Dremel: Interactive Analysis of Web-Scale Datasets 1~6节算法思想部分翻译
2014-08-08 12:49
453 查看
摘要:
Dremel是一个具有可扩展性和交互性,专用于分析只读嵌套数据的查询系统。它本身对多级操作数和柱状数据布局的融合使它得以在秒级的反应时间内对有万亿数量级行记录的表进行集成语句查询。这个系统在谷歌包含数以千计的CPU和PT级的数据量,并有着上千名使用者。这篇论文中,我们将会介绍Dremel的体系结构以及其实现,并阐述它如何实现基于MapReduce的计算。我们将呈现一种全新的嵌套式数据柱状存储方式并通过一个基于几千节点的样例系统实验分析性能。
1.介绍:
大型数据分析性处理已经在互联网公司和各个工业行业里成为一个潮流,这并不仅是因为低价的存储设备使得所有人对关键业务数据的存储成为可能。将这些数据放在分析师与工程师们触手可得处的重要性与日俱增,交互反应时间的差别常常令各种各样的任务,比如数据挖掘,监视(monitoring),在线用户支持(onlinecustomer
support),快速原型(rapidprototyping),数据流水线排错(debuggingof data pipelines)等等任务的结果产生质的差别。
实现大型的交互式数据分析需要很高水平的并行性。比如,想从现今的商用硬盘里用一秒以内的时间得到tb数量级的数据,我们需要同时使用上万个磁盘。同样的,对CPU要求很高的查询语句要想在秒级时间内完成也需要数千个内核同时运行才得以实现。在Google,大量并行计算是基于共享的商业机器集群完成的[5]。一个集群通常都会跑着许多需要一起共享资源,却有着不同工作负荷和使用不同硬件参数的分布式应用。在这些分布式应用中,某些任务可能会花费比自己单节点时更多的时间去完成,甚至因为节点失效或者是任务被集群管理器系统抢占等原因永远无法完成。所以,为了快速执行完成任务同时得到高容错性的重要任务就在于如何处理这些“掉队者”或者“失败者”[10]。
网页计算或是科学计算所使用的数据彼此间通常都是没有相关性的。所以,一个灵活的数据模型在这些领域就显得尤为重要。编程语言所使用的数据结构,分布式系统中的交换信息(包),结构化文档等等总是以嵌套的形式来表达自己。在网页中将这些信息规范化以及重新组合等等通常都是禁止的。谷歌的大部分结构化数据都是基于嵌套式数据模型的,很多主流的互联网公司听说也是如此。
这篇论文阐述了一个支持基于商用机器的共享集群中超大规模数据集的交互式分析的系统,名为Dremel。与传统的数据库不同,它可以对insitu的嵌套式数据进行查询。Insitu,指的是“合适地”找到数据的能力,比如,在一个像GFS一样的分布式文件系统或是其它存储层中。Dremel可以对存储数据执行很多查询语句,而这些工作本来可能是需要用MapReduce这样的工具来实现的,但Dremel只需要花费后者百分之几的时间即可完成任务。Dremel的目的并不是成为MR的替代品,它经常和MR一起工作去分析MR的输出流或者是进行更大量数据的快速原型。
Dremel诞生于2006年,在谷歌内部有着上千用户。Dremel的很多应用案例都被布置在公司成千上万的数据节点当中。以下便是其中一些样例:
对爬取的网络文件进行分析(Analysisof crawled web documents)
跟踪安卓市场的应用安装信息(Trackinginstall data for applications on Android Market)
谷歌产品的运行崩溃信息(Crashreporting for Google products)
谷歌书籍的光学字符识别(OpticalCharacter Recognition)
垃圾邮件分析(Spamanalysis)
谷歌地图的地图片排错(Debuggingof map tiles on Google Maps)
大数据表的子表迁移(Tabletmigrations in managed Bigtable instances)
谷歌分布式系统的测试结果(Resultsof tests run on Google’s distributed build system)
成百上千的硬盘I/O数据信息(Resultsof
tests run on Google’s distributed build system)
对运行在谷歌数据中心的应用进行资源监控(Resourcemonitoring for jobs run in Google’s data centers)
谷歌代码库中的标记和依赖(Resourcemonitoring for jobs run in Google’s data centers)
创建Dremel的灵感来自于网络搜索和并行式DBMS。首先,它的体系架构借鉴了分布式搜索引擎的服务树结构[11]。就像一个网络搜索请求一样,一个查询语句会被往树下推,每一步都会重写。查询结果是对所有低层树回复的集合。第二,Dremel提供了一个高级的,类似SQL的语言来表达专门的查询语句。与Pig[18]和Hive[16]不同,Dremel可以自己实现查询,并不需要将工作转化成MR任务。
最后,也是最重要的一点,Dremel使用了一种柱状存储机制,而正是这一点使它能够从二级存储中读取更少的数据量,更低廉的压缩代价也减少了CPU消耗。列向存储机制已经被用来对关系型数据进行分析,但据我们所知,它还并没有被应用到嵌套数据模型中去。我们展示的柱状存储格式受到谷歌许多数据处理工具的支持,包括MR,Sawzall[20],和FlumeJava[7]。
本篇论文主要内容如下:
介绍一种针对嵌套式数据的创新式柱状存储格式。我们会展示拆分嵌套式数据成列以及重组它们的算法。
我们将会列出Dremel的查询语言和执行方式。它们都是为了更有效地操作柱状嵌套式数据的同时不需要重组柱状数据(第五小节)而专门设计的。
我们会展示网络搜索系统中的执行树是如何被应用到数据库处理中,并阐释它在处理执行集合查询语句时高效的原因。
我们会展示一个基于千亿级数据记录,数tb数据集,基于1000~4000系统数据节点的实验(第七小节)。
本篇论文的结构如下:在第二节,我们会解释Dremel是如何与其它数据管理工具相结合来进行数据分析的。第三节会介绍它的数据模型。前文所提及的最主要内容会在第四到第八小节中依次详述。一些相关工作会在第九小节简述。第十小节则为结语。
