Lucene 入门实例
2014-07-26 17:57
399 查看
项目结构
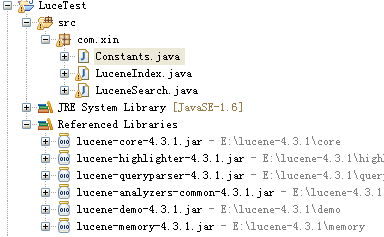
constans.java 是常量类
LuceneIndex.java 建立索引类
LuceneSearch.java 搜索类
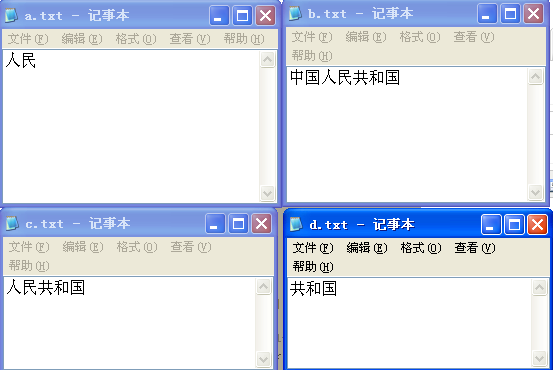
数据文件:

[java] view
plaincopy
package com.xin;
public class Constants {
public final static String INDEX_FILE_PATH = "e:\\lucene\\test"; //索引的文件的存放路径
public final static String INDEX_STORE_PATH = "e:\\lucene\\index"; //索引的存放位置
}
[java] view
plaincopy
package com.xin;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author chongxin
* @since 2013/6/19
* @version Lucene 4.3.1
* */
public class LuceneIndex {
// 索引器
private IndexWriter writer = null;
public LuceneIndex() {
try {
//索引文件的保存位置
Directory dir = FSDirectory.open(new File(Constants.INDEX_STORE_PATH));
//分析器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
//配置类
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40,analyzer);
iwc.setOpenMode(OpenMode.CREATE);//创建模式 OpenMode.CREATE_OR_APPEND 添加模式
writer = new IndexWriter(dir, iwc);
} catch (Exception e) {
e.printStackTrace();
}
}
// 将要建立索引的文件构造成一个Document对象,并添加一个域"content"
private Document getDocument(File f) throws Exception {
Document doc = new Document();
FileInputStream is = new FileInputStream(f);
Reader reader = new BufferedReader(new InputStreamReader(is));
//字符串 StringField LongField TextField
Field pathField = new StringField("path", f.getAbsolutePath(),Field.Store.YES);
Field contenField = new TextField("contents", reader);
//添加字段
doc.add(contenField);
doc.add(pathField);
return doc;
}
public void writeToIndex() throws Exception {
File folder = new File(Constants.INDEX_FILE_PATH);
if (folder.isDirectory()) {
String[] files = folder.list();
for (int i = 0; i < files.length; i++) {
File file = new File(folder, files[i]);
Document doc = getDocument(file);
System.out.println("正在建立索引 : " + file + "");
writer.addDocument(doc);
}
}
}
public void close() throws Exception {
writer.close();
}
public static void main(String[] args) throws Exception {
// 声明一个对象
LuceneIndex indexer = new LuceneIndex();
// 建立索引
Date start = new Date();
indexer.writeToIndex();
Date end = new Date();
System.out.println("建立索引用时" + (end.getTime() - start.getTime()) + "毫秒");
indexer.close();
}
}
执行结果:
[java] view
plaincopy
正在建立索引 : e:\lucene\test\a.txt
正在建立索引 : e:\lucene\test\b.txt
正在建立索引 : e:\lucene\test\c.txt
正在建立索引 : e:\lucene\test\d.txt
建立索引用时109毫秒
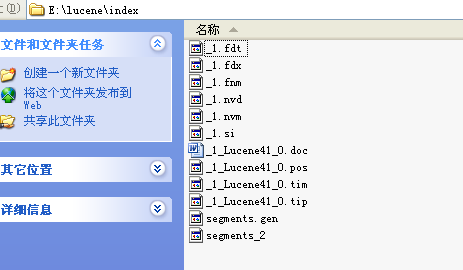
生成的索引文件:
查找:
[java] view
plaincopy
package com.xin;
import java.io.File;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author chongxin
* @since 2013/6/19
* @version Lucene 4.3.1
* */
public class LuceneSearch {
// 声明一个IndexSearcher对象
private IndexSearcher searcher = null;
// 声明一个Query对象
private Query query = null;
private String field = "contents";
public LuceneSearch() {
try {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(Constants.INDEX_STORE_PATH)));
searcher = new IndexSearcher(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
//返回查询结果
public final TopDocs search(String keyword) {
System.out.println("正在检索关键字 : " + keyword);
try {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
QueryParser parser = new QueryParser(Version.LUCENE_40, field,analyzer);
// 将关键字包装成Query对象
query = parser.parse(keyword);
Date start = new Date();
TopDocs results = searcher.search(query, 5 * 2);
Date end = new Date();
System.out.println("检索完成,用时" + (end.getTime() - start.getTime())
+ "毫秒");
return results;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//打印结果
public void printResult(TopDocs results) {
ScoreDoc[] h = results.scoreDocs;
if (h.length == 0) {
System.out.println("对不起,没有找到您要的结果。");
} else {
for (int i = 0; i < h.length; i++) {
try {
Document doc = searcher.doc(h[i].doc);
System.out.print("这是第" + i + "个检索到的结果,文件名为:");
System.out.println(doc.get("path"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
System.out.println("--------------------------");
}
public static void main(String[] args) throws Exception {
LuceneSearch test = new LuceneSearch();
TopDocs h = null;
h = test.search("中国");
test.printResult(h);
h = test.search("人民");
test.printResult(h);
h = test.search("共和国");
test.printResult(h);
}
}

