Apache Hadoop 下一代的MapReduce(YARN)
2014-10-01 00:00
483 查看
原文链接
MapReduce已经在hadoop-0.23中经历了彻底的检修,现在,我们有了称之为MapReduce2.0(MRv2) 或者 YARN的新的框架。
MRv2基本的理念是将JobTracker中两个主要的功能(资源管理和作业调度/监控),拆分为单独的守护进程。想法就是有一个全局的ResourceMaager(RM)和对应每个应用的ApplicationMaster(AM)。一个Application是传统意义上的一个Map-Reduce 或者DAG 的作业。
ResourceManager和每台节点上从属的NodeManager(NM),构成了数据计算的框架。RM是最终权威仲裁系统资源在所有应用中(的分配)。
事实上,每个应用的ApplicationMaster 是一个用来向RM协商资源,与NodeManager(s)一起工作,执行和监控任务的特定框架库。
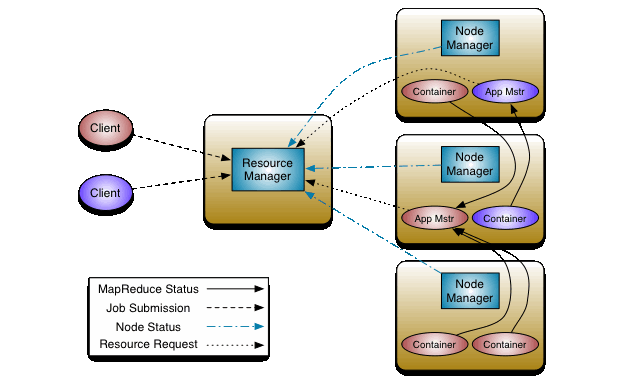
ResourceManager有两个重要的组件:Scheduler和ApplicationsManager。
Scheduler负责为各式各样运行中的应用分配受限制的资源,比如相似的约束,容量,队列等等。Scheduler就只是一个scheduler,不监控和跟踪应用的状态。还有,他不会保证重启那些由于应用失败或是硬件失败的任务。Scheduler基于applications的资源需求来执行他的调度功能;基于将memory、cpu、network、disk等元素合并进来的抽象概念--资源容器Container。在第一个版本中,只支持memory。
Scheduler有一个可插入策略的插件,负责在不同队列,应用间对集群的资源进行分区。当前Map-Reduce schedulers,比如CapacityScheduler,FairScheduler就是这个插件的一些例子。
CapacityScheduler顾及共享的集群资源更容易预测,支持分层级的队列。
ApplicationsManager负责接收任务的提交,协商第一个用来执行特定ApplicationMaster的容器,提供在(任务?)失败时重启ApplicationMaster容器的服务。
NodeManager是每台机器的代理框架,负责containers,监控他们(机器)的资源使用情况(cpu,memory,disk,network),同时报告给ResourceManager/Scheduler。
每个应用的ApplicationMaster负责与Scheduler协商合适的资源容器,并跟踪他们的状态,监控进展。
MRV2 兼容之前的稳定版本(hadoop-1.x),这意味着所愿的Map-Reduce jobs 只需要重统计一下就可以奔跑在MRV2之上了。
理解:YARN框架是建立在之前的Map-Reduce之上,将之前JobTracker的两个主要功能进行了拆分,分家,资源一家(RM老大),监控一家(NM,ApplicationMaster),各自分工明确。
RM又把他的活分派给了两个小头目(Scheduler,ApplicationsManager),job的接收就交给ApplicationsManager来做,job的调度就交给Scheduler,ApplicationsManager还要负责失败时重启ApplicationMaster,兼任多职啊。
监控的活也细分了,节点的情况(内存,CPU,硬盘,网络等)就由NM来负责监控并上报给领导(RM),再细点说,应该是上报给Scheduler小头目,这样他在调度的时候就会根据你这台节点的状态来分配任务。而每个应用的状态和进展,就交由各自的ApplicationMaster来监控了,如果ApplicationMaster挂了(任务?),没事,ApplicationsManager来帮你重启。
MapReduce已经在hadoop-0.23中经历了彻底的检修,现在,我们有了称之为MapReduce2.0(MRv2) 或者 YARN的新的框架。
MRv2基本的理念是将JobTracker中两个主要的功能(资源管理和作业调度/监控),拆分为单独的守护进程。想法就是有一个全局的ResourceMaager(RM)和对应每个应用的ApplicationMaster(AM)。一个Application是传统意义上的一个Map-Reduce 或者DAG 的作业。
ResourceManager和每台节点上从属的NodeManager(NM),构成了数据计算的框架。RM是最终权威仲裁系统资源在所有应用中(的分配)。
事实上,每个应用的ApplicationMaster 是一个用来向RM协商资源,与NodeManager(s)一起工作,执行和监控任务的特定框架库。

