【c++】——sizeof与字节对齐
2014-08-13 15:55
218 查看
http://www.cnblogs.com/dolphin0520/archive/2011/09/17/2179466.html
结构体字节对齐
在用sizeof运算符求算某结构体所占空间时,并不是简单地将结构体中所有元素各自占的空间相加,这里涉及到内存字节对齐的问题。从理论上讲,对于任何变量的访问都可以从任何地址开始访问,但是事实上不是如此,实际上访问特定类型的变量只能在特定的地址访问,这就需要各个变量在空间上按一定的规则排列,而不是简单地顺序排列,这就是内存对齐。
内存对齐的原因:
1)某些平台只能在特定的地址处访问特定类型的数据;
2)提高存取数据的速度。比如有的平台每次都是从偶地址处读取数据,对于一个int型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量;但是若从奇地址单元处存放,则需要2个读取周期读取该变量。
在C99标准中,对于内存对齐的细节没有作过多的描述,具体的实现交由编译器去处理,所以在不同的编译环境下,内存对齐可能略有不同,但是对齐的最基本原则是一致的,对于结构体的字节对齐主要有下面两点:
1)结构体每个成员相对结构体首地址的偏移量(offset)是对齐参数的整数倍,如有需要会在成员之间填充字节。编译器在为结构体成员开辟空间时,首先检查预开辟空间的地址相对于结构体首地址的偏移量是否为对齐参数的整数倍,若是,则存放该成员;若不是,则填充若干字节,以达到整数倍的要求。
2)结构体变量所占空间的大小是对齐参数大小的整数倍。如有需要会在最后一个成员末尾填充若干字节使得所占空间大小是对齐参数大小的整数倍。
注意:在看这两条原则之前,先了解一下对齐参数这个概念。对于每个变量,它自身有对齐参数,这个自身对齐参数在不同编译环境下不同。下面列举的是两种最常见的编译环境下各种类型变量的自身对齐参数

从上面可以发现,在windows(32)/VC6.0下各种类型的变量的自身对齐参数就是该类型变量所占字节数的大小,而在linux(32)/GCC下double类型的变量自身对齐参数是4,是因为linux(32)/GCC下如果该类型变量的长度没有超过CPU的字长,则以该类型变量的长度作为自身对齐参数,如果该类型变量的长度超过CPU字长,则自身对齐参数为CPU字长,而32位系统其CPU字长是4,所以linux(32)/GCC下double类型的变量自身对齐参数是4,如果是在Linux(64)下,则double类型的自身对齐参数是8。
除了变量的自身对齐参数外,还有一个对齐参数,就是每个编译器默认的对齐参数#pragma pack(n),这个值可以通过代码去设定,如果没有设定,则取系统的默认值。在windows(32)/VC6.0下,n的取值可以为1、2、4、8,默认情况下为8。在linux(32)/GCC下,n的取值只能为1、2、4,默认情况下为4。注意像DEV-CPP、MinGW等在windows下n的取值和VC的相同。
了解了这2个概念之后,可以理解上面2条原则了。对于第一条原则,每个变量相对于结构体的首地址的偏移量必须是对齐参数的整数倍,这句话中的对齐参数是取每个变量自身对齐参数和系统默认对齐参数#pragma pack(n)中较小的一个。举个简单的例子,比如在结构体A中有变量int a,a的自身对齐参数为4(环境为windows/vc),而VC默认的对齐参数为8,取较小者,则对于a,它相对于结构体A的起始地址的偏移量必须是4的倍数。
对于第二条原则,结构体变量所占空间的大小是对齐参数的整数倍。这句话中的对齐参数有点复杂,它是取结构体中所有变量的对齐参数的最大值和系统默认对齐参数#pragma pack(n)比较,较小者作为对齐参数。举个例子假如在结构体A中先后定义了两个变量int a;double b;对于变量a,它的自身对齐参数为4,而#pragma pack(n)值默认为8,则a的对齐参数为4;b的自身对齐参数为8,而#pragma pack(n)的默认值为8,则b的对齐参数为8。由于a的最终对齐参数为4,b的最终对齐参数为8,那么两者较大者是8,然后再拿8和#pragma
pack(n)作比较,取较小者作为对齐参数,也就是8,即意味着结构体最终的大小必须能被8整除。
