ROC Curve
2014-08-28 16:05
537 查看
(from Wiki)
To understand the Curve of ROC in the Classification.
ROC曲線
receiver operating characteristic curve,或者叫ROC曲線
分类模型(又称分类器,或诊断)是将一个实例映射到一个特定类的过程。ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,例如:(阳性/阴性)(有病/没病)(垃圾邮件/非垃圾邮件)(敌军/非敌军)。
当讯号侦侧(或变量测量)的结果是一个连续值时,类与类的边界必须用一个阈值(英语:threshold)来界定。举例来说,用血压值来检测一个人是否有高血压,测出的血压值是连续的实数(从0~200都有可能),以收缩压140/舒张压90为阈值,阈值以上便诊断为有高血压,阈值未满者诊断为无高血压。二元分类模型的个案预测有四种结局:
真阳性(TP):诊断为有,实际上也有高血压。
伪阳性(FP):诊断为有,实际却没有高血压。
真阴性(TN):诊断为没有,实际上也没有高血压。
伪阴性(FN):诊断为没有,实际却有高血压。
这四种结局可以画成2 × 2的Confusion
matrix:

ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。

FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。

给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实值和预测值计算出一个 (
4000
X=FPR, Y=TPR) 座标点。
从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0
代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从
(0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
让我们来看在实际有100个阳性和100个阴性的案例时,四种预测方法(可能是四种分类器,或是同一分类器的四种阈值设定)的结果差异:
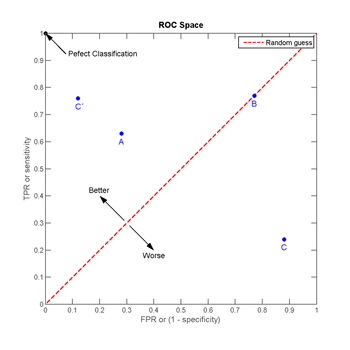

ROC空间的4个例子
将这4种结果画在ROC空间里:
点与随机猜测线的距离,是预测力的指标:离左上角越近的点预测(诊断)准确率越高。离右下角越近的点,预测越不准。
在A、B、C三者当中,最好的结果是A方法。
B方法的结果位于随机猜测线(对角线)上,在例子中我们可以看到B的准确度(ACC,定义见前面表格)是50%。
C虽然预测准确度最差,甚至劣于随机分类,也就是低于0.5(低于对角线)。然而,当将C以 (0.5, 0.5) 为中点作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单说,不管C(或任何ROC点低于对角线的情况)预测了什么,就做相反的结论。
术语
To understand the Curve of ROC in the Classification.
ROC曲線
receiver operating characteristic curve,或者叫ROC曲線
分类模型(又称分类器,或诊断)是将一个实例映射到一个特定类的过程。ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,例如:(阳性/阴性)(有病/没病)(垃圾邮件/非垃圾邮件)(敌军/非敌军)。
当讯号侦侧(或变量测量)的结果是一个连续值时,类与类的边界必须用一个阈值(英语:threshold)来界定。举例来说,用血压值来检测一个人是否有高血压,测出的血压值是连续的实数(从0~200都有可能),以收缩压140/舒张压90为阈值,阈值以上便诊断为有高血压,阈值未满者诊断为无高血压。二元分类模型的个案预测有四种结局:
真阳性(TP):诊断为有,实际上也有高血压。
伪阳性(FP):诊断为有,实际却没有高血压。
真阴性(TN):诊断为没有,实际上也没有高血压。
伪阴性(FN):诊断为没有,实际却有高血压。
这四种结局可以画成2 × 2的Confusion
matrix:
ROC空间
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。
给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实值和预测值计算出一个 (
4000
X=FPR, Y=TPR) 座标点。
从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0
代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从
(0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
让我们来看在实际有100个阳性和100个阴性的案例时,四种预测方法(可能是四种分类器,或是同一分类器的四种阈值设定)的结果差异:
| A | B | C | C' | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
| ||||||||||||||||||||||||||||||||||||
| TPR = 0.63 | TPR = 0.77 | TPR = 0.24 | TPR = 0.76 | ||||||||||||||||||||||||||||||||||||
| FPR = 0.28 | FPR = 0.77 | FPR = 0.88 | FPR = 0.12 | ||||||||||||||||||||||||||||||||||||
| ACC = 0.68 | ACC = 0.50 | ACC = 0.18 | ACC = 0.82 |

ROC空间的4个例子
将这4种结果画在ROC空间里:
点与随机猜测线的距离,是预测力的指标:离左上角越近的点预测(诊断)准确率越高。离右下角越近的点,预测越不准。
在A、B、C三者当中,最好的结果是A方法。
B方法的结果位于随机猜测线(对角线)上,在例子中我们可以看到B的准确度(ACC,定义见前面表格)是50%。
C虽然预测准确度最差,甚至劣于随机分类,也就是低于0.5(低于对角线)。然而,当将C以 (0.5, 0.5) 为中点作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单说,不管C(或任何ROC点低于对角线的情况)预测了什么,就做相反的结论。
| 阳性 (P, positive)阴性 (N, Negative)真阳性 (TP, true positive) 正确的肯定。又称:命中 (hit)真阴性 (TN, true negative) 正确的否定。又称:正确拒绝 (correct rejection)伪阳性 (FP, false positive) 错误的肯定,又称:假警报 (false alarm),第一型错误伪阴性 (FN, false negative) 错误的否定,又称:未命中 (miss),第二型错误真阳性率 (TPR, true positive rate) 又称:命中率 (hit rate) TPR = TP / P = TP / (TP+FN)伪阳性率(FPR, false positive rate) 又称:错误命中率,假警报率 (false alarm rate) FPR = FP / N = FP / (FP + TN)准确度 (ACC, accuracy) ACC = (TP + TN) / (P + N) 即:(真阳性+真阴性) / 总样本数真阴性率 (TNR) 又称:特异度 (SPC, specificity) SPC = TN / N = TN / (FP + TN) = 1 - FPR阳性预测值 (PPV) PPV = TP / (TP + FP)阴性预测值 (NPV) NPV = TN / (TN + FN)假发现率 (FDR) FDR = FP / (FP + TP)Matthews相关系数 (MCC),即 Phi相关系数 MCC = (TP*TN - FP*FN) / \sqrt{P N P' N'}F1评分 F1 = 2TP/(P+P') |
| Source: Fawcett (2006). |

相关文章推荐
- Beijing Invees Network Science And Technology Co.,Ltd
- 模板匹配
- Web数据挖掘综述
- (转载)机器学习方法的PPT
- 数字图像处理词汇表
- 大学英语四级词汇
- ILM帮助金融用户实现全局规划
- a personality that people admire
- 数据挖掘相关知识(本人原创,转载注明)
- 迁移学习
- 机器学习总结
- Pacific Timesheet Named to American Top Business List
- java调用weka
- 利用Rational XDE中模式的能力来促进软件的重用
- 杜威十进分类法
- Chu-Ren Huang 黃 居 仁(computational linguistics)
- 罗列各种spider
- 软件质量2010年: 关于现有软件技术状况的调查(U.S)
- 通过表取物料特性值
- 计算机系英语自我介绍范本