hadoop SequenceFile介绍 大数据 存储
2014-07-30 17:18
507 查看
SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件。
基于压缩类型CompressType,共有三种
在SequenceFile里有Writer的实现,源码如下:
key value
100 One, two, buckle my shoe
99 Three, four, shut the door
98 Five, six, pick up sticks
97 Seven, eight, lay them straight
96 Nine, ten, a big fat hen
95 One, two, buckle my shoe
94 Three, four, shut the door
93 Five, six, pick up sticks
92 Seven, eight, lay them straight
91 Nine, ten, a big fat hen
90 One, two, buckle my shoe
89 Three, four, shut the door
88 Five, six, pick up sticks
87 Seven, eight, lay them straight
86 Nine, ten, a big fat hen
85 One, two, buckle my shoe
84 Three, four, shut the door
83 Five, six, pick up sticks
82 Seven, eight, lay them straight
81 Nine, ten, a big fat hen
80 One, two, buckle my shoe
79 Three, four, shut the door
78 Five, six, pick up sticks
77 Seven, eight, lay them straight
76 Nine, ten, a big fat hen
75 One, two, buckle my shoe
74 Three, four, shut the door
73 Five, six, pick up sticks
72 Seven, eight, lay them straight
71 Nine, ten, a big fat hen
70 One, two, buckle my shoe
69 Three, four, shut the door
68 Five, six, pick up sticks
67 Seven, eight, lay them straight
66 Nine, ten, a big fat hen
65 One, two, buckle my shoe
64 Three, four, shut the door
63 Five, six, pick up sticks
62 Seven, eight, lay them straight
61 Nine, ten, a big fat hen
60 One, two, buckle my shoe
59 Three, four, shut the door
58 Five, six, pick up sticks
57 Seven, eight, lay them straight
56 Nine, ten, a big fat hen
55 One, two, buckle my shoe
54 Three, four, shut the door
53 Five, six, pick up sticks
52 Seven, eight, lay them straight
51 Nine, ten, a big fat hen
50 One, two, buckle my shoe
49 Three, four, shut the door
48 Five, six, pick up sticks
47 Seven, eight, lay them straight
46 Nine, ten, a big fat hen
45 One, two, buckle my shoe
44 Three, four, shut the door
43 Five, six, pick up sticks
42 Seven, eight, lay them straight
41 Nine, ten, a big fat hen
40 One, two, buckle my shoe
39 Three, four, shut the door
38 Five, six, pick up sticks
37 Seven, eight, lay them straight
36 Nine, ten, a big fat hen
35 One, two, buckle my shoe
34 Three, four, shut the door