下面是测试例子:
注意:以下例子的测试结果均在windows(32)/VC下测试的,其默认对齐参数为8

下面解释一下其中的几个结构体字节分配的情况
比如对于node2
sizeof(S2)=12;
对于变量a,它的自身对齐参数为1,#pragma pack(n)默认值为8,则最终a的对齐参数为1,为其分配1字节的空间,它相对于结构体起始地址的偏移量为0,能被4整除;
对于变量b,它的自身对齐参数为4,#pragma pack(n)默认值为8,则最终b的对齐参数为4,接下来的地址相对于结构体的起始地址的偏移量为1,1不能够整除4,所以需要在a后面填充3字节使得偏移量达到4,然后再为b分配4字节的空间;
对于变量c,它的自身对齐参数为2,#pragma pack(n)默认值为8,则最终c的对齐参数为2,而接下来的地址相对于结构体的起始地址的偏移量为8,能整除2,所以直接为c分配2字节的空间。
此时结构体所占的字节数为1+3+4+2=10字节
最后由于a,b,c的最终对齐参数分别为1,4,2,最大为4,#pragma pack(n)的默认值为8,则结构体变量最后的大小必须能被4整除。而10不能够整除4,所以需要在后面填充2字节达到12字节。其存储如下:
|char|----|----|----| 4字节
|--------int--------| 4字节
|--short--|----|----| 4字节
总共占12个字节
对于node3,含有静态数据成员
则sizeof(S3)=8.这里结构体中包含静态数据成员,而静态数据成员的存放位置与结构体实例的存储地址无关(注意只有在C++中结构体中才能含有静态数据成员,而C中结构体中是不允许含有静态数据成员的)。其在内存中存储方式如下:
|--------int--------| 4字节
|--short-|----|----| 4字节
而变量c是单独存放在静态数据区的,因此用siezof计算其大小时没有将c所占的空间计算进来。
而对于node5,里面含有结构体变量
sizeof(S5)=32。
对于变量a,其自身对齐参数为1,#pragma pack(n)为8,则a的最终对齐参数为1,为它分配1字节的空间,它相对于结构体起始地址的偏移量为0,能被1整除;
对于s1,它的自身对齐参数为4(对于结构体变量,它的自身对齐参数为它里面各个变量最终对齐参数的最大值),#pragma pack(n)为8,所以s1的最终对齐参数为4,接下来的地址相对于结构体起始地址的偏移量为1,不能被4整除,所以需要在a后面填充3字节达到4,为其分配8字节的空间;
对于变量b,它的自身对齐参数为8,#pragma pack(n)的默认值为8,则b的最终对齐参数为8,接下来的地址相对于结构体起始地址的偏移量为12,不能被8整除,所以需要在s1后面填充4字节达到16,再为b分配8字节的空间;
对于变量c,它的自身对齐参数为4,#pragma pack(n)的默认值为8,则c的最终对齐参数为4,接下来相对于结构体其实地址的偏移量为24,能够被4整除,所以直接为c分配4字节的空间。
此时结构体所占字节数为1+3+8+4+8+4=28字节。
对于整个结构体来说,各个变量的最终对齐参数为1,4,8,4,最大值为8,#pragma pack(n)默认值为8,所以最终结构体的大小必须是8的倍数,因此需要在最后面填充4字节达到32字节。其存储如下:
|--------bool--------| 4字节
|---------s1---------| 8字节
|--------------------| 4字节
|--------double------| 8字节
|----int----|---------| 8字节
另外可以显示地在程序中使用#pragma pack(n)来设置系统默认的对齐参数,在显示设置之后,则以设置的值作为标准,其它的和上面所讲的类似,就不再赘述了,读者可以自行上机试验一下。如果需要取消设置,可以用#pragma pack()来取消。
/article/2052894.html
先看一个空的类占多少空间?
[cpp] view
plaincopy
class Base
{
public:
Base();
~Base();
};
注意到我这里显示声明了构造跟析构,但是sizeof(Base)的结果是1.
