ML学习心得(4)----SVM支持向量机 之一
2014-09-11 14:53
281 查看
0、前言
网上有好多大神关于SVM的博客,在Reference中都有提及。而Andrew Ng从另外的角度引出了SVM,简单的
阐述了SVM的工作原理,具体的可以看看他的公开课。我这里打算1、介绍SVM和其dual优化;2、SVM和核函数以及
其松弛变量处理outliers;3、SMO算法。感觉工作量有些大,不知道自己能不能很清楚的理清自己的思路。
1、什么是Support Vector Machine(SVM)
SVM一直被认为是效果最好的现成可用的分类算法之一。这里"现成可用"几个字说的,其实是SVM在理论领域和实际应用
领域有很好效果,两边都混得开。那么到底什么是SVM呢?作为分类算法,我们当然要从线性分类器开始说起。
假设x是一个n维的数据,对应的类别y取值为{-1,1},我们希望有一个超平面,能够把不同类别的点全部都分割
开来,令
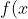=\omega&space;^{T}x+b)
,当f(x)=0的时候即为其分割超平面,当f(x)<0,y=-1,f(x)>0
y=1。然而,从数值的
角度上看,当f(x)值很小的时候,因为误差的存在,我们很难确保自己准确判断它所属的类别。那么很自然,我们希望
我们分类所依凭的f(x)的值能够足够大,大到我们很准确的进行分类;从几何的角度看,离超平面越近的点,我们越难
进行分类,反之 则相反。
我们定义function margin 为
=\omega&space;^{T}x+b)
(这里就体现出来我们y取+-1的好处了,可以保证距离是正的)
对于geometrical margin,我们可以从下面的图来看看

w是超平面的法向量,这点大家以前的知识应该就能理解,我们要求x点到超平面的距离:

而f(x0)=0,所以等式两边乘以w加b,可得:
}{\left&space;\|&space;\omega&space;\right&space;\|})
,为了保证他是正的乘以y,可得geometrical
margin为

两者差了||w||的倍数。
像上面提到的那样,我们希望我们的margin最大,那么我们的分类就更加准确,显然我们要找到的超平面
是最大化geometrical margin,因为function margin可以在超平面位置不变的情况下(同倍增大缩小w和b),导致
值不能确定,而几何距离就没这个问题。所以我们的svm就可以定义为:

\geq&space;\tilde{\gamma&space;})
固定function margin为1,那么我们的优化方程可以改为:

s.t.不变
至此,我们就初步的了解了什么是SVM,就是使得margin最大,使得我们分类的confidence最大,大家可以很明显
地看到,confidence的确定是依赖于几个f(x)绝对值等于1的点。下面我们就看看,怎么利用凸优化的知识求解这个问题。
2、SVM的求解——拉格朗日对偶问题
上面的等价的优化方程的拉格朗日函数为
&space;=&space;\frac{1}{2}\left&space;\|&space;\omega&space;\right&space;\|^{2}-\sum_{i=1}^{n}\alpha&space;_{i}(y_{i}(\omega^{T}x_{i}+b)&space;-1))
于是我们现在的目标函数变为:
=p^{*})
调换min和max可以得到
=d^{*})
我们可以得知d一定永远小于等于p,我们就可以利用其KKT条件求解。
KKT:
1、

