lucene的IndexReader的初始化过程
2014-07-31 12:03
399 查看
在使用Lucene时,有一条建议”不要频繁去打开关闭硬盘索引”。为什么会有这条建议?这就需要在IndexReader的实例化过程中找答案。先说一个结论“IndexReader的实例化过程是一个非常耗时的过程”。由于IndexReader只是一个抽象类,在调用代码:

真正得到的是StandardDirectoryReader对象。首先来看一下StandardDirectoryReader的类图:
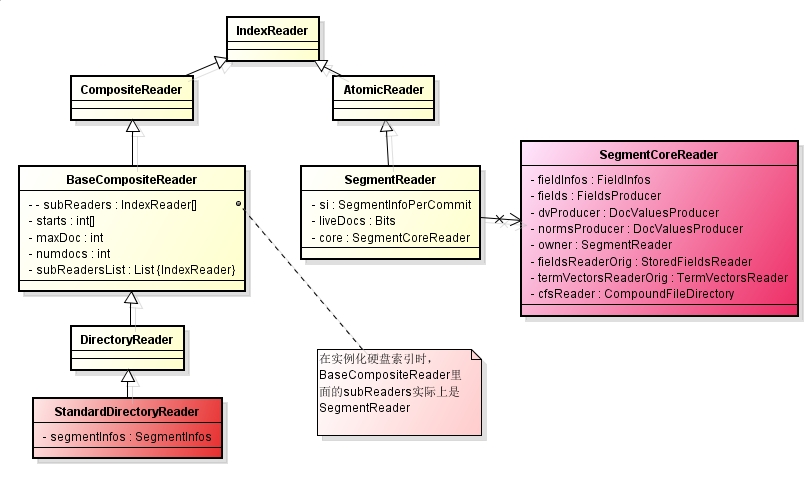
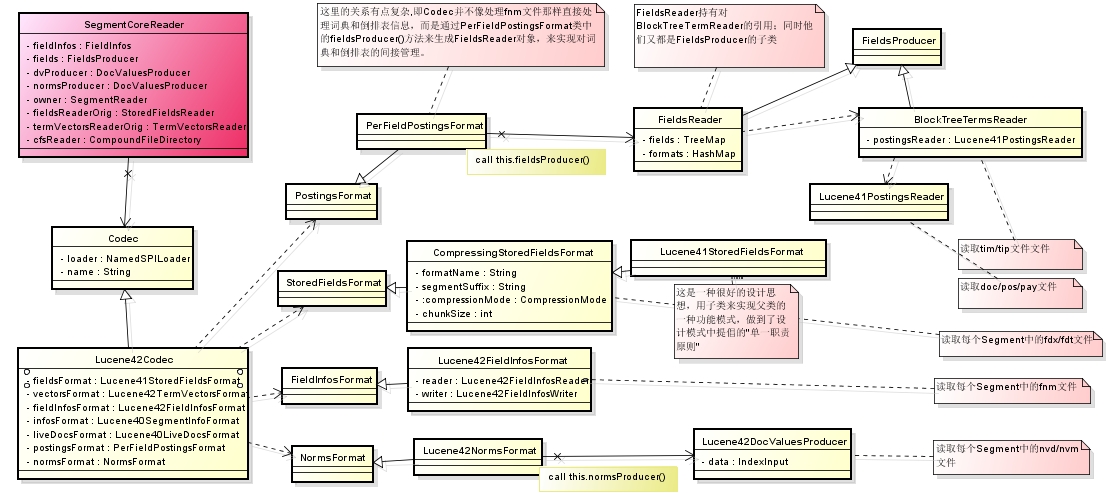
最重要的一个类就是SegmentCoreReader,它关联着整个segment中的所有文件。SegmentCoreReader是通过Codec来得到各个文件的处理对象,结构图如下:(可以在新标签页面中查看大图,会更清晰一些)
初始化过程的关键的JAVA代码如下:
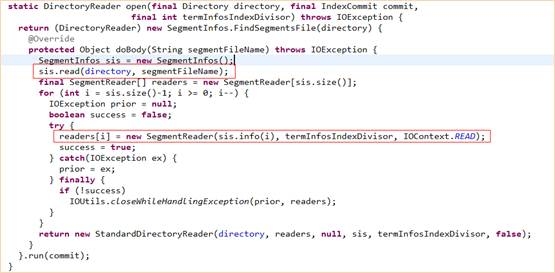
在SegmentInfos.FindSegmentsFile.run(commit)方法执行的过程中,会读取segments.gen文件,确定segments的最大的generation。在StandardDirectoryReader.open(Directory)方法执行的过程中,sis.read(directory,segmentFileName)在执行过程中步骤如下:
1、 通过segments_N的文件名得到N的最大值,即索引的最后CommitPoint。2、 对比segments.gen文件中写入的两个generation值,得到N的最大值。3、 从segments_N中读取到索引段的总体信息,并依次读取出所有si文件。4、 从每个_N.si 文件中读取索引段的相关信息(操作系统信息,Lucene版本信息,当前段管理的文件信息),形成SegmentInof对象,最后汇总得到SegmentInfos对象5、 用CRC32校验segments_N文件的正确性。
对于每个SegmentInfo对象,都会生成一个SegmentReader对象,即代码:readers[i]=new SegmentReader(sis.info(i),termInfosIndexDivisor,IOContext.READ);
这段代码就是读取每个segment的总体信息,比如docCount,totalTermFreq等信息,并把segment中的相关文件关联起来。在SegmentCoreReader类的构造函数里,把索引的核心文件都打开且读取了相关信息。
1、 依次读取每个段的文件信息。2、 从_N.fnm文件中读取每个Field的配置信息,得到相当段的所有FieldInfo,组成FieldInfos。3、 打开倒排表的相关文件(doc/pos/pay)4、 打开词典文件(tim/tip)5、 读取索引的统计信息(docFreq,tatalTermFreq,docCount等信息)6、 读取nvm/nvd文件,得到相关norms信息。7、 读取fdx/fdt文件。 通过这些初始化过程,就完成了IndexReader的初始化。当索引的数据很大时,这个加载过程就比较耗时了。所以“不要频繁去打开关闭硬盘索引”。
真正得到的是StandardDirectoryReader对象。首先来看一下StandardDirectoryReader的类图:
最重要的一个类就是SegmentCoreReader,它关联着整个segment中的所有文件。SegmentCoreReader是通过Codec来得到各个文件的处理对象,结构图如下:(可以在新标签页面中查看大图,会更清晰一些)
初始化过程的关键的JAVA代码如下:
在SegmentInfos.FindSegmentsFile.run(commit)方法执行的过程中,会读取segments.gen文件,确定segments的最大的generation。在StandardDirectoryReader.open(Directory)方法执行的过程中,sis.read(directory,segmentFileName)在执行过程中步骤如下:
1、 通过segments_N的文件名得到N的最大值,即索引的最后CommitPoint。2、 对比segments.gen文件中写入的两个generation值,得到N的最大值。3、 从segments_N中读取到索引段的总体信息,并依次读取出所有si文件。4、 从每个_N.si 文件中读取索引段的相关信息(操作系统信息,Lucene版本信息,当前段管理的文件信息),形成SegmentInof对象,最后汇总得到SegmentInfos对象5、 用CRC32校验segments_N文件的正确性。
对于每个SegmentInfo对象,都会生成一个SegmentReader对象,即代码:readers[i]=new SegmentReader(sis.info(i),termInfosIndexDivisor,IOContext.READ);
这段代码就是读取每个segment的总体信息,比如docCount,totalTermFreq等信息,并把segment中的相关文件关联起来。在SegmentCoreReader类的构造函数里,把索引的核心文件都打开且读取了相关信息。
1、 依次读取每个段的文件信息。2、 从_N.fnm文件中读取每个Field的配置信息,得到相当段的所有FieldInfo,组成FieldInfos。3、 打开倒排表的相关文件(doc/pos/pay)4、 打开词典文件(tim/tip)5、 读取索引的统计信息(docFreq,tatalTermFreq,docCount等信息)6、 读取nvm/nvd文件,得到相关norms信息。7、 读取fdx/fdt文件。 通过这些初始化过程,就完成了IndexReader的初始化。当索引的数据很大时,这个加载过程就比较耗时了。所以“不要频繁去打开关闭硬盘索引”。

相关文章推荐
- lucene的IndexReader的初始化过程
- lucene的IndexReader的初始化过程
- [ lucene FAQ ] IndexSearcher初始化,IndexSearcher(Directory dir)和IndexSearcher(IndexReader reader)有什么区别?到底使用那个更合理?
- lucene IndexReader reOpen 的彻底研究
- lucene用indexReader获取某个Document中的所有域的名字
- lucene管理IndexReader和IndexWriter的最佳实践
- 使用Lucene的IndexReader读取索引文件的信息
- 7、学习Lucene3.5之IndexReader和IndexWriter注意事项
- Lucene的IndexWriter在初始化的时候遇到IndexWriter is closed的问题
- Lucene中删除索引是用IndexWriter还是用IndexReader
- lucene索引_加权操作、对日期和数字进行索引、IndexReader的设计
- Lucene IndexReader,IndexWriter,IndexSearcher 缓存应用
- Lucene 4.6 的IndexReader的undeleteAll方法寻找
- Cache Lucene IndexReader with Apache Commons Pool
- 几种Lucene.Net打开IndexReader的方式
- 一步一步跟我学习lucene(7)---lucene搜索之IndexSearcher构建过程
- lucene笔记____IndexReader和IndexWriter注意事项
- lucene使用教程5 --常用类的对象之IndexReader
- Lucene六(IndexReader的设计)
- Java类初始化过程