因为一个空类也要实例化,所谓类的实例化就是在内存中分配一块地址,每个实例在内存中都有独一无二的地址。同样空类也会被实例化,所以编译器会给空类隐含的添加一个字节,这样空类实例化之后就有了独一无二的地址了。所以空类的sizeof为1。
而析构函数,跟构造函数这些成员函数,是跟sizeof无关的,也不难理解因为我们的sizeof是针对实例,而普通成员函数,是针对类体的,一个类的成员函数,多个实例也共用相同的函数指针,所以自然不能归为实例的大小,这在我的另一篇博文有提到。
接着看下面一段代码
[cpp] view
plaincopy
class Base
{
public:
Base();
virtual ~Base(); //每个实例都有虚函数表
void set_num(int num) //普通成员函数,为各实例公有,不归入sizeof统计
{
a=num;
}
private:
int a; //占4字节
char *p; //4字节指针
};
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
private:
static int st; //非实例独占
int d; //占4字节
char *p; //4字节指针
};
int main()
{
cout<<sizeof(Base)<<endl;
cout<<sizeof(Derive)<<endl;
return 0;
}
结果自然是
12
20
Base类里的int a;char *p;占8个字节。
而虚析构函数virtual ~Base();的指针占4子字节。
其他成员函数不归入sizeof统计。
Derive类首先要具有Base类的部分,也就是占12字节。
int d;char *p;占8字节
static int st;不归入sizeof统计
所以一共是20字节。
在考虑在Derive里加一个成员char c;
[cpp] view
plaincopy
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
private:
static int st;
int d;
char *p;
char c;
};
这个时候,结果就变成了
12
24
一个char c;增加了4字节,说明类的大小也遵守类似class字节对齐,的补齐规则。
具体的可以看我那篇《5分钟搞定字节对齐》
至此,我们可以归纳以下几个原则:
1.类的大小为类的非静态成员数据的类型大小之和,也就是说静态成员数据不作考虑。
2.普通成员函数与sizeof无关。
3.虚函数由于要维护在虚函数表,所以要占据一个指针大小,也就是4字节。
4.类的总大小也遵守类似class字节对齐的,调整规则。
上一篇文章研究了关于类大小的4条规则后,我们再结合虚函数表,来研究下类的大小。
[cpp] view
plaincopy
class Base
{
public:
Base(){};
virtual ~Base(){};
void set_num(int num)
{
a=num;
}
virtual int get_num()
{
return a;
}
private:
int a;
char *p;
};
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
virtual int get_num()
{
return d;
}
private:
static int st;
int d;
char *p;
char c;
};
int main()
{
cout<<sizeof(Base)<<endl;
cout<<sizeof(Derive)<<endl;
return 0;
}
在Base类里添加了virtual int get_num()函数,而子类也重新实现了virtual int get_num()函数。
但是结果依然是
12
24
说明子类只是共用父类的虚函数表,因此一旦父类里有虚函数,子类的虚函数将不计入sizeof大小。
这可以认为是一个补充规则。
http://www.cnblogs.com/BeyondTechnology/archive/2010/09/21/1832369.html
类的sizeof大小一般是类中的所有成员的sizeof大小之和,这个就不用多说。
不过有两点需要注意:1)当类中含有虚成员函数的时候,例如:
class B
{
float a;
public:
virtual void fun(void);
}
此时sizeof(B)的大小为8,而不是4。因为在类中隐藏了一个指针,该指针指向虚函数表,正因为如此,
使得C++能够支持多态,即在运行时绑定函数的地址。
2)另一个要注意的是,当类中没有任何成员变量,也没有虚函数的时候,该类的大小是多少呢?