33 Five, six, pick up sticks
32 Seven, eight, lay them straight
31 Nine, ten, a big fat hen
30 One, two, buckle my shoe
29 Three, four, shut the door
28 Five, six, pick up sticks
27 Seven, eight, lay them straight
26 Nine, ten, a big fat hen
25 One, two, buckle my shoe
24 Three, four, shut the door
23 Five, six, pick up sticks
22 Seven, eight, lay them straight
21 Nine, ten, a big fat hen
20 One, two, buckle my shoe
19 Three, four, shut the door
18 Five, six, pick up sticks
17 Seven, eight, lay them straight
16 Nine, ten, a big fat hen
15 One, two, buckle my shoe
14 Three, four, shut the door
13 Five, six, pick up sticks
12 Seven, eight, lay them straight
11 Nine, ten, a big fat hen
10 One, two, buckle my shoe
9 Three, four, shut the door
8 Five, six, pick up sticks
7 Seven, eight, lay them straight
6 Nine, ten, a big fat hen
5 One, two, buckle my shoe
4 Three, four, shut the door
3 Five, six, pick up sticks
2 Seven, eight, lay them straight
1 Nine, ten, a big fat hen
把以上java 打成jar,执行hadoop jar sfile.jar /test/numbers.seq 1 1代表不压缩
hadoop fs -get hdfs:///test/numbers1.seq /usr/test/ 取出刚刚生成的文件,我们用UE打开看一下
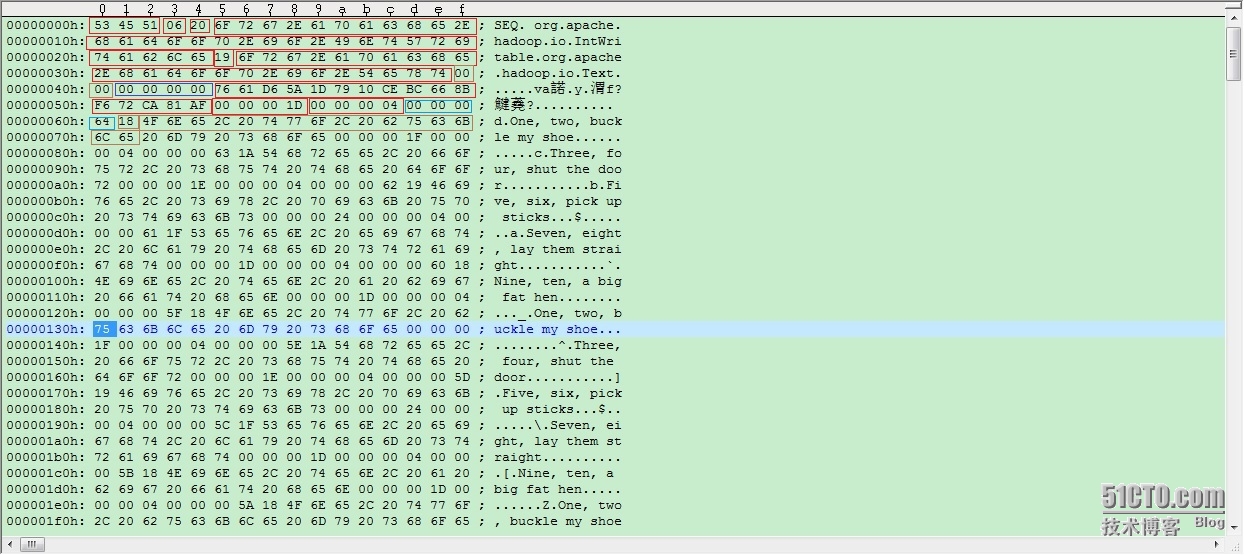
[b]0x53 0x45 0x51[/b]
这是SequenceFile Format的magic header「SEQ」,用来区别文本是否是「SequenceFile Format」。
0x06
版本编号,目前最新版为「SEQ6」
以上代码源码如下:
这部份是keyClassName(Key的类名),而第1个Byte(0x20)用来表示此字串的长度,此范例为org.apache.hadoop.io.IntWritable
以上代码源码如下:
这部份是valueClassName(Value的类名),第1个Byte(0x19)也是用来表示此字串的长度,此范例为org.apache.hadoop.io.BytesWritable
0x00
是否compression?「0x00」=否 (此为Boolean所以佔1个Byte)
0x00
是否blockCompression?「0x00」=否(此为Boolean所以佔1个Byte)
metadata,此范例沒有包含任何metadata, 所以输出「0x00 0x00 0x00 0x00」
0x76 0x61 ..... 0xAF
sync标记,用来表示一个「Header」的结束。
SequenceFile Headerversion - 3 bytes of magic header SEQ, followed by 1 byte of actual
version number (e.g. SEQ4 or SEQ6)
keyClassName -key class
valueClassName - value class
compression - A boolean which specifies if compression is turned on for
keys/values in this file.
blockCompression - A boolean which specifies if block-compression is turned
on for keys/values in this file.
compression codec -
compression of keys and/or values (if compression is enabled).
metadata -
sync - A sync marker to denote end of the header.