2、

3、

为了求其极小值,我们求偏导可得

带入拉格朗日函数可以得到我们的对偶优化方程

上面整个的推导过程最好能自己去推导一下,便于加深记忆。
得到上面的式子,我们就有很好的方法SMO来求解,整个方法我们在后续的文章中会提及。
另外,我们来看看上述优化方程的某些特性吧。从而引出下篇文章核函数的内容
上面我们得到了w的表达式,带入拉格朗日函数,可以得到:
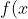&=\left(\sum_{i=1}^n\alpha_i&space;y_i&space;x_i\right)^Tx+b=&space;\sum_{i=1}^n\alpha_i&space;y_i&space;\langle&space;x_i,&space;x\rangle&space;+&space;b)
其中<x,y>表示内积。
让我们关注下alpha,从拉格朗日函数中,当我们的xi在边界上时,
-1\right)})
是为0的
也就是我们的support vector,那么不在边界上的点,其值是大于0的,而alpha有事大于等于0的,我们的拉格朗日函数
要使其最大化,若alpha不为0,那么其值就是正无穷的。所以不在边界上的点起alph的值时等于0的。也就是说我们的SVM
的边界其实就是几个support vector 所决定的
截止目前,我们的SVM只能针对线性分类。而基于上面内积的特点,我们下一章就会介绍到
核函数,从而使得我们的SVM更加强大。
3、Reference
Free Mind支持向量机系列
JerryLead支持向量机系列
网上有好多大神关于SVM的博客,在Reference中都有提及。而Andrew Ng从另外的角度引出了SVM,简单的
阐述了SVM的工作原理,具体的可以看看他的公开课。我这里打算1、介绍SVM和其dual优化;2、SVM和核函数以及
其松弛变量处理outliers;3、SMO算法。感觉工作量有些大,不知道自己能不能很清楚的理清自己的思路。
1、什么是Support Vector Machine(SVM)
SVM一直被认为是效果最好的现成可用的分类算法之一。这里"现成可用"几个字说的,其实是SVM在理论领域和实际应用
领域有很好效果,两边都混得开。那么到底什么是SVM呢?作为分类算法,我们当然要从线性分类器开始说起。
假设x是一个n维的数据,对应的类别y取值为{-1,1},我们希望有一个超平面,能够把不同类别的点全部都分割
开来,令
,当f(x)=0的时候即为其分割超平面,当f(x)<0,y=-1,f(x)>0
y=1。然而,从数值的
角度上看,当f(x)值很小的时候,因为误差的存在,我们很难确保自己准确判断它所属的类别。那么很自然,我们希望
我们分类所依凭的f(x)的值能够足够大,大到我们很准确的进行分类;从几何的角度看,离超平面越近的点,我们越难
进行分类,反之 则相反。
我们定义function margin 为
(这里就体现出来我们y取+-1的好处了,可以保证距离是正的)
对于geometrical margin,我们可以从下面的图来看看
w是超平面的法向量,这点大家以前的知识应该就能理解,我们要求x点到超平面的距离:
而f(x0)=0,所以等式两边乘以w加b,可得:
,为了保证他是正的乘以y,可得geometrical
margin为
两者差了||w||的倍数。
像上面提到的那样,我们希望我们的margin最大,那么我们的分类就更加准确,显然我们要找到的超平面
是最大化geometrical margin,因为function margin可以在超平面位置不变的情况下(同倍增大缩小w和b),导致
值不能确定,而几何距离就没这个问题。所以我们的svm就可以定义为:
固定function margin为1,那么我们的优化方程可以改为:
s.t.不变
至此,我们就初步的了解了什么是SVM,就是使得margin最大,使得我们分类的confidence最大,大家可以很明显
地看到,confidence的确定是依赖于几个f(x)绝对值等于1的点。下面我们就看看,怎么利用凸优化的知识求解这个问题。
2、SVM的求解——拉格朗日对偶问题
上面的等价的优化方程的拉格朗日函数为
于是我们现在的目标函数变为:
调换min和max可以得到
我们可以得知d一定永远小于等于p,我们就可以利用其KKT条件求解。
KKT:
1、
2、
3、
为了求其极小值,我们求偏导可得
带入拉格朗日函数可以得到我们的对偶优化方程
上面整个的推导过程最好能自己去推导一下,便于加深记忆。
得到上面的式子,我们就有很好的方法SMO来求解,整个方法我们在后续的文章中会提及。
另外,我们来看看上述优化方程的某些特性吧。从而引出下篇文章核函数的内容
上面我们得到了w的表达式,带入拉格朗日函数,可以得到:
其中<x,y>表示内积。
让我们关注下alpha,从拉格朗日函数中,当我们的xi在边界上时,
是为0的
也就是我们的support vector,那么不在边界上的点,其值是大于0的,而alpha有事大于等于0的,我们的拉格朗日函数
要使其最大化,若alpha不为0,那么其值就是正无穷的。所以不在边界上的点起alph的值时等于0的。也就是说我们的SVM
的边界其实就是几个support vector 所决定的
截止目前,我们的SVM只能针对线性分类。而基于上面内积的特点,我们下一章就会介绍到
核函数,从而使得我们的SVM更加强大。
3、Reference
Free Mind支持向量机系列
JerryLead支持向量机系列

相关文章推荐
- ML学习心得(4)----SVM支持向量机 之二
- SVM百家争鸣之针对大规模训练集的支持向量机的学习策略
- 转:SVM与SVR支持向量机原理学习与思考(一)
- SVM(支持向量机)---学习和理解
- 机器学习(十三)学习SVM支持向量机的直观感受
- Coursera_Stanford_ML_ex6_支持向量机(SVM) 作业记录
- SVM学习之五——支持向量机的原理 - 叶子 - 语言技术网 自然语言处理|信息检索|人工智能 - Powered by X-Space
- 深入浅出机器学习之支持向量机SVM(SMO算法)
- SVM-SVC学习心得
- 支持向量机(SVM)相关免费学习视频集锦
- 在opencv3中实现机器学习之:利用svm(支持向量机)分类
- Stanford机器学习---第八讲. 支持向量机SVM
- ML学习心得(3)---- Logistic Regression & Regularization
- ML学习心得(1)--- 贝叶斯理论思想
- 支持向量机SVM学习
- 支持向量机(Support Vector Machines SVM)基础学习
- 学习支持向量机SVM及其代码
- SVM支持向量机学习
- Stanford机器学习---第八讲. 支持向量机SVM
- 我的OpenCV学习笔记(六):使用支持向量机(SVM)