例如:
class B2
{
void fun(void);
}
此时sizeof(B2)的值是多少呢?在C++早期的编译器中,这个值为0;然而当创建这样的对象时,
它们与紧接着它们后面的对象有相同的地址。比如:
B2 b2;
int a;
那么对象b2与变量a有相同的地址,这样的话对对象b2地址的操作就会影响变量a。所以在现在大多数编译器中,该值的大小为1。
如果有虚函数,则sizeof值为类的数据成员的大小加上VTBL(指针,4字节),再加上其基类的数据成员的大小。如果是多重继承,还得加上各基类的VTBL。
虚继承之单继承的内存布局
先看一段代码
class A
{
virtual aa(){};
};
class B : public virtual A
{
char j[3]; //加入一个变量是为了看清楚class中的vfptr放在什么位置
public:
virtual bb(){};
};
class C : public virtual B
{
char i[3];
public:
virtual cc(){};
};
这次先不给结果,先分析一下,也好加强一下印象。
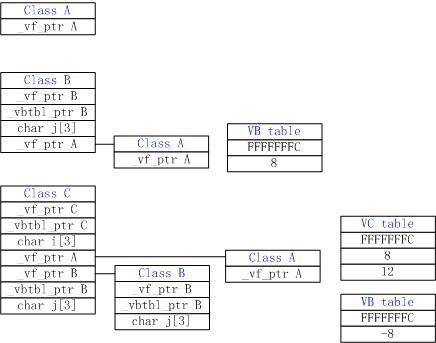
1、对于class A,由于只有一个虚函数,那么必须得有一个对应的虚函数表,来记录对应的函数入口地址。同时在class A的内存空间中之需要有个vfptr_A指向该表。sizeof(A)也很容易确定,为4。
2、对于class B,由于class B虚基础了class A,同时还拥有自己的虚函数。那么class B中首先拥有一个vfptr_B,指向自己的虚函数表。还有char j[3],做一次alignment,一般大小为4。可虚继承该如何实现咧?首先要通过加入一个虚l类指针(记vbptr_B_A)来指向其父类,然后还要包含父类的所有内容。有些复杂了,不过还不难想象。sizeof(B)= 4+4+4+4=16(vfptr_B、char j[3]做alignment、vbptr_B_A和class A)。
3、在接着是class C了。class C首先也得有个vfptr_C,然后是char i[3],然后是vbptr_C_B,然后是class B,所以sizeof(C)=4+4+4+16=28(vfptr_C、char i[3]做alignment、vbptr_C_A和class B)。
在VC 6.0下写了个程序,把上面几个类的大小打印出来,果然结果为4、16、28。
VC中虚继承的内存布局——单继承
画了个图,简单表示一下我跟踪后的结果
虚基础之单继承时的内存布局图
class A的情况太简单,没问题。从class B的内存布局图可以得出下面的结论。
1、vf_ptr B放在了类的首部,那么如果要想直接拿memcpy完成类的复制是很危险的,用struct也是不行的。
2、vbtbl_ptr_B,为什么不是先前我描述的vbptr_B_A呢?因为这个指针与我先前猜测的内容有很大区别。这个指针指向的是class B的虚类表。看看VB table,VB table有两项,第一项为FFFFFFFC,这一项的值可能没啥意义,可能是为了保证虚类表不为空吧。第二项为8,看起来像是class B中的class A相对该vbtbl_ptr_B的位移,也就是一个offset。类似的方法在C++ Object Model(P121)有介绍,可以去看看。
class C的内存布局就比较复杂了,不过它的内存布局也更一步说明我对vbtbl_ptr_B中的内容,也就是虚类表的理解是正确的。不过值得关注的是class B中的class A在布局时被移到前面去了,虽然整个大小没变,但这样一来如果做这样的操作 C c; B *b;b=&c;时b的操作如何呢?此时只要从c的虚类表里获得class B的位置既可赋值给b。但是在构建class C时会复杂一些,后面的使用还是非常简单的,效率也比较高。class A的内存布局被前移可能是考虑倒C的虚继承顺序吧。
结论
1、VC在编译时会把vfptr放到类的头部;
2、VC采用虚表指针(vbtbl_ptr)来确定某个类所继承的虚类。
3、VC会重新调整虚继承的父类在子类中内存布局。(具体规则还不清楚)
4、VC中虚类表中的第一项是无意义的,可能是为了保证sizeof(虚类表)!=0;后面的内容为父类在子类中相对该虚类表指针的偏移量。
结构体字节对齐
在用sizeof运算符求算某结构体所占空间时,并不是简单地将结构体中所有元素各自占的空间相加,这里涉及到内存字节对齐的问题。从理论上讲,对于任何变量的访问都可以从任何地址开始访问,但是事实上不是如此,实际上访问特定类型的变量只能在特定的地址访问,这就需要各个变量在空间上按一定的规则排列,而不是简单地顺序排列,这就是内存对齐。
内存对齐的原因:
1)某些平台只能在特定的地址处访问特定类型的数据;