2.背景
我们先来看看交互式查询处理是如何与大型数据管理生态系统合作的。假设谷歌工程师Alice有了一个新点子,她想从网页中提取新类型的信号。她在分布式文件系统上跑了一个MR任务,这个任务会把input数据启动并产出一个包含新信号的数据集,结果就存储在分布式系统的亿万条记录之中。为了分析她的数据结果,她启动Dremel并执行了几条交互式命令:
DEFINETABLE t AS /path/to/data/*
SELECTTOP(signal1, 100), COUNT(*) FROM t
她的命令很快就在几秒内被执行了。她又执行了几个别语句来确认自己的算法无误。当她发现Signal1里有一个bug时,她写了一个可以进行更多复杂分析计算的FlumeJava[7]程序来深层次地分析之前的输出集合。这个工作完成后,她创建了一个持续处理输入数据的工作流水线。她又制定了一些SQL语句去汇集跨越了多维度的流水线输出结果,同时把它们添加到一个交互式的仪表盘中去。最后她将她的新数据集放入一个类别中以方便别的工程师快速定位使用它。
以上这个情景就要求查询语句处理器和其它数据管理工具的内部交互操作。首先它们必须要有一个共同的存储层(commonstoragelayer)。GFS[14]就是这样一种在谷歌广泛使用的分布式存储层。GFS使用了复制备份的方法以保护数据,同时能在出现个别节点罢工的时候照样保证低反应时间。一个高性能的存储层对insitu数据管理的要求是苛刻的。它要能够快速地定位所需要数据位置,而这恰恰是传统数据库分析数据处理时的一个主要阻力——大部分时候DBMS取数据和执行一个查询语句的时间都可以用来跑好几打的MR任务了[13]。这个共同的平台还有一个附加的好处,就是文件系统中的数据可以被通用工具很方便地操作,比如,转移数据到另一个集群上,改变访问优先级,或是定义一个基于文件名的数据分析子集。
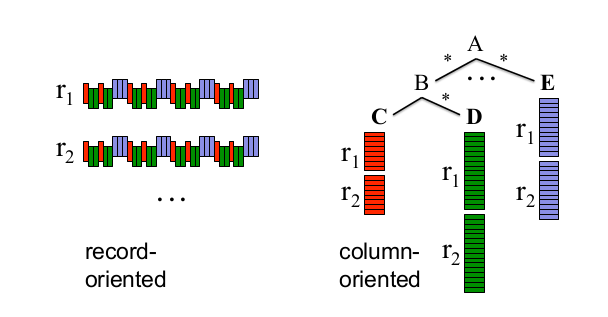
图1:嵌套型数据的按记录存储vs.柱状存储
第二,要建立一个可内部交互操作的数据管理部件还需要一个统一的存储格式。柱状存储已经在平整的关系型数据上取得了成功,但要使它对谷歌同样奏效的话就要求它能够适应嵌套式数据模型。图1阐述了它的主要思想:相同嵌套字段(比如A,B,C)的所有值都被连续地存储着。因此,A.B.C可以在不读入A.E和A.B.D的情况下就被检索到。在此我们强调,我们所面临的挑战是如何保存所有的数据结构信息以及如何从任意字段的子集中重构记录。接下来我们将讨论我们的数据模型,这之后还有算法和查询语句处理。
3.数据模型
这部分我们会展示Dremel的数据模型,并介绍一些之后会用到的术语。这个在谷歌广泛使用的数据模型来自于分布式系统的内容,具体实现方式也已经开源。这个数据模型基于强类型的嵌套记录,它的抽象语法如下:
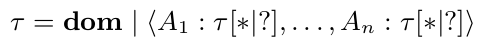
其中τ指代原子类型或是记录类型。dom中的原子类型由整型,浮点数,字符串等组成。记录由一个或者多个字段组成。一个记录中的字段i被命名为Ai,也可以是一个多下标的表示。重复字段(*)在一个记录中可能重复多次。它们被当作为一列值,比如,在一个记录中它域所出现的顺序一定是值得我们注意的。选择字段(?)可能不会在一个记录中出现。其余情况下,一个字段是必须的,比如说它必须刚刚好出现一次。
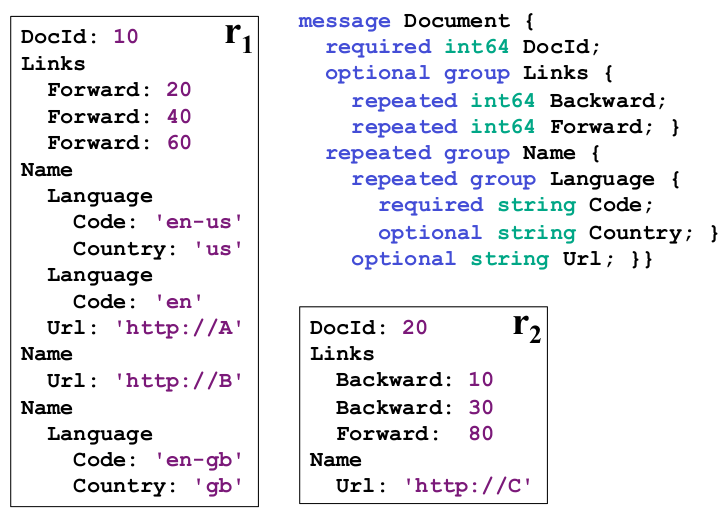
图2:两个嵌套式记录的样本以及它们的模型
为了更好地阐述这个概念,请看图2。它刻画了一个定义记录类型Document的模型,代表了一个网络文件。这个模型的定义用了具体的语法形式[21]。一个Document需要一个整型的DocId和一个可选的Links,Links又包含了存储其它网页DocId的Forward和Backward。一个Document可以有多个名字,其实也就是这个Document指向的不同的URLs。一个Name包含了一个Code序列和一个可选的Country对。图2还展示了两个基于这个模型的记录样本r1和r2。记录模型的结构用缩进表示出来了。接下来的模块里我们将继续用这个样本来解释我们的算法。这个模型中定义的字段可以组成一个树结构。这个嵌套字段的全路径是用普通的点符号表示,比如:Name.Language.Code。
嵌套式数据模型支持平台无关和谷歌序列化结构数据可扩展机制。代码生成工具可以绑定C++和Java这类编程语言。记录的标准二进制在线表示法使跨语言的内部可操作性(Cross-languageinteroperability)成为可能,通过这种方式字段值也按照它们在一条记录中出现的先后被顺序记录下来。同样通过这种方式,一个Java写的MR程序可以使用数据源中用C++库表示的记录。因此,如果以柱状形式来存储数据,为了使Dremel可以和MR或是其它数据处理工具合作,如何汇集它们就变得很重要。
4.嵌套式柱状存储
正如图1当中展示的那样,我们的目的是想通过连续存储某一个字段的所有值来提高检索效率。在本模块中,我们将着重讨论如下问题:柱状格式记录结构的无损存储(4.1);快速编码(4.2);记录有效重组(4.3)。
4.1
重复级别和定义级别
如果仅仅有数据的话是无法表示一个记录的结构的。给一个可重复字段的两个值,我们不会知道这个值是处在哪一个“级别”上的。(比如,它们到底是来自两个不同的记录,还是一个记录中的两个重复记录)。同样的,如果一个可选择字段被弄丢了,我们就不会知道哪一个是清晰定义的记录。所以我们引进了重复和定义级别的概念,详细定义可见后文。作为参考,可以查看总结了我们样例记录中所有原子字段重复和定义级别的图3。
重复级别:回顾下图2中的Code字段。它在r1中出现了3次。‘en-us’和‘en’出现在第一个Name中,而‘en-gb’出现在第三个Name中。为了不使这些让我们产生混淆,我们会给每个值添加一个重复级别。它会告诉我们这个值重复了这个字段路径中的哪一个重复字段(atwhat