接下去我们看一下数据存储格式:
0x00 0x00 0x00 0x1D
整个Record的size ,一个Record包含「Key、Value」。此处为29个字节,因为 key=100 占4个字节,value=One, two, buckle my shoe 占24字节 还有一个字节存了value的长度 所以 29字节总共。
0x00 0x00 0x00 0x04
Key內容的size~ (此为Int所以占4个字节)
0x00 0x00 0x00 0x64
Key的内容,此处为100,那十六进制就是64
0x18value内容的size,此处是One, two, buckle my shoe,长度24 所以十六进制就是180x4F 0X6E....0x65value的内容One, two, buckle my shoe以上代码源代码如下:
当数据达到一个阀值,会写sync,写sync就是调用checkAndWriteSync(); 源码如下:
SYNC_INTERVAL定义如下:
SequeceFile 无压缩图示如下:
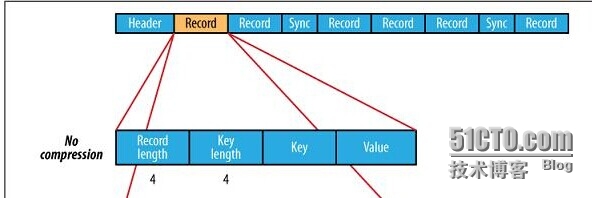
可见格式如下:
Uncompressed SequenceFile FormatHeader
Record
Record length
Key length
Key
Value
接下去我们看一下RecordCompressWriter
values.
执行hadoop jar sfile.jar /test/numbers2.seq 2 2代表使用RecordCompressWriter压缩
同样我们用UE看一下生成的文件:
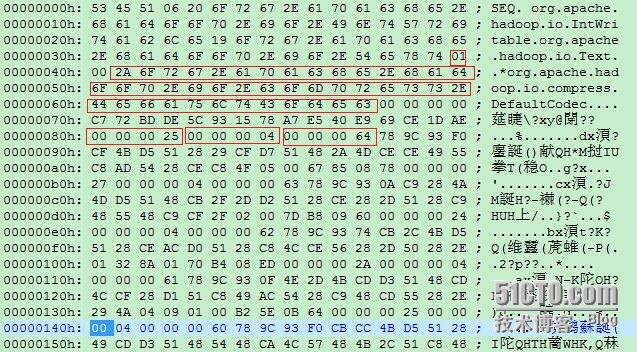
可见表头和不压缩的基本一致,有些小区别如下:
0x01
代表使用了压缩
0x2A 0x6F ....0x63
使用的压缩类org.apache.hadoop.io.compress.DefaultCodec
0x00 ...0x25
整个Record的size ,为37,为啥比不压缩占用的字节更多?
0x00 0x00 0x00 0x04Key內容的size~ (此为Int所以占4个字节)0x00 0x00 0x00 0x64Key的内容,此处为100,那十六进制就是64 可见key没有压缩以上源代码如下:
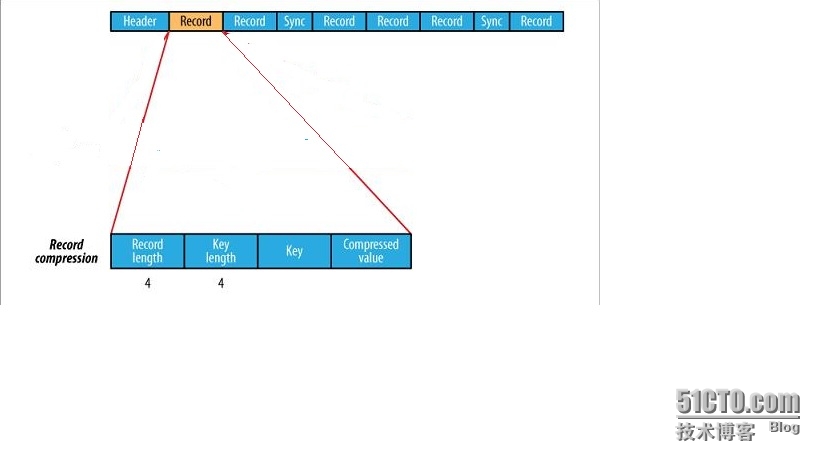
可见格式如下:Record-Compressed SequenceFile FormatHeader
Record
Record length
Key length
Key
Compressed Value
接下去我们看一下BlockCompressWriter
values are collected in 'blocks' separately and compressed. The size of the
'block' is configurable.