2)提高存取数据的速度。比如有的平台每次都是从偶地址处读取数据,对于一个int型的变量,若从偶地址单元处存放,则只需一个读取周期即可读取该变量;但是若从奇地址单元处存放,则需要2个读取周期读取该变量。
在C99标准中,对于内存对齐的细节没有作过多的描述,具体的实现交由编译器去处理,所以在不同的编译环境下,内存对齐可能略有不同,但是对齐的最基本原则是一致的,对于结构体的字节对齐主要有下面两点:
1)结构体每个成员相对结构体首地址的偏移量(offset)是对齐参数的整数倍,如有需要会在成员之间填充字节。编译器在为结构体成员开辟空间时,首先检查预开辟空间的地址相对于结构体首地址的偏移量是否为对齐参数的整数倍,若是,则存放该成员;若不是,则填充若干字节,以达到整数倍的要求。
2)结构体变量所占空间的大小是对齐参数大小的整数倍。如有需要会在最后一个成员末尾填充若干字节使得所占空间大小是对齐参数大小的整数倍。
注意:在看这两条原则之前,先了解一下对齐参数这个概念。对于每个变量,它自身有对齐参数,这个自身对齐参数在不同编译环境下不同。下面列举的是两种最常见的编译环境下各种类型变量的自身对齐参数
从上面可以发现,在windows(32)/VC6.0下各种类型的变量的自身对齐参数就是该类型变量所占字节数的大小,而在linux(32)/GCC下double类型的变量自身对齐参数是4,是因为linux(32)/GCC下如果该类型变量的长度没有超过CPU的字长,则以该类型变量的长度作为自身对齐参数,如果该类型变量的长度超过CPU字长,则自身对齐参数为CPU字长,而32位系统其CPU字长是4,所以linux(32)/GCC下double类型的变量自身对齐参数是4,如果是在Linux(64)下,则double类型的自身对齐参数是8。
除了变量的自身对齐参数外,还有一个对齐参数,就是每个编译器默认的对齐参数#pragma pack(n),这个值可以通过代码去设定,如果没有设定,则取系统的默认值。在windows(32)/VC6.0下,n的取值可以为1、2、4、8,默认情况下为8。在linux(32)/GCC下,n的取值只能为1、2、4,默认情况下为4。注意像DEV-CPP、MinGW等在windows下n的取值和VC的相同。
了解了这2个概念之后,可以理解上面2条原则了。对于第一条原则,每个变量相对于结构体的首地址的偏移量必须是对齐参数的整数倍,这句话中的对齐参数是取每个变量自身对齐参数和系统默认对齐参数#pragma pack(n)中较小的一个。举个简单的例子,比如在结构体A中有变量int a,a的自身对齐参数为4(环境为windows/vc),而VC默认的对齐参数为8,取较小者,则对于a,它相对于结构体A的起始地址的偏移量必须是4的倍数。
对于第二条原则,结构体变量所占空间的大小是对齐参数的整数倍。这句话中的对齐参数有点复杂,它是取结构体中所有变量的对齐参数的最大值和系统默认对齐参数#pragma pack(n)比较,较小者作为对齐参数。举个例子假如在结构体A中先后定义了两个变量int a;double b;对于变量a,它的自身对齐参数为4,而#pragma pack(n)值默认为8,则a的对齐参数为4;b的自身对齐参数为8,而#pragma pack(n)的默认值为8,则b的对齐参数为8。由于a的最终对齐参数为4,b的最终对齐参数为8,那么两者较大者是8,然后再拿8和#pragma
pack(n)作比较,取较小者作为对齐参数,也就是8,即意味着结构体最终的大小必须能被8整除。
下面是测试例子:
注意:以下例子的测试结果均在windows(32)/VC下测试的,其默认对齐参数为8
/*测试sizeof运算符 2011.10.1*/
#include <iostream>
using namespace std;
//#pragma pack(4) //设置4字节对齐
//#pragma pack() //取消4字节对齐
typedef struct node1
{
int a;
char b;
short c;
}S1;
typedef struct node2
{
char a;
int b;
short c;
}S2;
typedef struct node3
{
int a;
short b;
static int c;
}S3;
typedef struct node4
{
bool a;
S1 s1;
short b;
}S4;
typedef struct node5
{
bool a;
S1 s1;
double b;
int c;
}S5;
int main(int argc, char *argv[])
{
cout<<sizeof(char)<<" "<<sizeof(short)<<" "<<sizeof(int)<<" "<<sizeof(float)<<" "<<sizeof(double)<<endl;