repeated field in the field’s path the value hasrepeated)。字段路径Name.Language.Code包含了两个重复字段,Name和Language。因此,Code的重复级别取区间[0,2];级别0表示这是一个新纪录的起点。现在假设我们在从头到尾扫描记录r1。当我们遇到‘en-us’时,我们还没有遇到任何的重复字段,也就是说,重复级别为0。当我们遇到‘en’时,Language字段重复了,所以它的重复级别就是2。最终,当我们扫描到‘en-gb’,Name已经重复了最多次(Language在Name之后只出现了一次),所以它的重复级别是1。所以,r1中Code字段值的重复级别是0,2,1。
可以注意到r1中的第二个Name字段并不包含任何的Code值。为了确定‘en-gb’确实是出现在第三个Name而不是第二个,我们在‘en’和‘en-gb’中添加一个NULL值(详见图3)。Code是Language当中的一个必须字段,所以它的值如果消失则表明Language并没有被定义。但是一般情况下,要决定嵌套记录的存在哪一级别还需要一些额外信息。
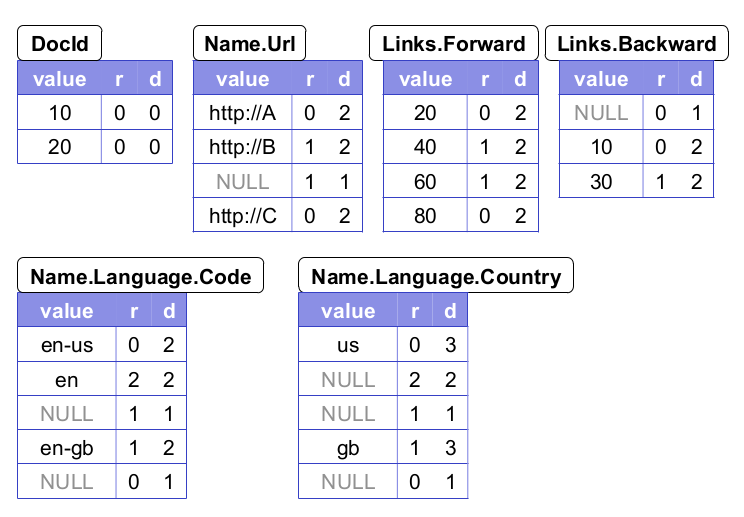
图3:图2中样本记录的柱状表示,包括重复级别(r)和定义级别(d)
定义级别:每一个带有路径p的字段值,尤其是那些NULL地址的,都有一个定义级别来记录p中有多少可以不用定义的字段(因为它们是可重复或是可选择的)是真正存在的。我们可以观察到r1并没有Backward链接,但是,字段Links是定义了的。为了保存这个信息,我们可以给Links.Backward列添加一个NULL值和定义级别1。同样地,r2中消失的Name.Language.Country也有一个定义级别1,而r1中这个的定义级别分别为2(Name.Language中)和1(Name中)。
我们使用整型的定义级别而不是用0-1比特值的原因,是因为这样叶节点字段的数据(比如:Name.Language.Country)就会包含它父母字段的出现信息;这种信息我们要如何使用将会在4.3节给出。
上文中罗列出的编码方式可以无损地保存记录结构。证明过程为了省纸就免了吧~
编码:每一列都是以块的集合的形式存储。每个块都会保存重复级别和定义级别的信息(下文简称为级别)和压缩过的字段值。NULL值们并不会特别保存,因为它们因为通过定义级别就可以得到:任何比该字段路径中重复字段和可选字段之和小的定义级别都表示它值为NULL。定义级别并不是为那些永远定义过的值保存的。相同的,重复级别只在被要求的时候对它进行保存;比如,定义级别为0就表示它的重复级别页为0,所以后者在保存时就可以省了。实际上,在图3中,没有什么级别是为DocId存的。级别会以比特序列的方式被打包。我们只需要用足够的bit数;比如,如果最大定义级别是3,每个定义级别我们就用两个bit去存储。
4.2 将记录拆分成列
上文我们展示了记录结构的编码方式,接下来我们要面临的挑战便是如何高效地利用重复级别和定义级别产生列条。
附录A中有用来计算重复级别和定义级别的基础算法。算法在记录结构中递归计算每一字段值的级别。正如之前阐述过的,重复和定义级别甚至在字段值不存在时也需要被计算。谷歌大部分的数据集都很稀疏;一个有几千字段的模型在实际记录中只用了一百个字段这种事情一点都不奇怪。所以,我们尽自己所能地尝试去降低处理消失字段的代价。为了创建列条,我们创建了一颗符合数据模型结构的树,取名“字段作家(fieldwriters)”。最基本的思想是去更新这个树当且仅当它们有自己的数据值,并且除非相当必要时,否则不去轻易把父节点的状态传播下去。为了实现后者,子作家(childwriters)会继承它父母的级别,无论何时子作家都会同步父母的级别值。
4.3
记录汇合
从列向存储的数据中高效地还原记录对基于记录存储的数据处理工具(比如MR)而言要求十分严格。给了一个子集的字段,我们的目标是去重构它原始的记录,仿佛它们本身就是包含了我们所有选择了的字段,其余的字段都不存在一样。最核心的思想是,我们创造了一个有限状态机(FSM)来读字段值和每个字段的级别,并且把这些值顺序附加到输出记录中。有限状态机的一个状态对应了一个被选择字段的读取器。状态转换用重复级别标记着。一旦一个读取器读到一个值,我们就去查看下一个重复级别已确定使用哪一个状态/读取器。每次读取记录FSM就会被从头到尾地遍历一次。
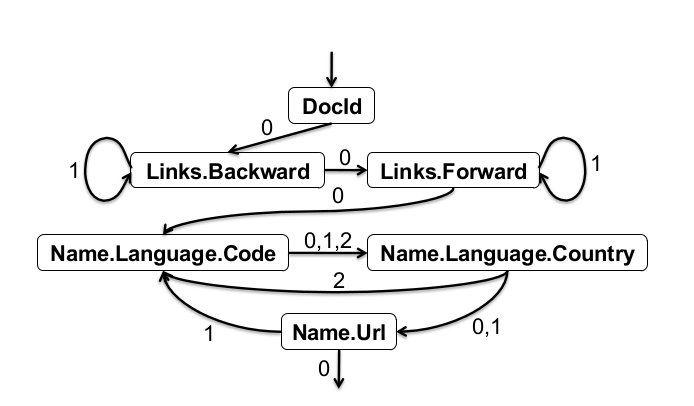
图4:完整记录汇合自动机;边上标记的是重复级别
图4展示了一个重构我们的样例的完整记录的有限状态机。初始状态是DocId。一旦一个DocId值已经被读到,FSM转移到Links.Backward。在所有重复的Backward值都被排出后,FSM会跳到Links.Forward,以此类推。附录B中有记录重构的详细实现算法。
为了描述FSM究竟是如何实现状态转移的,我们假设下一个当下的读取器返回的字段f的重复级别是1。从模型树上的f开始,我们找到它在l层重复祖先,并选择该祖先中的第一个叶子字段n。这便给了我们一个有限状态机的转移(f,l)
→ n。比如,让l=1作为f=
Name.Language.Country的读取器读取的下一个重复级别。它的重复级别为1的祖先是Name,Name的第一个叶子字段是n=
Name.Url。附录C中有FSM构建算法的详细过程。
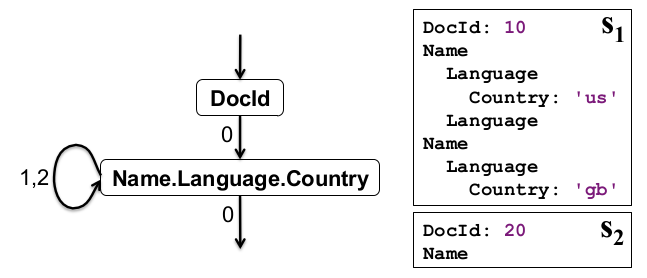
图5:从两个字段重构信息的自动机以及样例(右)
如果仅仅需要检索一个字段的子集,我们创建一个更简单的FSM,它消耗的资源也更少。图5描述了有一个只读取Name.Language.Country和DocId字段的状态机。这图同时还展示了s1和s2通过这个自动机产生的结果。需注意我们的编码和重构算法保存了Country字段的附属结构。这对于需要用到这些信息的应用而言很重要。比如,找到在第二个Name,第一个Language出现的Country。在路径语言中(XPath),与这个功能相似的表达式可以写成/Name[2]/Language[1]/Country。
5.查询语言