执行hadoop jar sfile.jar /test/numbers3.seq 3 3代表使用BlockCompressWriter压缩同样我们用UE看一下生成的文件:
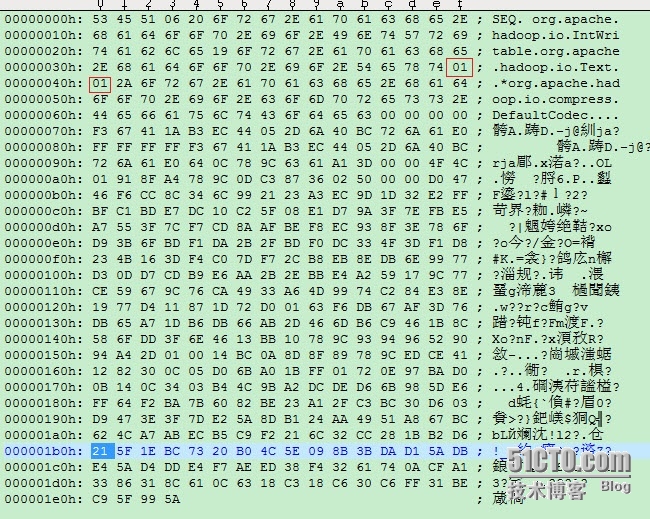
可见表头和不压缩的基本一致,有些小区别如下:0x01代表使用了压缩0x01代表使用了block压缩对于block压缩的源代码如下:
WritableUtils.writeVInt(keyLenBuffer, keyLength);
WritableUtils.writeVInt(valLenBuffer, valLength);
int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
if (currentBlockSize >= compressionBlockSize) {
sync();
}
compressionBlockSize = conf.getInt("io.seqfile.compress.blocksize", 1000000);
当超过compressionBlockSize是会调用sync,我们来看看sync的源码,如下:
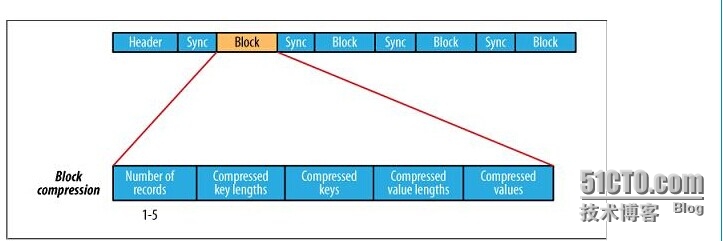
可见格式如下:
Block-Compressed SequenceFile FormatHeader
Record Block
Uncompressed number of records in the block
Compressed key-lengths block-size
Compressed key-lengths block
Compressed keys block-size
Compressed keys block
Compressed value-lengths block-size
Compressed value-lengths block
Compressed values block-size
Compressed values block
A sync-marker every block.
本文出自 “软件开发” 博客,请务必保留此出处http://tangjj.blog.51cto.com/1848040/1532915
基于压缩类型CompressType,共有三种
SequenceFile
Writer:
public static enum CompressionType {
/** 不压缩 */
NONE,
/** 只压缩value */
RECORD,
/** 压缩很多记录的key/value成一块 */
BLOCK
}There are three SequenceFile
Writers based on the CompressType used to compress key/value pairs:
1、Writer: Uncompressed records.
