由于"refObj"是一个引用类型,
所以CopiedObject指向"refObj"相同的地址。因此对SourceObject中的"refObj"所做的任何改变都会影响到CopiedObject。
2、如何实现浅拷贝
下面是实现浅拷贝的一个例子?
?
三、深拷贝
1、什么是深拷贝
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。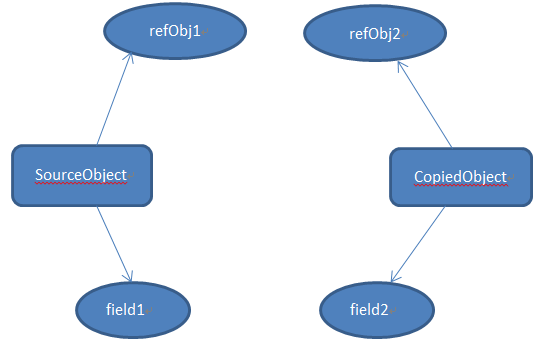
在上图中,SourceObject有一个int类型的属性 "field1"和一个引用类型属性"refObj1"(引用ContainedObject类型的对象)。当对SourceObject做深拷贝时,创建了CopiedObject,它有一个包含"field1"拷贝值的属性"field2"以及包含"refObj1"拷贝值的引用类型属性"refObj2" 。因此对SourceObject中的"refObj"所做的任何改变都不会影响到CopiedObject
2、如何实现深拷贝
下面是实现深拷贝的一个例子。只是在浅拷贝的例子上做了一点小改动,Subject 和CopyTest 类都没有变化。?
?
3、通过序列化实现深拷贝
也可以通过序列化来实现深拷贝。序列化是干什么的?它将整个对象图写入到一个持久化存储文件中并且当需要的时候把它读取回来, 这意味着当你需要把它读取回来时你需要整个对象图的一个拷贝。这就是当你深拷贝一个对象时真正需要的东西。请注意,当你通过序列化进行深拷贝时,必须确保对象图中所有类都是可序列化的。?
?
确保对象图中的所有类都是可序列化的
创建输入输出流
使用这个输入输出流来创建对象输入和对象输出流
将你想要拷贝的对象传递给对象输出流
从对象输入流中读取新的对象并且转换回你所发送的对象的类
在这个例子中,我创建了一个ColoredCircle对象c1然后将它序列化 (将它写到ByteArrayOutputStream中). 然后我反序列化这个序列化后的对象并将它保存到c2中。随后我修改了原始对象c1。然后结果如你所见,c1不同于c2,对c1所做的任何修改都不会影响c2。
注意,序列化这种方式有其自身的限制和问题:
因为无法序列化transient变量, 使用这种方法将无法拷贝transient变量。
再就是性能问题。创建一个socket, 序列化一个对象, 通过socket传输它, 然后反序列化它,这个过程与调用已有对象的方法相比是很慢的。所以在性能上会有天壤之别。如果性能对你的代码来说是至关重要的,建议不要使用这种方式。它比通过实现Clonable接口这种方式来进行深拷贝几乎多花100倍的时间。
四、延迟拷贝
延迟拷贝是浅拷贝和深拷贝的一个组合,实际上很少会使用。 当最开始拷贝一个对象时,会使用速度较快的浅拷贝,还会使用一个计数器来记录有多少对象共享这个数据。当程序想要修改原始的对象时,它会决定数据是否被共享(通过检查计数器)并根据需要进行深拷贝。延迟拷贝从外面看起来就是深拷贝,但是只要有可能它就会利用浅拷贝的速度。当原始对象中的引用不经常改变的时候可以使用延迟拷贝。由于存在计数器,效率下降很高,但只是常量级的开销。而且, 在某些情况下, 循环引用会导致一些问题。
五、如何选择
如果对象的属性全是基本类型的,那么可以使用浅拷贝,但是如果对象有引用属性,那就要基于具体的需求来选择浅拷贝还是深拷贝。我的意思是如果对象引用任何时候都不会被改变,那么没必要使用深拷贝,只需要使用浅拷贝就行了。如果对象引用经常改变,那么就要使用深拷贝。没有一成不变的规则,一切都取决于具体需求。

相关文章推荐
- java程序得到域名对应的所有IP地址(拷贝)
- java传递是引用的拷贝,既不是引用本身,更不是对象
- 怎样让java 的io 拷贝更加快一些
- JAVA程序保护方案(JAVA加密保护,防止反编译、防拷贝)
- 在java中用jxl拷贝、更新Excel工作薄
- java 一维和二维数组的拷贝问题
- Java实现文件拷贝的4种方法.
- java传递是引用的拷贝,既不是引用本身,更不是对象
- JAVA程序保护方案(防止反编译、防拷贝)
- Java中实现文件拷贝实例
- 通过JAVA的Serialization机制进行对象的拷贝
- java中的文件拷贝,移动
- 用java实现文件的拷贝
- JAVA 程序中如何拷贝一个目录下的文件及子目录到另一个目录,如何获取系统环境变量等...
- 如何用java拷贝本地文件夹
- 如何用java拷贝本地文件夹
- 一个Java版的目录拷贝程序
- Java实现文件拷贝(包括文件夹下的子文件夹和其中的文件)
- java递归实现文件的删除和拷贝
- Java实现分类文件拷贝1