Dremel的查询语言是基于SQL的,并且为了能够在柱状嵌套存储设备上高效地运行而专门设计。如何规范地定义语言明显已经不在本论文的探讨范围以内;取而代之地,我们会讨论下它有哪些优点。每一个SQL语句(和它翻译成为的代数操作符)会取一个或者多个嵌套表和它们的结构,然后输出一个嵌套表作为它的输出。图6描述了一个实现映射,选择和记录自聚合的样例查询语句。这个查询语句基于图2的表t={r1,r2}分析。字段都通过路径表达式来表达。这个查询语句会产生一个嵌套结构虽然这个查询本身并没有体现记录重构的痕迹。

图6:查询语句样例/其输出/以及输出结构
为了剖析一个查询语句具体的实现,我们以选择操作为例(WHERE语句)。想象一个以标记树形式存在的嵌套记录,这颗标记树的每一个标记都对应它的字段名。这个选择操作符会剪掉这颗树中不符合我们选择条件的枝叶。所以,只有那些Name.Url被定义了并且以http开头的嵌套记录会被留下。接下来,考虑映射操作。每一个SELECT语句中的梯级表达式都会省略掉同一嵌套级别中该字段里最常重复的输入字段。所以,字符串的连接表达式在Name.Language.Code级里忽略了输入结构中Str的值。那个COUNT表达式表示记录的自聚合。这个聚合在访问每一个Name子记录中就已经完成,并且忽略了作为一个无符号64位整数的Name.Language.Code的重复次数。
Dremel查询语言支持嵌套子语句查询,记录内部或记录间的聚合运算,求前k位运算,交运算,用户自定义函数等等;其中一些功能在实验部分被强化了。
6.执行查询语句
简洁起见,我们将讨论一个只读系统执行查询语句处理的核心思想。许多的Dremel查询语句都是一轮的聚合;所以我们会着重解释这一点并用他们在下一小节做实验。关于交,索引,更新等等的问题将被放在日后的工作中考虑。
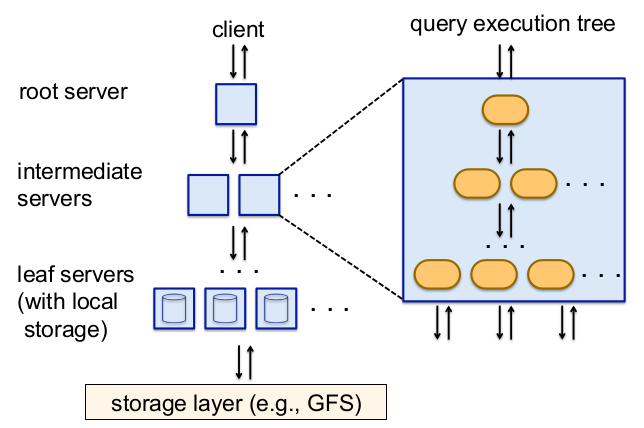
图7:系统体系架构以及服务器节点的内部运行
树结构:Dremel用了一个多级别的服务树来执行查询语句(见图7)。一个根服务器接收到新来的查询语句,从表中读取元数据,并把这个查询语句路由给这颗服务树的下一个层级。叶子服务器和存储层交流或者是直接找到本地磁盘内的数据。我们以一个简单的聚合语句为例:
SELECT A,COUNT(B) FROM T GROUP BY A
当根服务器接收到以上语句时,它决定生成构成T的所有的分割块(比如水平切分表)并重写这个查询语句如下:

表R11,...,R1n是这个查询将送到服务树第一层级的1,...,n号节点的输入:
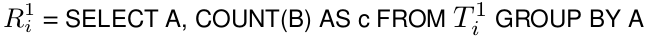
T1i是表T中的一个即将被第一层级服务器节点i处理的不相交子集。每一个服务层都会执行这种相似的重写过程。最终这些查询语句会到达平行扫描T表子表的叶子层。在向上返回时,中间服务器节点就会平行地汇合各个部分节点的输出结果。我们刚才展示的这个执行模型相当适合只返回很小或者是中等大小数据量答案的聚合查询语句——这种数据量的答案是我们查询时最常遇到的情况。需要返回结果很大的聚合语句或是其它类型的查询语句就需要依赖于我们已知的DBMS或是MR的执行机制了。
查询语句调度器:Dremel是一个多用户的系统,比如,通常会有很多个查询语句同时被执行。查询语句调度器会基于它们的优先级来调度查询,同时平衡负载。它另一个很重要的角色是当某一服务器的执行速度掉队或者是一个子表的副本无法读取时提供容错机制。
每个查询语句所需要处理的数据量往往比我们提供的处理单位大,通常我们称这些处理单位为槽(slot)。一个槽对应一个叶服务器的执行线程。比如,一个有3000叶节点服务器的系统,每个叶服务器有8个线程,那么这个系统就有24000个槽。所以,一个被分为100000份的表可以分别给每个槽分配5个子表。在每个查询语句执行时,查询语句调度器会计算一个处理子表时间的直方图。如果一个子表用了过长的时间被处理,它就会进行重新调度,把它放到别的服务器上。某些子表可能会需要被重新调度很多次。
叶节点服务器读取嵌套数据的柱状条。每条里的块都异步地被事先取得;预读取(read-ahead)的高速缓存一般来讲都有着95%的命中率。子表通常会被复制3份。当一个叶子节点无法取得某一份备份时,它会转向另外一份备份。
查询语句调度器有一个规定返回结果时至少子表已扫描百分比的参数。简单展示一下,把这个值设低一点(比如,从100%改到98%)经常能够很明显地提升我们的运行时间,尤其当我们用小一点的复制因子时。
每一个服务器都有一个内部执行树,如图7右手边描述的那样。内部树通常有一个物理查询语句执行计划存在,包括对梯级表达式的分析。优化一点的情况,为大多数常见的梯级函数生成专门的代码。一种针对映射-选择-聚合查询语句的执行计划就包括以下思想:1.一个用来循规蹈矩扫描输入的柱状数据的迭代器集合;2.省略聚合语句的结果;3.用正确的重复级别和定义级别指代梯级函数;4.在查询语句执行期间完全彻底地忽略记录。附录D中有详细阐述。
某些Dremel的查询语句,比如top-k和count-disdinct,通过我们这个已知的一轮算法会只返回一个大致(approximate)的结果。
===========================================================================================================================================
标红部分表示不是很确定翻译正确性,最好自己参考论文原文重新理解。另第一次翻译论文可能有理解不够翻译不准确或是错误的地方欢迎指出>////////<
Dremel是一个具有可扩展性和交互性,专用于分析只读嵌套数据的查询系统。它本身对多级操作数和柱状数据布局的融合使它得以在秒级的反应时间内对有万亿数量级行记录的表进行集成语句查询。这个系统在谷歌包含数以千计的CPU和PT级的数据量,并有着上千名使用者。这篇论文中,我们将会介绍Dremel的体系结构以及其实现,并阐述它如何实现基于MapReduce的计算。我们将呈现一种全新的嵌套式数据柱状存储方式并通过一个基于几千节点的样例系统实验分析性能。
1.介绍:
大型数据分析性处理已经在互联网公司和各个工业行业里成为一个潮流,这并不仅是因为低价的存储设备使得所有人对关键业务数据的存储成为可能。将这些数据放在分析师与工程师们触手可得处的重要性与日俱增,交互反应时间的差别常常令各种各样的任务,比如数据挖掘,监视(monitoring),在线用户支持(onlinecustomer
