对Mahout_"推荐算法"的初步认识(4)
2014-08-03 09:51
218 查看
后来看了一些网络资源的文章,所以首先,为了与大家交流方便,在此对Mahout_"推荐算法"的初步认识系列前面的文章做一下声明:
在协同过滤算法中,我提到的Customeri和DataSeti是已经有名称共识的,分别是user和item,即:
(1)基于用户的协同推荐算法是:基于(user-based)的协同推荐算法
(2)基于项目的协同推荐算法是:基于(item-based)的协同推荐算法
当然,这只是名称,为了方便交流更正过来,不能闭门造车嘛。不过在内容上,算法的理解和解释是没有错误的,无须担心。
好了,继续本次的学习和研究。
相似性计算是协同过滤算法中最关键的一步,传统的相似度计算方法有以下三种:
1、余弦相似性
要想讲明白余弦相似性,先要说一下数据,或者说文档的表示方法。借用一个定义“文档用数以千计的属性表示,每个记录文档中一个特定词(如关键词)或短语的频度”。那么就是说任何一个文档都可以看做有很多属性组成的,构建成数学模型就是一个具有N维的向量,则每个文档都可以被一个所谓的词频向量(term-frequency-vector)表示。举下面一个例子:
表格1.1 词频向量布局示意表格
正如表格1.1所示,假设有一批金属材料的货物,任意从其中挑出五种金属材料进行数据统计与分析,得到表格如上所示,对于正视图、侧视图、俯视图,1和0代表有或者没有,其余各数据项的0代表那一项数据采集不全,或者对该文档的描述中没有这一项。我们可以看到,词频向量通常很长(因为每一个文档都可以从各种方面各个角度来描述),而且词频向量一般是稀疏的,数据中会有很多0项。那么我们如何判断文档之间的关系呢?我们需要一种度量,它关注两个文档确实共有的词(即不为0的属相项),以及这种词出现的频率,从而就可以对两个文档之间的关系进行界定。
这里就讲到余弦相似性了。余弦相似性是一种度量,它可以用来比较文档,或针对给定的查询词向量对文档排序。令x和y是两个待比较的向量,使用余弦度量作为相似性函数,定义如下所示:

(自己在word中用公式编辑器敲得公式粘贴不过来,截成图片也粘贴不过来,空的白色框框,先用别人的图,日后再研究)
其中,||x||是向量x=(x1,x1,...,xn)的欧几里得范数,定义为:
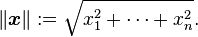
从概念上讲,它就是向量的长度。同理||y||就是向量y的欧几里得范数,计算方法相同。该度量计算向量x与y之间的夹角的余弦。余弦值在[-1,1]区间,越靠近0,证明匹配值越大、越相似;反之,越靠近1,证明匹配值越小、越不相关。补充一点知识:由于余弦相似性度量不遵守度量测度性质,因此它被称作非度量测度(nonmetric measure)。
公式 :

下面举一个例子来具体说明:
例:若有两个词频向量x,y分别是x=(5,0,3,0,2,0,0,2,0,0)和y=(3,0,2,0,1,1,0,1,0,1),请计算分析这两个词频向量x和y之间的相似性如何。当然,我们使用的是余弦相似性公式,应用公式我们得到:

通过计算我们可以得到词频向量x和y之间的相似性为0.94,那么同理,如果有一个词频向量集合,我们就可以通过余弦相似性公式进行两两之间的计算,从而得到与目标词频向量最相近、最类似的词频向量,用来推测该目标词频向量某一项属性的未知值了。
代码实现在网上找的:链接如下http://blog.csdn.net/cscmaker/article/details/7990600
(该代码未经本人调试检验,先留下来,以后研究)
2、修正余弦相似性
余弦相似性度量方法在衡量两个词频向量的计算中主要衡量的是两个向量之间的夹角问题,而并没有考虑到不同用户之间度量尺度的问题,也就是对数值不敏感,因此没法衡量每个维数上数值的差异,会导致这样一种情况:用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个
内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
所以修正余弦相似性就是在余弦相似性计算公式的基础上对每一项进行了与平均值的差值减法,从而把被比较的词频向量的各项长度也融入计算之中,用以减小评估对数值不敏感的问题,得到更好地相似性评估。
注:由于本人依然不知道怎么上传图片或贴图,就无法粘贴公式了。想要看一下公式,可以点击链接:http://www.doc88.com/p-334742788857.html (修正余弦相似性公式在第2页)
3、相关相似性——基于皮尔森相关系数(Pearson correlation coefficient)的相似性计算方法