在SequenceFile里有Writer的实现,源码如下:
public static class Writer implements java.io.Closeable, Syncable
/** Write and flush the file header. */
private void writeFileHeader()
throws IOException {
out.write(VERSION);
Text.writeString(out, keyClass.getName());
Text.writeString(out, valClass.getName());
out.writeBoolean(this.isCompressed());
out.writeBoolean(this.isBlockCompressed());
if (this.isCompressed()) {
Text.writeString(out, (codec.getClass()).getName());
}
this.metadata.write(out);
out.write(sync); // write the sync bytes
out.flush(); // flush header
}首先SequenceFile文件有个表头,以上是写表头的代码,我们以一个实例结合代码来看一下表头的组成。
package demo;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.CompressionType;
import org.apache.hadoop.io.Text;
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe",
"Three, four, shut the door", "Five, six, pick up sticks",
"Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://xxx.xxx.xxx.xx:9000");
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
String compressType = args[1];
System.out.println("compressType "+compressType);
// Writer : Uncompressed records.
if(compressType.equals("1") ){
System.out.println("compress none");
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(),value.getClass(),CompressionType.NONE);
}else if(compressType .equals("2") ){
System.out.println("compress record");
//RecordCompressWriter : Record-compressed files, only compress values.
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(),value.getClass(),CompressionType.RECORD);
}else if(compressType.equals("3") ){
System.out.println("compress block");
// BlockCompressWriter : Block-compressed files, both keys & values are collected in 'blocks' separately and compressed. The size of the 'block' is configurable.
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(),value.getClass(),CompressionType.BLOCK);
}
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key,value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}存入的文本文件内容如下:key value
100 One, two, buckle my shoe
99 Three, four, shut the door
98 Five, six, pick up sticks
97 Seven, eight, lay them straight
96 Nine, ten, a big fat hen
95 One, two, buckle my shoe
94 Three, four, shut the door
93 Five, six, pick up sticks
92 Seven, eight, lay them straight
91 Nine, ten, a big fat hen
90 One, two, buckle my shoe
89 Three, four, shut the door
88 Five, six, pick up sticks
87 Seven, eight, lay them straight
86 Nine, ten, a big fat hen
85 One, two, buckle my shoe
84 Three, four, shut the door
83 Five, six, pick up sticks
82 Seven, eight, lay them straight
81 Nine, ten, a big fat hen
80 One, two, buckle my shoe
79 Three, four, shut the door
78 Five, six, pick up sticks
77 Seven, eight, lay them straight
76 Nine, ten, a big fat hen
75 One, two, buckle my shoe
74 Three, four, shut the door
73 Five, six, pick up sticks
72 Seven, eight, lay them straight
71 Nine, ten, a big fat hen
70 One, two, buckle my shoe
69 Three, four, shut the door
68 Five, six, pick up sticks
67 Seven, eight, lay them straight
66 Nine, ten, a big fat hen
65 One, two, buckle my shoe
64 Three, four, shut the door
63 Five, six, pick up sticks
62 Seven, eight, lay them straight
61 Nine, ten, a big fat hen
60 One, two, buckle my shoe
59 Three, four, shut the door
58 Five, six, pick up sticks
57 Seven, eight, lay them straight
56 Nine, ten, a big fat hen
55 One, two, buckle my shoe
54 Three, four, shut the door
53 Five, six, pick up sticks
52 Seven, eight, lay them straight
51 Nine, ten, a big fat hen
50 One, two, buckle my shoe