support),快速原型(rapidprototyping),数据流水线排错(debuggingof data pipelines)等等任务的结果产生质的差别。
实现大型的交互式数据分析需要很高水平的并行性。比如,想从现今的商用硬盘里用一秒以内的时间得到tb数量级的数据,我们需要同时使用上万个磁盘。同样的,对CPU要求很高的查询语句要想在秒级时间内完成也需要数千个内核同时运行才得以实现。在Google,大量并行计算是基于共享的商业机器集群完成的[5]。一个集群通常都会跑着许多需要一起共享资源,却有着不同工作负荷和使用不同硬件参数的分布式应用。在这些分布式应用中,某些任务可能会花费比自己单节点时更多的时间去完成,甚至因为节点失效或者是任务被集群管理器系统抢占等原因永远无法完成。所以,为了快速执行完成任务同时得到高容错性的重要任务就在于如何处理这些“掉队者”或者“失败者”[10]。
网页计算或是科学计算所使用的数据彼此间通常都是没有相关性的。所以,一个灵活的数据模型在这些领域就显得尤为重要。编程语言所使用的数据结构,分布式系统中的交换信息(包),结构化文档等等总是以嵌套的形式来表达自己。在网页中将这些信息规范化以及重新组合等等通常都是禁止的。谷歌的大部分结构化数据都是基于嵌套式数据模型的,很多主流的互联网公司听说也是如此。
这篇论文阐述了一个支持基于商用机器的共享集群中超大规模数据集的交互式分析的系统,名为Dremel。与传统的数据库不同,它可以对insitu的嵌套式数据进行查询。Insitu,指的是“合适地”找到数据的能力,比如,在一个像GFS一样的分布式文件系统或是其它存储层中。Dremel可以对存储数据执行很多查询语句,而这些工作本来可能是需要用MapReduce这样的工具来实现的,但Dremel只需要花费后者百分之几的时间即可完成任务。Dremel的目的并不是成为MR的替代品,它经常和MR一起工作去分析MR的输出流或者是进行更大量数据的快速原型。
Dremel诞生于2006年,在谷歌内部有着上千用户。Dremel的很多应用案例都被布置在公司成千上万的数据节点当中。以下便是其中一些样例:
对爬取的网络文件进行分析(Analysisof crawled web documents)
跟踪安卓市场的应用安装信息(Trackinginstall data for applications on Android Market)
谷歌产品的运行崩溃信息(Crashreporting for Google products)
谷歌书籍的光学字符识别(OpticalCharacter Recognition)
垃圾邮件分析(Spamanalysis)
谷歌地图的地图片排错(Debuggingof map tiles on Google Maps)
大数据表的子表迁移(Tabletmigrations in managed Bigtable instances)
谷歌分布式系统的测试结果(Resultsof tests run on Google’s distributed build system)
成百上千的硬盘I/O数据信息(Resultsof
tests run on Google’s distributed build system)
对运行在谷歌数据中心的应用进行资源监控(Resourcemonitoring for jobs run in Google’s data centers)
谷歌代码库中的标记和依赖(Resourcemonitoring for jobs run in Google’s data centers)
创建Dremel的灵感来自于网络搜索和并行式DBMS。首先,它的体系架构借鉴了分布式搜索引擎的服务树结构[11]。就像一个网络搜索请求一样,一个查询语句会被往树下推,每一步都会重写。查询结果是对所有低层树回复的集合。第二,Dremel提供了一个高级的,类似SQL的语言来表达专门的查询语句。与Pig[18]和Hive[16]不同,Dremel可以自己实现查询,并不需要将工作转化成MR任务。
最后,也是最重要的一点,Dremel使用了一种柱状存储机制,而正是这一点使它能够从二级存储中读取更少的数据量,更低廉的压缩代价也减少了CPU消耗。列向存储机制已经被用来对关系型数据进行分析,但据我们所知,它还并没有被应用到嵌套数据模型中去。我们展示的柱状存储格式受到谷歌许多数据处理工具的支持,包括MR,Sawzall[20],和FlumeJava[7]。
本篇论文主要内容如下:
介绍一种针对嵌套式数据的创新式柱状存储格式。我们会展示拆分嵌套式数据成列以及重组它们的算法。
我们将会列出Dremel的查询语言和执行方式。它们都是为了更有效地操作柱状嵌套式数据的同时不需要重组柱状数据(第五小节)而专门设计的。
我们会展示网络搜索系统中的执行树是如何被应用到数据库处理中,并阐释它在处理执行集合查询语句时高效的原因。
我们会展示一个基于千亿级数据记录,数tb数据集,基于1000~4000系统数据节点的实验(第七小节)。
本篇论文的结构如下:在第二节,我们会解释Dremel是如何与其它数据管理工具相结合来进行数据分析的。第三节会介绍它的数据模型。前文所提及的最主要内容会在第四到第八小节中依次详述。一些相关工作会在第九小节简述。第十小节则为结语。
2.背景
我们先来看看交互式查询处理是如何与大型数据管理生态系统合作的。假设谷歌工程师Alice有了一个新点子,她想从网页中提取新类型的信号。她在分布式文件系统上跑了一个MR任务,这个任务会把input数据启动并产出一个包含新信号的数据集,结果就存储在分布式系统的亿万条记录之中。为了分析她的数据结果,她启动Dremel并执行了几条交互式命令:
DEFINETABLE t AS /path/to/data/*
SELECTTOP(signal1, 100), COUNT(*) FROM t
她的命令很快就在几秒内被执行了。她又执行了几个别语句来确认自己的算法无误。当她发现Signal1里有一个bug时,她写了一个可以进行更多复杂分析计算的FlumeJava[7]程序来深层次地分析之前的输出集合。这个工作完成后,她创建了一个持续处理输入数据的工作流水线。她又制定了一些SQL语句去汇集跨越了多维度的流水线输出结果,同时把它们添加到一个交互式的仪表盘中去。最后她将她的新数据集放入一个类别中以方便别的工程师快速定位使用它。