ResourceManager有两个重要的组件:Scheduler和ApplicationsManager。
Scheduler负责为各式各样运行中的应用分配受限制的资源,比如相似的约束,容量,队列等等。Scheduler就只是一个scheduler,不监控和跟踪应用的状态。还有,他不会保证重启那些由于应用失败或是硬件失败的任务。Scheduler基于applications的资源需求来执行他的调度功能;基于将memory、cpu、network、disk等元素合并进来的抽象概念--资源容器Container。在第一个版本中,只支持memory。
Scheduler有一个可插入策略的插件,负责在不同队列,应用间对集群的资源进行分区。当前Map-Reduce schedulers,比如CapacityScheduler,FairScheduler就是这个插件的一些例子。
CapacityScheduler顾及共享的集群资源更容易预测,支持分层级的队列。
ApplicationsManager负责接收任务的提交,协商第一个用来执行特定ApplicationMaster的容器,提供在(任务?)失败时重启ApplicationMaster容器的服务。
NodeManager是每台机器的代理框架,负责containers,监控他们(机器)的资源使用情况(cpu,memory,disk,network),同时报告给ResourceManager/Scheduler。
每个应用的ApplicationMaster负责与Scheduler协商合适的资源容器,并跟踪他们的状态,监控进展。
MRV2 兼容之前的稳定版本(hadoop-1.x),这意味着所愿的Map-Reduce jobs 只需要重统计一下就可以奔跑在MRV2之上了。
理解:YARN框架是建立在之前的Map-Reduce之上,将之前JobTracker的两个主要功能进行了拆分,分家,资源一家(RM老大),监控一家(NM,ApplicationMaster),各自分工明确。
RM又把他的活分派给了两个小头目(Scheduler,ApplicationsManager),job的接收就交给ApplicationsManager来做,job的调度就交给Scheduler,ApplicationsManager还要负责失败时重启ApplicationMaster,兼任多职啊。
监控的活也细分了,节点的情况(内存,CPU,硬盘,网络等)就由NM来负责监控并上报给领导(RM),再细点说,应该是上报给Scheduler小头目,这样他在调度的时候就会根据你这台节点的状态来分配任务。而每个应用的状态和进展,就交由各自的ApplicationMaster来监控了,如果ApplicationMaster挂了(任务?),没事,ApplicationsManager来帮你重启。

相关文章推荐
- YARN Apache Hadoop 的下一代MapReduce
- CDH 4.6 Apache Hadoop的下一代mapreduce,yarn
- Hadoop-2.2.0中文文档——Apache Hadoop 下一代 MapReduce (YARN)
- Apache Hadoop下一代MapReduce框架(YARN)简介 (Apache Hadoop NextGen MapReduce (YARN))
- 下一代Apache Hadoop MapReduce框架的架构
- org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService: mapreduce_shuffle do
- Apache Hadoop NextGen MapReduce (YARN)
- 下一代Apache Hadoop MapReduce框架的架构
- Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
- Apache Hadoop 0.23 MapReduce 2.0 (MRv2 or YARN) 介绍
- 下一代Apache Hadoop MapReduce框架的架构
- Apache Hadoop NextGen MapReduce (YARN) 2.6(翻译自官方)
- 下一代Apache Hadoop MapReduce框架的架构
- [译]下一代的Hadoop Mapreduce – 如何编写YARN应用程序
- 【hadoop 2学习】Hadoop下一代的MapReduce----YARN
- YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
- 从window中的eclipse中提交jar包到yarn框架运行,出现Exception from container-launch: org.apache.hadoop.util.Shell$
- Hadoop-2.2.0中文文档——MapReduce 下一代 -——集群配置