S1 s1;
S2 s2;
S3 s3;
S4 s4;
S5 s5;
cout<<sizeof(s1)<<" "<<sizeof(s2)<<" "<<sizeof(s3)<<" "<<sizeof(s4)<<" "<<sizeof(s5)<<endl;
return 0;
}下面解释一下其中的几个结构体字节分配的情况
比如对于node2
typedef struct node2
{
char a;
int b;
short c;
}S2;sizeof(S2)=12;
对于变量a,它的自身对齐参数为1,#pragma pack(n)默认值为8,则最终a的对齐参数为1,为其分配1字节的空间,它相对于结构体起始地址的偏移量为0,能被4整除;
对于变量b,它的自身对齐参数为4,#pragma pack(n)默认值为8,则最终b的对齐参数为4,接下来的地址相对于结构体的起始地址的偏移量为1,1不能够整除4,所以需要在a后面填充3字节使得偏移量达到4,然后再为b分配4字节的空间;
对于变量c,它的自身对齐参数为2,#pragma pack(n)默认值为8,则最终c的对齐参数为2,而接下来的地址相对于结构体的起始地址的偏移量为8,能整除2,所以直接为c分配2字节的空间。
此时结构体所占的字节数为1+3+4+2=10字节
最后由于a,b,c的最终对齐参数分别为1,4,2,最大为4,#pragma pack(n)的默认值为8,则结构体变量最后的大小必须能被4整除。而10不能够整除4,所以需要在后面填充2字节达到12字节。其存储如下:
|char|----|----|----| 4字节
|--------int--------| 4字节
|--short--|----|----| 4字节
总共占12个字节
对于node3,含有静态数据成员
typedef struct node3
{
int a;
short b;
static int c;
}S3;则sizeof(S3)=8.这里结构体中包含静态数据成员,而静态数据成员的存放位置与结构体实例的存储地址无关(注意只有在C++中结构体中才能含有静态数据成员,而C中结构体中是不允许含有静态数据成员的)。其在内存中存储方式如下:
|--------int--------| 4字节
|--short-|----|----| 4字节
而变量c是单独存放在静态数据区的,因此用siezof计算其大小时没有将c所占的空间计算进来。
而对于node5,里面含有结构体变量
typedef struct node5
{
bool a;
S1 s1;
double b;
int c;
}S5;sizeof(S5)=32。
对于变量a,其自身对齐参数为1,#pragma pack(n)为8,则a的最终对齐参数为1,为它分配1字节的空间,它相对于结构体起始地址的偏移量为0,能被1整除;
对于s1,它的自身对齐参数为4(对于结构体变量,它的自身对齐参数为它里面各个变量最终对齐参数的最大值),#pragma pack(n)为8,所以s1的最终对齐参数为4,接下来的地址相对于结构体起始地址的偏移量为1,不能被4整除,所以需要在a后面填充3字节达到4,为其分配8字节的空间;
对于变量b,它的自身对齐参数为8,#pragma pack(n)的默认值为8,则b的最终对齐参数为8,接下来的地址相对于结构体起始地址的偏移量为12,不能被8整除,所以需要在s1后面填充4字节达到16,再为b分配8字节的空间;
对于变量c,它的自身对齐参数为4,#pragma pack(n)的默认值为8,则c的最终对齐参数为4,接下来相对于结构体其实地址的偏移量为24,能够被4整除,所以直接为c分配4字节的空间。
此时结构体所占字节数为1+3+8+4+8+4=28字节。
对于整个结构体来说,各个变量的最终对齐参数为1,4,8,4,最大值为8,#pragma pack(n)默认值为8,所以最终结构体的大小必须是8的倍数,因此需要在最后面填充4字节达到32字节。其存储如下:
|--------bool--------| 4字节
|---------s1---------| 8字节
|--------------------| 4字节
|--------double------| 8字节
|----int----|---------| 8字节
另外可以显示地在程序中使用#pragma pack(n)来设置系统默认的对齐参数,在显示设置之后,则以设置的值作为标准,其它的和上面所讲的类似,就不再赘述了,读者可以自行上机试验一下。如果需要取消设置,可以用#pragma pack()来取消。
/article/2052894.html
先看一个空的类占多少空间?
[cpp] view
plaincopy
class Base
{
public:
Base();
~Base();
};
注意到我这里显示声明了构造跟析构,但是sizeof(Base)的结果是1.