49 Three, four, shut the door
48 Five, six, pick up sticks
47 Seven, eight, lay them straight
46 Nine, ten, a big fat hen
45 One, two, buckle my shoe
44 Three, four, shut the door
43 Five, six, pick up sticks
42 Seven, eight, lay them straight
41 Nine, ten, a big fat hen
40 One, two, buckle my shoe
39 Three, four, shut the door
38 Five, six, pick up sticks
37 Seven, eight, lay them straight
36 Nine, ten, a big fat hen
35 One, two, buckle my shoe
34 Three, four, shut the door
33 Five, six, pick up sticks
32 Seven, eight, lay them straight
31 Nine, ten, a big fat hen
30 One, two, buckle my shoe
29 Three, four, shut the door
28 Five, six, pick up sticks
27 Seven, eight, lay them straight
26 Nine, ten, a big fat hen
25 One, two, buckle my shoe
24 Three, four, shut the door
23 Five, six, pick up sticks
22 Seven, eight, lay them straight
21 Nine, ten, a big fat hen
20 One, two, buckle my shoe
19 Three, four, shut the door
18 Five, six, pick up sticks
17 Seven, eight, lay them straight
16 Nine, ten, a big fat hen
15 One, two, buckle my shoe
14 Three, four, shut the door
13 Five, six, pick up sticks
12 Seven, eight, lay them straight
11 Nine, ten, a big fat hen
10 One, two, buckle my shoe
9 Three, four, shut the door
8 Five, six, pick up sticks
7 Seven, eight, lay them straight
6 Nine, ten, a big fat hen
5 One, two, buckle my shoe
4 Three, four, shut the door
3 Five, six, pick up sticks
2 Seven, eight, lay them straight
1 Nine, ten, a big fat hen
把以上java 打成jar,执行hadoop jar sfile.jar /test/numbers.seq 1 1代表不压缩
hadoop fs -get hdfs:///test/numbers1.seq /usr/test/ 取出刚刚生成的文件,我们用UE打开看一下
[b]0x53 0x45 0x51[/b]
这是SequenceFile Format的magic header「SEQ」,用来区别文本是否是「SequenceFile Format」。
0x06
版本编号,目前最新版为「SEQ6」
以上代码源码如下:
private static byte[] VERSION = new byte[] {
(byte)'S', (byte)'E', (byte)'Q', VERSION_WITH_METADATA
};
out.write(VERSION);0x20 0x65........0x65这部份是keyClassName(Key的类名),而第1个Byte(0x20)用来表示此字串的长度,此范例为org.apache.hadoop.io.IntWritable
以上代码源码如下:
Text.writeString(out, keyClass.getName());0x19 0x6F ..... 0x74
这部份是valueClassName(Value的类名),第1个Byte(0x19)也是用来表示此字串的长度,此范例为org.apache.hadoop.io.BytesWritable
Text.writeString(out, valClass.getName());
0x00
是否compression?「0x00」=否 (此为Boolean所以佔1个Byte)
0x00
是否blockCompression?「0x00」=否(此为Boolean所以佔1个Byte)
out.writeBoolean(this.isCompressed()); out.writeBoolean(this.isBlockCompressed());如果是压缩的话接下去还会写压缩类,此范例没有压缩所以没有此类名的写入,源码如下:
if (this.isCompressed()) {
Text.writeString(out, (codec.getClass()).getName());
}0x00 0x00 0x00 0x00metadata,此范例沒有包含任何metadata, 所以输出「0x00 0x00 0x00 0x00」
this.metadata.write(out);
0x76 0x61 ..... 0xAF
sync标记,用来表示一个「Header」的结束。
byte[] sync; // 16 random bytes
{
try {
MessageDigest digester = MessageDigest.getInstance("MD5");
long time = Time.now();
digester.update((new UID()+"@"+time).getBytes());
sync = digester.digest();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
out.write(sync);至此头部文件写入完毕,可见头部的格式可以归纳如下:SequenceFile Headerversion - 3 bytes of magic header SEQ, followed by 1 byte of actual
version number (e.g. SEQ4 or SEQ6)
keyClassName -key class
valueClassName - value class
compression - A boolean which specifies if compression is turned on for
keys/values in this file.
blockCompression - A boolean which specifies if block-compression is turned
on for keys/values in this file.
compression codec -
CompressionCodecclass which is used for
compression of keys and/or values (if compression is enabled).
metadata -
Metadatafor this file.
sync - A sync marker to denote end of the header.