这种方法和修正的余弦相似性方法是基本相同的,只是它并不是对所有项进行相似性公式的计算,而是对两个词频向量共同评分的项目进行相似性公式的计算,也就是说,公式中的xi和yi均不为零。这样一来,同时会影响到项数n,从而使得基于皮尔森相关系数的相关相似性和修正的余弦相似性两种方法计算得到的相似性还是有区别的。

或

皮尔逊相关系数的变化范围为-1到1。 系数的值为1意味着X 和 Y可以很好的由直线方程来描述,所有的数据点都很好的落在一条直线上,且 Y 随着 X 的增加而增加。系数的值为−1意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。系数的值为0意味着两个变量之间没有线性关系。更一般的, 我们发现,当且仅当 Xi and Yi 均落在他们各自的均值的同一侧,
则(Xi − X)(Yi − Y) 的值为正。 也就是说,如果Xi 和 Yi 同时趋向于大于,
或同时趋向于小于他们各自的均值,则相关系数为正。 如果 Xi 和 Yi 趋向于落在他们均值的相反一侧,则相关系数为负。
总结
最后对三种相似度计算方法进行总结:
余弦相似性度量方法把用户评分看做一个向量,用向量的余弦夹角度量用户间的相似性,然而没有包含用户评分的统计特征;修正的余弦相似性方法在余弦相似性基础上,减去了用户对项目的平均评分,然而该方法更多的体现的是用户之间的相关性而非相似性。要注意的是,相关性和相似性是两个不同的概念,相似性反反映的是聚合特点,而相关性反映的是组合特点。相似相关性方法,依据双方共同评分的项目进行用户相似性评价,如果用户间的所有评分项目均为共同评分项目,那么相似相关性和修正的余弦相似性是等同的。用户对共同评分项目的评分确实能很好的体现用户的相似程度。但由于用户评分数据(即词频向量)往往具有极强的稀疏性,用户共同评分的项目极为稀少(即两个词频向量之间同时均不为零的属性太少了),这使得相似相关性在使用中有很大的局限性,在实际中几乎无法使用。
尊重版权!本文参考文献有:
1、《协同过滤推荐算法综述》 http://www.doc88.com/p-334742788857.html
2、《推荐算法综述》 http://www.doc88.com/p-980349680491.html
3、《余弦相似性》 http://xiao5461.blog.163.com/blog/static/22754562201211237567238/
----> 资源来自《数据挖掘:概念与技术(原书第3版)》
4、《维基百科——范数》 http://zh.wikipedia.org/wiki/%E8%8C%83%E6%95%B0
5、《余弦方法计算相似度算法实现》 http://blog.csdn.net/cscmaker/article/details/7990600
6、《余弦距离、欧氏距离和杰卡德相似性的度量的对比析》 http://www.cnblogs.com/chaosimple/archive/2013/06/28/3160839.html
7、《[生统笔记]皮尔森相关系数》 http://blog.sina.com.cn/s/blog_6a15f8d90100wsp8.html
8、《皮尔逊积矩相关系数》 http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E7%A9%8D%E5%B7%AE%E7%9B%B8%E9%97%9C%E4%BF%82%E6%95%B8
9、《维基百科——皮尔逊积矩相关系数》 http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E7%A9%8D%E5%B7%AE%E7%9B%B8%E9%97%9C%E4%BF%82%E6%95%B8
在协同过滤算法中,我提到的Customeri和DataSeti是已经有名称共识的,分别是user和item,即:
(1)基于用户的协同推荐算法是:基于(user-based)的协同推荐算法
(2)基于项目的协同推荐算法是:基于(item-based)的协同推荐算法
当然,这只是名称,为了方便交流更正过来,不能闭门造车嘛。不过在内容上,算法的理解和解释是没有错误的,无须担心。
好了,继续本次的学习和研究。
相似性计算是协同过滤算法中最关键的一步,传统的相似度计算方法有以下三种:
1、余弦相似性
要想讲明白余弦相似性,先要说一下数据,或者说文档的表示方法。借用一个定义“文档用数以千计的属性表示,每个记录文档中一个特定词(如关键词)或短语的频度”。那么就是说任何一个文档都可以看做有很多属性组成的,构建成数学模型就是一个具有N维的向量,则每个文档都可以被一个所谓的词频向量(term-frequency-vector)表示。举下面一个例子:
| 词频向量 | 属性 | ||||||||
| 文档 | 长度 | 宽度 | 高度 | 正视图 | 侧视图 | 俯视图 | 材料硬度 | 材料密度 | 材料熔点 |
| 文档1 | 5 | 3 | 1 | 1 | 1 | 0 | 4 | 2 | 7 |
| 文档2 | 0 | 0 | 5 | 0 | 1 | 0 | 2 | 0 | 5 |
| 文档3 | 7 | 6 | 1 | 0 | 0 | 0 | 0 | 2 | 0 |
| 文档4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 9 | 0 |
| 文档5 | 4 | 0 | 2 | 0 | 1 | 0 | 7 | 3 | 0 |
正如表格1.1所示,假设有一批金属材料的货物,任意从其中挑出五种金属材料进行数据统计与分析,得到表格如上所示,对于正视图、侧视图、俯视图,1和0代表有或者没有,其余各数据项的0代表那一项数据采集不全,或者对该文档的描述中没有这一项。我们可以看到,词频向量通常很长(因为每一个文档都可以从各种方面各个角度来描述),而且词频向量一般是稀疏的,数据中会有很多0项。那么我们如何判断文档之间的关系呢?我们需要一种度量,它关注两个文档确实共有的词(即不为0的属相项),以及这种词出现的频率,从而就可以对两个文档之间的关系进行界定。
这里就讲到余弦相似性了。余弦相似性是一种度量,它可以用来比较文档,或针对给定的查询词向量对文档排序。令x和y是两个待比较的向量,使用余弦度量作为相似性函数,定义如下所示:
(自己在word中用公式编辑器敲得公式粘贴不过来,截成图片也粘贴不过来,空的白色框框,先用别人的图,日后再研究)
其中,||x||是向量x=(x1,x1,...,xn)的欧几里得范数,定义为:
从概念上讲,它就是向量的长度。同理||y||就是向量y的欧几里得范数,计算方法相同。该度量计算向量x与y之间的夹角的余弦。余弦值在[-1,1]区间,越靠近0,证明匹配值越大、越相似;反之,越靠近1,证明匹配值越小、越不相关。补充一点知识:由于余弦相似性度量不遵守度量测度性质,因此它被称作非度量测度(nonmetric measure)。
公式 :
下面举一个例子来具体说明:
例:若有两个词频向量x,y分别是x=(5,0,3,0,2,0,0,2,0,0)和y=(3,0,2,0,1,1,0,1,0,1),请计算分析这两个词频向量x和y之间的相似性如何。当然,我们使用的是余弦相似性公式,应用公式我们得到:
通过计算我们可以得到词频向量x和y之间的相似性为0.94,那么同理,如果有一个词频向量集合,我们就可以通过余弦相似性公式进行两两之间的计算,从而得到与目标词频向量最相近、最类似的词频向量,用来推测该目标词频向量某一项属性的未知值了。
代码实现在网上找的:链接如下http://blog.csdn.net/cscmaker/article/details/7990600
(该代码未经本人调试检验,先留下来,以后研究)
2、修正余弦相似性
余弦相似性度量方法在衡量两个词频向量的计算中主要衡量的是两个向量之间的夹角问题,而并没有考虑到不同用户之间度量尺度的问题,也就是对数值不敏感,因此没法衡量每个维数上数值的差异,会导致这样一种情况:用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个
内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
所以修正余弦相似性就是在余弦相似性计算公式的基础上对每一项进行了与平均值的差值减法,从而把被比较的词频向量的各项长度也融入计算之中,用以减小评估对数值不敏感的问题,得到更好地相似性评估。
注:由于本人依然不知道怎么上传图片或贴图,就无法粘贴公式了。想要看一下公式,可以点击链接:http://www.doc88.com/p-334742788857.html (修正余弦相似性公式在第2页)
3、相关相似性——基于皮尔森相关系数(Pearson correlation coefficient)的相似性计算方法
这种方法和修正的余弦相似性方法是基本相同的,只是它并不是对所有项进行相似性公式的计算,而是对两个词频向量共同评分的项目进行相似性公式的计算,也就是说,公式中的xi和yi均不为零。这样一来,同时会影响到项数n,从而使得基于皮尔森相关系数的相关相似性和修正的余弦相似性两种方法计算得到的相似性还是有区别的。
或