因为一个空类也要实例化,所谓类的实例化就是在内存中分配一块地址,每个实例在内存中都有独一无二的地址。同样空类也会被实例化,所以编译器会给空类隐含的添加一个字节,这样空类实例化之后就有了独一无二的地址了。所以空类的sizeof为1。
而析构函数,跟构造函数这些成员函数,是跟sizeof无关的,也不难理解因为我们的sizeof是针对实例,而普通成员函数,是针对类体的,一个类的成员函数,多个实例也共用相同的函数指针,所以自然不能归为实例的大小,这在我的另一篇博文有提到。
接着看下面一段代码
[cpp] view
plaincopy
class Base
{
public:
Base();
virtual ~Base(); //每个实例都有虚函数表
void set_num(int num) //普通成员函数,为各实例公有,不归入sizeof统计
{
a=num;
}
private:
int a; //占4字节
char *p; //4字节指针
};
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
private:
static int st; //非实例独占
int d; //占4字节
char *p; //4字节指针
};
int main()
{
cout<<sizeof(Base)<<endl;
cout<<sizeof(Derive)<<endl;
return 0;
}
结果自然是
12
20
Base类里的int a;char *p;占8个字节。
而虚析构函数virtual ~Base();的指针占4子字节。
其他成员函数不归入sizeof统计。
Derive类首先要具有Base类的部分,也就是占12字节。
int d;char *p;占8字节
static int st;不归入sizeof统计
所以一共是20字节。
在考虑在Derive里加一个成员char c;
[cpp] view
plaincopy
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
private:
static int st;
int d;
char *p;
char c;
};
这个时候,结果就变成了
12
24
一个char c;增加了4字节,说明类的大小也遵守类似class字节对齐,的补齐规则。
具体的可以看我那篇《5分钟搞定字节对齐》
至此,我们可以归纳以下几个原则:
1.类的大小为类的非静态成员数据的类型大小之和,也就是说静态成员数据不作考虑。
2.普通成员函数与sizeof无关。
3.虚函数由于要维护在虚函数表,所以要占据一个指针大小,也就是4字节。
4.类的总大小也遵守类似class字节对齐的,调整规则。
上一篇文章研究了关于类大小的4条规则后,我们再结合虚函数表,来研究下类的大小。
[cpp] view
plaincopy
class Base
{
public:
Base(){};
virtual ~Base(){};
void set_num(int num)
{
a=num;
}
virtual int get_num()
{
return a;
}
private:
int a;
char *p;
};
class Derive:public Base
{
public:
Derive():Base(){};
~Derive(){};
virtual int get_num()
{
return d;
}
private:
static int st;
int d;
char *p;
char c;
};
int main()
{
cout<<sizeof(Base)<<endl;
cout<<sizeof(Derive)<<endl;
return 0;
}
在Base类里添加了virtual int get_num()函数,而子类也重新实现了virtual int get_num()函数。
但是结果依然是
12
24
说明子类只是共用父类的虚函数表,因此一旦父类里有虚函数,子类的虚函数将不计入sizeof大小。
这可以认为是一个补充规则。
http://www.cnblogs.com/BeyondTechnology/archive/2010/09/21/1832369.html
使用sizeof计算类的大小
类的sizeof大小一般是类中的所有成员的sizeof大小之和,这个就不用多说。不过有两点需要注意:1)当类中含有虚成员函数的时候,例如:
class B
{
float a;
public:
virtual void fun(void);
}
此时sizeof(B)的大小为8,而不是4。因为在类中隐藏了一个指针,该指针指向虚函数表,正因为如此,
使得C++能够支持多态,即在运行时绑定函数的地址。
2)另一个要注意的是,当类中没有任何成员变量,也没有虚函数的时候,该类的大小是多少呢?