以上这个情景就要求查询语句处理器和其它数据管理工具的内部交互操作。首先它们必须要有一个共同的存储层(commonstoragelayer)。GFS[14]就是这样一种在谷歌广泛使用的分布式存储层。GFS使用了复制备份的方法以保护数据,同时能在出现个别节点罢工的时候照样保证低反应时间。一个高性能的存储层对insitu数据管理的要求是苛刻的。它要能够快速地定位所需要数据位置,而这恰恰是传统数据库分析数据处理时的一个主要阻力——大部分时候DBMS取数据和执行一个查询语句的时间都可以用来跑好几打的MR任务了[13]。这个共同的平台还有一个附加的好处,就是文件系统中的数据可以被通用工具很方便地操作,比如,转移数据到另一个集群上,改变访问优先级,或是定义一个基于文件名的数据分析子集。
图1:嵌套型数据的按记录存储vs.柱状存储
第二,要建立一个可内部交互操作的数据管理部件还需要一个统一的存储格式。柱状存储已经在平整的关系型数据上取得了成功,但要使它对谷歌同样奏效的话就要求它能够适应嵌套式数据模型。图1阐述了它的主要思想:相同嵌套字段(比如A,B,C)的所有值都被连续地存储着。因此,A.B.C可以在不读入A.E和A.B.D的情况下就被检索到。在此我们强调,我们所面临的挑战是如何保存所有的数据结构信息以及如何从任意字段的子集中重构记录。接下来我们将讨论我们的数据模型,这之后还有算法和查询语句处理。
3.数据模型
这部分我们会展示Dremel的数据模型,并介绍一些之后会用到的术语。这个在谷歌广泛使用的数据模型来自于分布式系统的内容,具体实现方式也已经开源。这个数据模型基于强类型的嵌套记录,它的抽象语法如下:
其中τ指代原子类型或是记录类型。dom中的原子类型由整型,浮点数,字符串等组成。记录由一个或者多个字段组成。一个记录中的字段i被命名为Ai,也可以是一个多下标的表示。重复字段(*)在一个记录中可能重复多次。它们被当作为一列值,比如,在一个记录中它域所出现的顺序一定是值得我们注意的。选择字段(?)可能不会在一个记录中出现。其余情况下,一个字段是必须的,比如说它必须刚刚好出现一次。
图2:两个嵌套式记录的样本以及它们的模型
为了更好地阐述这个概念,请看图2。它刻画了一个定义记录类型Document的模型,代表了一个网络文件。这个模型的定义用了具体的语法形式[21]。一个Document需要一个整型的DocId和一个可选的Links,Links又包含了存储其它网页DocId的Forward和Backward。一个Document可以有多个名字,其实也就是这个Document指向的不同的URLs。一个Name包含了一个Code序列和一个可选的Country对。图2还展示了两个基于这个模型的记录样本r1和r2。记录模型的结构用缩进表示出来了。接下来的模块里我们将继续用这个样本来解释我们的算法。这个模型中定义的字段可以组成一个树结构。这个嵌套字段的全路径是用普通的点符号表示,比如:Name.Language.Code。
嵌套式数据模型支持平台无关和谷歌序列化结构数据可扩展机制。代码生成工具可以绑定C++和Java这类编程语言。记录的标准二进制在线表示法使跨语言的内部可操作性(Cross-languageinteroperability)成为可能,通过这种方式字段值也按照它们在一条记录中出现的先后被顺序记录下来。同样通过这种方式,一个Java写的MR程序可以使用数据源中用C++库表示的记录。因此,如果以柱状形式来存储数据,为了使Dremel可以和MR或是其它数据处理工具合作,如何汇集它们就变得很重要。
4.嵌套式柱状存储
正如图1当中展示的那样,我们的目的是想通过连续存储某一个字段的所有值来提高检索效率。在本模块中,我们将着重讨论如下问题:柱状格式记录结构的无损存储(4.1);快速编码(4.2);记录有效重组(4.3)。
4.1
重复级别和定义级别
如果仅仅有数据的话是无法表示一个记录的结构的。给一个可重复字段的两个值,我们不会知道这个值是处在哪一个“级别”上的。(比如,它们到底是来自两个不同的记录,还是一个记录中的两个重复记录)。同样的,如果一个可选择字段被弄丢了,我们就不会知道哪一个是清晰定义的记录。所以我们引进了重复和定义级别的概念,详细定义可见后文。作为参考,可以查看总结了我们样例记录中所有原子字段重复和定义级别的图3。
重复级别:回顾下图2中的Code字段。它在r1中出现了3次。‘en-us’和‘en’出现在第一个Name中,而‘en-gb’出现在第三个Name中。为了不使这些让我们产生混淆,我们会给每个值添加一个重复级别。它会告诉我们这个值重复了这个字段路径中的哪一个重复字段(atwhat
repeated field in the field’s path the value hasrepeated)。字段路径Name.Language.Code包含了两个重复字段,Name和Language。因此,Code的重复级别取区间[0,2];级别0表示这是一个新纪录的起点。现在假设我们在从头到尾扫描记录r1。当我们遇到‘en-us’时,我们还没有遇到任何的重复字段,也就是说,重复级别为0。当我们遇到‘en’时,Language字段重复了,所以它的重复级别就是2。最终,当我们扫描到‘en-gb’,Name已经重复了最多次(Language在Name之后只出现了一次),所以它的重复级别是1。所以,r1中Code字段值的重复级别是0,2,1。
可以注意到r1中的第二个Name字段并不包含任何的Code值。为了确定‘en-gb’确实是出现在第三个Name而不是第二个,我们在‘en’和‘en-gb’中添加一个NULL值(详见图3)。Code是Language当中的一个必须字段,所以它的值如果消失则表明Language并没有被定义。但是一般情况下,要决定嵌套记录的存在哪一级别还需要一些额外信息。
图3:图2中样本记录的柱状表示,包括重复级别(r)和定义级别(d)