接下去我们看一下数据存储格式:
0x00 0x00 0x00 0x1D
整个Record的size ,一个Record包含「Key、Value」。此处为29个字节,因为 key=100 占4个字节,value=One, two, buckle my shoe 占24字节 还有一个字节存了value的长度 所以 29字节总共。
0x00 0x00 0x00 0x04
Key內容的size~ (此为Int所以占4个字节)
0x00 0x00 0x00 0x64
Key的内容,此处为100,那十六进制就是64
0x18value内容的size,此处是One, two, buckle my shoe,长度24 所以十六进制就是180x4F 0X6E....0x65value的内容One, two, buckle my shoe以上代码源代码如下:
public synchronized void append(Object key, Object val){
.......
// Write the record out
checkAndWriteSync(); // sync
out.writeInt(buffer.getLength()); // total record length
out.writeInt(keyLength); // key portion length
out.write(buffer.getData(), 0, buffer.getLength()); // data
}当数据达到一个阀值,会写sync,写sync就是调用checkAndWriteSync(); 源码如下:
synchronized void checkAndWriteSync() throws IOException {
if (sync != null &&
out.getPos() >= lastSyncPos+SYNC_INTERVAL) { // time to emit sync
sync();
}
}SYNC_INTERVAL定义如下:
private static final int SYNC_HASH_SIZE = 16; // number of bytes in hash private static final int SYNC_SIZE = 4+SYNC_HASH_SIZE; // escape + hash /** The number of bytes between sync points.*/ public static final int SYNC_INTERVAL = 100*SYNC_SIZE;可见每2000byte会写一个sync
SequeceFile 无压缩图示如下:
可见格式如下:
Uncompressed SequenceFile FormatHeader
Record
Record length
Key length
Key
Value
接下去我们看一下RecordCompressWriter
2、RecordCompressWriter: Record-compressed files, only compress
values.
执行hadoop jar sfile.jar /test/numbers2.seq 2 2代表使用RecordCompressWriter压缩
同样我们用UE看一下生成的文件:
可见表头和不压缩的基本一致,有些小区别如下:
0x01
代表使用了压缩
0x2A 0x6F ....0x63
使用的压缩类org.apache.hadoop.io.compress.DefaultCodec
0x00 ...0x25
整个Record的size ,为37,为啥比不压缩占用的字节更多?
0x00 0x00 0x00 0x04Key內容的size~ (此为Int所以占4个字节)0x00 0x00 0x00 0x64Key的内容,此处为100,那十六进制就是64 可见key没有压缩以上源代码如下:
@Override
@SuppressWarnings("unchecked")
public synchronized void append(Object key, Object val)
throws IOException {
if (key.getClass() != keyClass)
throw new IOException("wrong key class: "+key.getClass().getName()
+" is not "+keyClass);
if (val.getClass() != valClass)
throw new IOException("wrong value class: "+val.getClass().getName()
+" is not "+valClass);
buffer.reset();
// Append the 'key'
keySerializer.serialize(key);
int keyLength = buffer.getLength();
if (keyLength < 0)
throw new IOException("negative length keys not allowed: " + key);
// Compress 'value' and append it
deflateFilter.resetState();
compressedValSerializer.serialize(val);
deflateOut.flush();
deflateFilter.finish();
// Write the record out
checkAndWriteSync(); // sync
out.writeInt(buffer.getLength()); // total record length
out.writeInt(keyLength); // key portion length
out.write(buffer.getData(), 0, buffer.getLength()); // data
}SequeceFile 压缩value图示如下:可见格式如下:Record-Compressed SequenceFile FormatHeader
Record
Record length
Key length
Key
Compressed Value
接下去我们看一下BlockCompressWriter
3、BlockCompressWriter: Block-compressed files, both keys &
values are collected in 'blocks' separately and compressed. The size of the
'block' is configurable.