例如:
class B2
{
void fun(void);
}
此时sizeof(B2)的值是多少呢?在C++早期的编译器中,这个值为0;然而当创建这样的对象时,
它们与紧接着它们后面的对象有相同的地址。比如:
B2 b2;
int a;
那么对象b2与变量a有相同的地址,这样的话对对象b2地址的操作就会影响变量a。所以在现在大多数编译器中,该值的大小为1。
如果有虚函数,则sizeof值为类的数据成员的大小加上VTBL(指针,4字节),再加上其基类的数据成员的大小。如果是多重继承,还得加上各基类的VTBL。
虚继承之单继承的内存布局
先看一段代码
class A
{
virtual aa(){};
};
class B : public virtual A
{
char j[3]; //加入一个变量是为了看清楚class中的vfptr放在什么位置
public:
virtual bb(){};
};
class C : public virtual B
{
char i[3];
public:
virtual cc(){};
};
这次先不给结果,先分析一下,也好加强一下印象。
1、对于class A,由于只有一个虚函数,那么必须得有一个对应的虚函数表,来记录对应的函数入口地址。同时在class A的内存空间中之需要有个vfptr_A指向该表。sizeof(A)也很容易确定,为4。
2、对于class B,由于class B虚基础了class A,同时还拥有自己的虚函数。那么class B中首先拥有一个vfptr_B,指向自己的虚函数表。还有char j[3],做一次alignment,一般大小为4。可虚继承该如何实现咧?首先要通过加入一个虚l类指针(记vbptr_B_A)来指向其父类,然后还要包含父类的所有内容。有些复杂了,不过还不难想象。sizeof(B)= 4+4+4+4=16(vfptr_B、char j[3]做alignment、vbptr_B_A和class A)。
3、在接着是class C了。class C首先也得有个vfptr_C,然后是char i[3],然后是vbptr_C_B,然后是class B,所以sizeof(C)=4+4+4+16=28(vfptr_C、char i[3]做alignment、vbptr_C_A和class B)。
在VC 6.0下写了个程序,把上面几个类的大小打印出来,果然结果为4、16、28。
VC中虚继承的内存布局——单继承
画了个图,简单表示一下我跟踪后的结果
虚基础之单继承时的内存布局图
class A的情况太简单,没问题。从class B的内存布局图可以得出下面的结论。
1、vf_ptr B放在了类的首部,那么如果要想直接拿memcpy完成类的复制是很危险的,用struct也是不行的。
2、vbtbl_ptr_B,为什么不是先前我描述的vbptr_B_A呢?因为这个指针与我先前猜测的内容有很大区别。这个指针指向的是class B的虚类表。看看VB table,VB table有两项,第一项为FFFFFFFC,这一项的值可能没啥意义,可能是为了保证虚类表不为空吧。第二项为8,看起来像是class B中的class A相对该vbtbl_ptr_B的位移,也就是一个offset。类似的方法在C++ Object Model(P121)有介绍,可以去看看。
class C的内存布局就比较复杂了,不过它的内存布局也更一步说明我对vbtbl_ptr_B中的内容,也就是虚类表的理解是正确的。不过值得关注的是class B中的class A在布局时被移到前面去了,虽然整个大小没变,但这样一来如果做这样的操作 C c; B *b;b=&c;时b的操作如何呢?此时只要从c的虚类表里获得class B的位置既可赋值给b。但是在构建class C时会复杂一些,后面的使用还是非常简单的,效率也比较高。class A的内存布局被前移可能是考虑倒C的虚继承顺序吧。
结论
1、VC在编译时会把vfptr放到类的头部;
2、VC采用虚表指针(vbtbl_ptr)来确定某个类所继承的虚类。
3、VC会重新调整虚继承的父类在子类中内存布局。(具体规则还不清楚)
4、VC中虚类表中的第一项是无意义的,可能是为了保证sizeof(虚类表)!=0;后面的内容为父类在子类中相对该虚类表指针的偏移量。

相关文章推荐
- C/C++ 结构体 字节对齐原则详细举例解释 及sizeof的基本用法
- 【C++学习笔记】sizeof()的用法与字节对齐
- 【C++】继承类之sizeof计算_字节对齐【总结篇】
- C/C++中结构体的字节对齐以及求sizeof()
- C++基础系列:sizeof与字节对齐问题
- C/C++中的结构体的字节对齐和#paragma pack (n)编译命令
- C++:字节对齐(内存地址对齐)
- 关于C++ 字节对齐
- C++ sizeof 及 涉及的内存对齐
- struct和 union用 sizeof 看字节对齐,以及__declspec( align( # ) ) 和 #pragma pack()的使用方式
- C++中结构体的字节对齐问题
- 转:关于n字节对齐和sizeof的用法
- sizeof和字节对齐
- 基于结构体sizeof的字节对齐问题讨论
- Thinking In Linux C/C++字节对齐详解
- 关于n字节对齐和sizeof的用法
- C/C++中的字节对齐问题小贴
- C/C++字节对齐简述
- 关于C/C++语言字节对齐
- 关于C++ 字节对齐 - zafair的专栏 - CSDNBlog