定义级别:每一个带有路径p的字段值,尤其是那些NULL地址的,都有一个定义级别来记录p中有多少可以不用定义的字段(因为它们是可重复或是可选择的)是真正存在的。我们可以观察到r1并没有Backward链接,但是,字段Links是定义了的。为了保存这个信息,我们可以给Links.Backward列添加一个NULL值和定义级别1。同样地,r2中消失的Name.Language.Country也有一个定义级别1,而r1中这个的定义级别分别为2(Name.Language中)和1(Name中)。
我们使用整型的定义级别而不是用0-1比特值的原因,是因为这样叶节点字段的数据(比如:Name.Language.Country)就会包含它父母字段的出现信息;这种信息我们要如何使用将会在4.3节给出。
上文中罗列出的编码方式可以无损地保存记录结构。证明过程为了省纸就免了吧~
编码:每一列都是以块的集合的形式存储。每个块都会保存重复级别和定义级别的信息(下文简称为级别)和压缩过的字段值。NULL值们并不会特别保存,因为它们因为通过定义级别就可以得到:任何比该字段路径中重复字段和可选字段之和小的定义级别都表示它值为NULL。定义级别并不是为那些永远定义过的值保存的。相同的,重复级别只在被要求的时候对它进行保存;比如,定义级别为0就表示它的重复级别页为0,所以后者在保存时就可以省了。实际上,在图3中,没有什么级别是为DocId存的。级别会以比特序列的方式被打包。我们只需要用足够的bit数;比如,如果最大定义级别是3,每个定义级别我们就用两个bit去存储。
4.2 将记录拆分成列
上文我们展示了记录结构的编码方式,接下来我们要面临的挑战便是如何高效地利用重复级别和定义级别产生列条。
附录A中有用来计算重复级别和定义级别的基础算法。算法在记录结构中递归计算每一字段值的级别。正如之前阐述过的,重复和定义级别甚至在字段值不存在时也需要被计算。谷歌大部分的数据集都很稀疏;一个有几千字段的模型在实际记录中只用了一百个字段这种事情一点都不奇怪。所以,我们尽自己所能地尝试去降低处理消失字段的代价。为了创建列条,我们创建了一颗符合数据模型结构的树,取名“字段作家(fieldwriters)”。最基本的思想是去更新这个树当且仅当它们有自己的数据值,并且除非相当必要时,否则不去轻易把父节点的状态传播下去。为了实现后者,子作家(childwriters)会继承它父母的级别,无论何时子作家都会同步父母的级别值。
4.3
记录汇合
从列向存储的数据中高效地还原记录对基于记录存储的数据处理工具(比如MR)而言要求十分严格。给了一个子集的字段,我们的目标是去重构它原始的记录,仿佛它们本身就是包含了我们所有选择了的字段,其余的字段都不存在一样。最核心的思想是,我们创造了一个有限状态机(FSM)来读字段值和每个字段的级别,并且把这些值顺序附加到输出记录中。有限状态机的一个状态对应了一个被选择字段的读取器。状态转换用重复级别标记着。一旦一个读取器读到一个值,我们就去查看下一个重复级别已确定使用哪一个状态/读取器。每次读取记录FSM就会被从头到尾地遍历一次。
图4:完整记录汇合自动机;边上标记的是重复级别
图4展示了一个重构我们的样例的完整记录的有限状态机。初始状态是DocId。一旦一个DocId值已经被读到,FSM转移到Links.Backward。在所有重复的Backward值都被排出后,FSM会跳到Links.Forward,以此类推。附录B中有记录重构的详细实现算法。
为了描述FSM究竟是如何实现状态转移的,我们假设下一个当下的读取器返回的字段f的重复级别是1。从模型树上的f开始,我们找到它在l层重复祖先,并选择该祖先中的第一个叶子字段n。这便给了我们一个有限状态机的转移(f,l)
→ n。比如,让l=1作为f=
Name.Language.Country的读取器读取的下一个重复级别。它的重复级别为1的祖先是Name,Name的第一个叶子字段是n=
Name.Url。附录C中有FSM构建算法的详细过程。
图5:从两个字段重构信息的自动机以及样例(右)
如果仅仅需要检索一个字段的子集,我们创建一个更简单的FSM,它消耗的资源也更少。图5描述了有一个只读取Name.Language.Country和DocId字段的状态机。这图同时还展示了s1和s2通过这个自动机产生的结果。需注意我们的编码和重构算法保存了Country字段的附属结构。这对于需要用到这些信息的应用而言很重要。比如,找到在第二个Name,第一个Language出现的Country。在路径语言中(XPath),与这个功能相似的表达式可以写成/Name[2]/Language[1]/Country。
5.查询语言
Dremel的查询语言是基于SQL的,并且为了能够在柱状嵌套存储设备上高效地运行而专门设计。如何规范地定义语言明显已经不在本论文的探讨范围以内;取而代之地,我们会讨论下它有哪些优点。每一个SQL语句(和它翻译成为的代数操作符)会取一个或者多个嵌套表和它们的结构,然后输出一个嵌套表作为它的输出。图6描述了一个实现映射,选择和记录自聚合的样例查询语句。这个查询语句基于图2的表t={r1,r2}分析。字段都通过路径表达式来表达。这个查询语句会产生一个嵌套结构虽然这个查询本身并没有体现记录重构的痕迹。
图6:查询语句样例/其输出/以及输出结构
为了剖析一个查询语句具体的实现,我们以选择操作为例(WHERE语句)。想象一个以标记树形式存在的嵌套记录,这颗标记树的每一个标记都对应它的字段名。这个选择操作符会剪掉这颗树中不符合我们选择条件的枝叶。所以,只有那些Name.Url被定义了并且以http开头的嵌套记录会被留下。接下来,考虑映射操作。每一个SELECT语句中的梯级表达式都会省略掉同一嵌套级别中该字段里最常重复的输入字段。所以,字符串的连接表达式在Name.Language.Code级里忽略了输入结构中Str的值。那个COUNT表达式表示记录的自聚合。这个聚合在访问每一个Name子记录中就已经完成,并且忽略了作为一个无符号64位整数的Name.Language.Code的重复次数。
Dremel查询语言支持嵌套子语句查询,记录内部或记录间的聚合运算,求前k位运算,交运算,用户自定义函数等等;其中一些功能在实验部分被强化了。
6.执行查询语句
简洁起见,我们将讨论一个只读系统执行查询语句处理的核心思想。许多的Dremel查询语句都是一轮的聚合;所以我们会着重解释这一点并用他们在下一小节做实验。关于交,索引,更新等等的问题将被放在日后的工作中考虑。
图7:系统体系架构以及服务器节点的内部运行