执行hadoop jar sfile.jar /test/numbers3.seq 3 3代表使用BlockCompressWriter压缩同样我们用UE看一下生成的文件:
可见表头和不压缩的基本一致,有些小区别如下:0x01代表使用了压缩0x01代表使用了block压缩对于block压缩的源代码如下:
public synchronized void append(Object key, Object val)
throws IOException {
if (key.getClass() != keyClass)
throw new IOException("wrong key class: "+key+" is not "+keyClass);
if (val.getClass() != valClass)
throw new IOException("wrong value class: "+val+" is not "+valClass);
// Save key/value into respective buffers
int oldKeyLength = keyBuffer.getLength();
keySerializer.serialize(key);
int keyLength = keyBuffer.getLength() - oldKeyLength;
if (keyLength < 0)
throw new IOException("negative length keys not allowed: " + key);
WritableUtils.writeVInt(keyLenBuffer, keyLength);
int oldValLength = valBuffer.getLength();
uncompressedValSerializer.serialize(val);
int valLength = valBuffer.getLength() - oldValLength;
WritableUtils.writeVInt(valLenBuffer, valLength);
// Added another key/value pair
++noBufferedRecords;
// Compress and flush?
int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
if (currentBlockSize >= compressionBlockSize) {
sync();
}
} 其中,可见没调用一次append,就会相应累加keyLenBuffer和valLenBuffer的长度WritableUtils.writeVInt(keyLenBuffer, keyLength);
WritableUtils.writeVInt(valLenBuffer, valLength);
int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
if (currentBlockSize >= compressionBlockSize) {
sync();
}
compressionBlockSize = conf.getInt("io.seqfile.compress.blocksize", 1000000);
当超过compressionBlockSize是会调用sync,我们来看看sync的源码,如下:
public synchronized void sync() throws IOException {
if (noBufferedRecords > 0) {
super.sync();
// No. of records
WritableUtils.writeVInt(out, noBufferedRecords);
// Write 'keys' and lengths
writeBuffer(keyLenBuffer);
writeBuffer(keyBuffer);
// Write 'values' and lengths
writeBuffer(valLenBuffer);
writeBuffer(valBuffer);
// Flush the file-stream
out.flush();
// Reset internal states
keyLenBuffer.reset();
keyBuffer.reset();
valLenBuffer.reset();
valBuffer.reset();
noBufferedRecords = 0;
}Sequenc File ,块压缩图示如下:可见格式如下:
Block-Compressed SequenceFile FormatHeader
Record Block
Uncompressed number of records in the block
Compressed key-lengths block-size
Compressed key-lengths block
Compressed keys block-size
Compressed keys block
Compressed value-lengths block-size
Compressed value-lengths block
Compressed values block-size
Compressed values block
A sync-marker every block.
本文出自 “软件开发” 博客,请务必保留此出处http://tangjj.blog.51cto.com/1848040/1532915

相关文章推荐
- hadoop SequenceFile介绍 大数据 存储
- hadoop SequenceFile介绍 大数据 存储
- Hive使用SequenceFile存储数据
- hadoop SequenceFile介绍
- Hadoop SequenceFile数据结构介绍及读写
- 数据的存储-NSKeyedArchiver和write to file介绍
- 环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
- Hadoop Core 学习笔记(一) SequenceFile文件写入和读取Writable数据
- Hadoop中数据序列化的常用方式:SequenceFile, Avro, Thrift, ProtoBuff -- 待完善
- Andrid数据存储体系简单介绍
- Android数据的四种存储方式SharedPreferences、SQLite、Content Provider和File (二) —— SQLite
- Android数据的四种存储方式SharedPreferences、SQLite、Content Provider和File (二) —— SQLite
- Android数据的四种存储方式SharedPreferences、SQLite、Content Provider和File (四) —— ContentProvider
- Android数据的四种存储方式SharedPreferences、SQLite、Content Provider和File (三) —— SharePreferences
- 20、从头学Android之Android的数据存储--File
- Android数据存储之File
- Android中使用File文件进行数据存储
- 从头学Android之Android的数据存储--File
- 请介绍下Android的数据存储方式
- Linux下对C语言数据类型存储的介绍