转载自:http://blog.csdn.net/perfect2011/article/details/9128323
constans.java 是常量类
LuceneIndex.java 建立索引类
LuceneSearch.java 搜索类
数据文件:
[java] view
plaincopy
package com.xin;
public class Constants {
public final static String INDEX_FILE_PATH = "e:\\lucene\\test"; //索引的文件的存放路径
public final static String INDEX_STORE_PATH = "e:\\lucene\\index"; //索引的存放位置
}
[java] view
plaincopy
package com.xin;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author chongxin
* @since 2013/6/19
* @version Lucene 4.3.1
* */
public class LuceneIndex {
// 索引器
private IndexWriter writer = null;
public LuceneIndex() {
try {
//索引文件的保存位置
Directory dir = FSDirectory.open(new File(Constants.INDEX_STORE_PATH));
//分析器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
//配置类
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40,analyzer);
iwc.setOpenMode(OpenMode.CREATE);//创建模式 OpenMode.CREATE_OR_APPEND 添加模式
writer = new IndexWriter(dir, iwc);
} catch (Exception e) {
e.printStackTrace();
}
}
// 将要建立索引的文件构造成一个Document对象,并添加一个域"content"
private Document getDocument(File f) throws Exception {
Document doc = new Document();
FileInputStream is = new FileInputStream(f);
Reader reader = new BufferedReader(new InputStreamReader(is));
//字符串 StringField LongField TextField
Field pathField = new StringField("path", f.getAbsolutePath(),Field.Store.YES);
Field contenField = new TextField("contents", reader);
//添加字段
doc.add(contenField);
doc.add(pathField);
return doc;
}
public void writeToIndex() throws Exception {
File folder = new File(Constants.INDEX_FILE_PATH);
if (folder.isDirectory()) {
String[] files = folder.list();
for (int i = 0; i < files.length; i++) {
File file = new File(folder, files[i]);
Document doc = getDocument(file);
System.out.println("正在建立索引 : " + file + "");
writer.addDocument(doc);
}
}
}
public void close() throws Exception {
writer.close();
}
public static void main(String[] args) throws Exception {
// 声明一个对象
LuceneIndex indexer = new LuceneIndex();
// 建立索引
Date start = new Date();
indexer.writeToIndex();
Date end = new Date();
System.out.println("建立索引用时" + (end.getTime() - start.getTime()) + "毫秒");
indexer.close();
}
}
执行结果:
[java] view
plaincopy
正在建立索引 : e:\lucene\test\a.txt
正在建立索引 : e:\lucene\test\b.txt
正在建立索引 : e:\lucene\test\c.txt
正在建立索引 : e:\lucene\test\d.txt
建立索引用时109毫秒
生成的索引文件:
查找:
[java] view
plaincopy
package com.xin;
import java.io.File;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author chongxin
* @since 2013/6/19
* @version Lucene 4.3.1
* */
public class LuceneSearch {
// 声明一个IndexSearcher对象
private IndexSearcher searcher = null;
// 声明一个Query对象
private Query query = null;
private String field = "contents";
public LuceneSearch() {
try {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(Constants.INDEX_STORE_PATH)));
searcher = new IndexSearcher(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
//返回查询结果
public final TopDocs search(String keyword) {
System.out.println("正在检索关键字 : " + keyword);
try {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
QueryParser parser = new QueryParser(Version.LUCENE_40, field,analyzer);
// 将关键字包装成Query对象
query = parser.parse(keyword);
Date start = new Date();
TopDocs results = searcher.search(query, 5 * 2);
Date end = new Date();
System.out.println("检索完成,用时" + (end.getTime() - start.getTime())
+ "毫秒");
return results;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//打印结果
public void printResult(TopDocs results) {
ScoreDoc[] h = results.scoreDocs;
if (h.length == 0) {
System.out.println("对不起,没有找到您要的结果。");
} else {
for (int i = 0; i < h.length; i++) {
try {
Document doc = searcher.doc(h[i].doc);
System.out.print("这是第" + i + "个检索到的结果,文件名为:");
System.out.println(doc.get("path"));
} catch (Exception e) {
e.printStackTrace();
}
}
}
System.out.println("--------------------------");
}
public static void main(String[] args) throws Exception {
LuceneSearch test = new LuceneSearch();
TopDocs h = null;
h = test.search("中国");
test.printResult(h);
h = test.search("人民");
test.printResult(h);
h = test.search("共和国");
test.printResult(h);
}
}
转载自:http://blog.csdn.net/perfect2011/article/details/9128323

相关文章推荐
- Lucene3.0.0 入门实例
- JAVA:lucene 入门学习,简单实例模访google搜索
- lucene4.0入门实例
- Lucene框架入门实例
- lucene 入门实例
- lucene 搜索入门实例
- Lucene.Net 入门级实例 浅显易懂。。。
- Lucene入门实例
- Lucene入门以及简单实例
- Lucene3.6入门实例
- lucene3.6入门实例
- lucene入门实例
- Lucene入门实例
- Lucene入门项目实例---比较Lucene方式搜索与传统String方式搜索的效率
- lucene3.6入门实例
- Lucene入门实例
- Lucene入门实例。
- lucene入门 ==》 实例
- Lucene入门实例
- lucene&IKAnalyzer入门实例