皮尔逊相关系数的变化范围为-1到1。 系数的值为1意味着X 和 Y可以很好的由直线方程来描述,所有的数据点都很好的落在一条直线上,且 Y 随着 X 的增加而增加。系数的值为−1意味着所有的数据点都落在直线上,且 Y 随着 X 的增加而减少。系数的值为0意味着两个变量之间没有线性关系。更一般的, 我们发现,当且仅当 Xi and Yi 均落在他们各自的均值的同一侧,
则(Xi − X)(Yi − Y) 的值为正。 也就是说,如果Xi 和 Yi 同时趋向于大于,
或同时趋向于小于他们各自的均值,则相关系数为正。 如果 Xi 和 Yi 趋向于落在他们均值的相反一侧,则相关系数为负。
总结
最后对三种相似度计算方法进行总结:
余弦相似性度量方法把用户评分看做一个向量,用向量的余弦夹角度量用户间的相似性,然而没有包含用户评分的统计特征;修正的余弦相似性方法在余弦相似性基础上,减去了用户对项目的平均评分,然而该方法更多的体现的是用户之间的相关性而非相似性。要注意的是,相关性和相似性是两个不同的概念,相似性反反映的是聚合特点,而相关性反映的是组合特点。相似相关性方法,依据双方共同评分的项目进行用户相似性评价,如果用户间的所有评分项目均为共同评分项目,那么相似相关性和修正的余弦相似性是等同的。用户对共同评分项目的评分确实能很好的体现用户的相似程度。但由于用户评分数据(即词频向量)往往具有极强的稀疏性,用户共同评分的项目极为稀少(即两个词频向量之间同时均不为零的属性太少了),这使得相似相关性在使用中有很大的局限性,在实际中几乎无法使用。
尊重版权!本文参考文献有:
1、《协同过滤推荐算法综述》 http://www.doc88.com/p-334742788857.html
2、《推荐算法综述》 http://www.doc88.com/p-980349680491.html
3、《余弦相似性》 http://xiao5461.blog.163.com/blog/static/22754562201211237567238/
----> 资源来自《数据挖掘:概念与技术(原书第3版)》
4、《维基百科——范数》 http://zh.wikipedia.org/wiki/%E8%8C%83%E6%95%B0
5、《余弦方法计算相似度算法实现》 http://blog.csdn.net/cscmaker/article/details/7990600
6、《余弦距离、欧氏距离和杰卡德相似性的度量的对比析》 http://www.cnblogs.com/chaosimple/archive/2013/06/28/3160839.html
7、《[生统笔记]皮尔森相关系数》 http://blog.sina.com.cn/s/blog_6a15f8d90100wsp8.html
8、《皮尔逊积矩相关系数》 http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E7%A9%8D%E5%B7%AE%E7%9B%B8%E9%97%9C%E4%BF%82%E6%95%B8
9、《维基百科——皮尔逊积矩相关系数》 http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E7%A9%8D%E5%B7%AE%E7%9B%B8%E9%97%9C%E4%BF%82%E6%95%B8

相关文章推荐
- 对于Mahout__"推荐算法"的初步认识(2)
- 对Mahout_"推荐算法"的初步认识(6)
- 对Mahout_"推荐算法"的初步认识(5)_研讨篇
- 初步认识 "云计算" 概念
- 『转』也说"对程序语言的认识"
- SQL点滴6—“微软不认识闰年2月29日”&字符"N"的作用
- SQL点滴6—“微软不认识闰年2月29日”&字符"N"的作用
- 【LVL1_6_c】我对(一维数组名、二维数组名、&数组名 )的初步认识和理解。
- 对extern "C"的一点小认识
- js函数中 "闭包"概念的简单认识
- js "类"概念的简单认识
- python 初步认识弱引用 & 垃圾回收
- Mahout初步认识
- 对extern "C"的一点小认识
- java反射机制初步认识<三>注解(Annotation)的使用
- perceptivepixel PPI 55"触摸屏初步测试结果
- 对Mahout_“推荐算法”的初步认识(3)
- 对于Mahout_“推荐算法”的初步认识(1)
- java反射机制初步认识<四>注解+反射形成简易IOC
- sqlite数据库下载安装和初步操作和所遇到的问题near "sqlite3":syntax error