树结构:Dremel用了一个多级别的服务树来执行查询语句(见图7)。一个根服务器接收到新来的查询语句,从表中读取元数据,并把这个查询语句路由给这颗服务树的下一个层级。叶子服务器和存储层交流或者是直接找到本地磁盘内的数据。我们以一个简单的聚合语句为例:
SELECT A,COUNT(B) FROM T GROUP BY A
当根服务器接收到以上语句时,它决定生成构成T的所有的分割块(比如水平切分表)并重写这个查询语句如下:
表R11,...,R1n是这个查询将送到服务树第一层级的1,...,n号节点的输入:
T1i是表T中的一个即将被第一层级服务器节点i处理的不相交子集。每一个服务层都会执行这种相似的重写过程。最终这些查询语句会到达平行扫描T表子表的叶子层。在向上返回时,中间服务器节点就会平行地汇合各个部分节点的输出结果。我们刚才展示的这个执行模型相当适合只返回很小或者是中等大小数据量答案的聚合查询语句——这种数据量的答案是我们查询时最常遇到的情况。需要返回结果很大的聚合语句或是其它类型的查询语句就需要依赖于我们已知的DBMS或是MR的执行机制了。
查询语句调度器:Dremel是一个多用户的系统,比如,通常会有很多个查询语句同时被执行。查询语句调度器会基于它们的优先级来调度查询,同时平衡负载。它另一个很重要的角色是当某一服务器的执行速度掉队或者是一个子表的副本无法读取时提供容错机制。
每个查询语句所需要处理的数据量往往比我们提供的处理单位大,通常我们称这些处理单位为槽(slot)。一个槽对应一个叶服务器的执行线程。比如,一个有3000叶节点服务器的系统,每个叶服务器有8个线程,那么这个系统就有24000个槽。所以,一个被分为100000份的表可以分别给每个槽分配5个子表。在每个查询语句执行时,查询语句调度器会计算一个处理子表时间的直方图。如果一个子表用了过长的时间被处理,它就会进行重新调度,把它放到别的服务器上。某些子表可能会需要被重新调度很多次。
叶节点服务器读取嵌套数据的柱状条。每条里的块都异步地被事先取得;预读取(read-ahead)的高速缓存一般来讲都有着95%的命中率。子表通常会被复制3份。当一个叶子节点无法取得某一份备份时,它会转向另外一份备份。
查询语句调度器有一个规定返回结果时至少子表已扫描百分比的参数。简单展示一下,把这个值设低一点(比如,从100%改到98%)经常能够很明显地提升我们的运行时间,尤其当我们用小一点的复制因子时。
每一个服务器都有一个内部执行树,如图7右手边描述的那样。内部树通常有一个物理查询语句执行计划存在,包括对梯级表达式的分析。优化一点的情况,为大多数常见的梯级函数生成专门的代码。一种针对映射-选择-聚合查询语句的执行计划就包括以下思想:1.一个用来循规蹈矩扫描输入的柱状数据的迭代器集合;2.省略聚合语句的结果;3.用正确的重复级别和定义级别指代梯级函数;4.在查询语句执行期间完全彻底地忽略记录。附录D中有详细阐述。
某些Dremel的查询语句,比如top-k和count-disdinct,通过我们这个已知的一轮算法会只返回一个大致(approximate)的结果。
===========================================================================================================================================
标红部分表示不是很确定翻译正确性,最好自己参考论文原文重新理解。另第一次翻译论文可能有理解不够翻译不准确或是错误的地方欢迎指出>////////<

相关文章推荐
- 经典论文翻译导读之《Dremel: Interactive Analysis of WebScale Datasets》
- 经典论文翻译导读之《Dremel: Interactive Analysis of WebScale Datasets》
- Dremel - Interactive Analysis of WebScale Datasets
- 扫描线算法的论文《The Intersections for a Set of 2D Segments, and Testing Simple Polygons》的部分翻译
- [转]Web 数据的动态融合(Dynamic Fusion of Web Data 的文章进行翻译)
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- 翻译A Multiscale Retinex for Bridging the Gap Between Color Images and the Human Observation of Scenes
- 大规模超文本网络搜索引擎解析 [ The Anatomy of a Large-Scale Hypertextual Web Search Engine ]
- The Book of JavaScript: A Practical Guide to Interactive Web Pages
- Week 1 Analysis of Algorithm(算法分析)
- 【翻译】Mathematical Analysis of Algorithms
- The Book of JavaScript, 2nd Edition: A Practical Guide to Interactive Web Pages
- 在sdk中如何加入web浏览器的两种方法(部分原创部分翻译)
- 搜索引擎的工作原理 --《The Anatomy of a Large-Scale Hypertextual Web Search Engine》
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- Web Site 与 Web Application 的区别 (部分翻译)
- The Anatomy of a Large-Scale Hypertextual Web Search Engine
- HTML5 for Web Designers部分翻译(含中英文)
- 16 Inspiring Examples of Interactive Maps in Web Design