利用QJM实现HDFS自动主从切换(HA Automatic Failover)源码详析
2014-07-25 10:27
701 查看
最近研究了下NameNode HA Automatic Failover方面的东西,当Active NN因为异常或其他原因不能正常提供服务时,处于Standby状态的NN就可以自动切换为Active状态,从而到达真正的高可用
NN HA Automatic Failover架构图
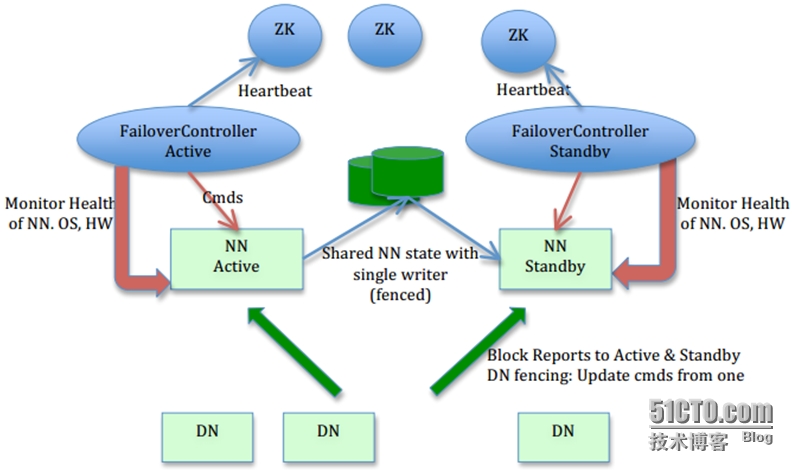
为了实现自动切换,需要依赖ZooKeeper和ZKFC组件,ZooKeeper主要用来记录NN的相关状态信息,zkfc组件以单独的JVM进程的形式运行在NN所在的节点上。下面首先分析下NN的启动流程,NN对象在实例化过程中,如果在hdfs-site.xml中配置的dfs.ha.namenodes.${dfs.nameservices}个数多于1个,则属性haEnabled为true,state的初始状态即为STANDBY
NN HA Automatic Failover架构图
为了实现自动切换,需要依赖ZooKeeper和ZKFC组件,ZooKeeper主要用来记录NN的相关状态信息,zkfc组件以单独的JVM进程的形式运行在NN所在的节点上。下面首先分析下NN的启动流程,NN对象在实例化过程中,如果在hdfs-site.xml中配置的dfs.ha.namenodes.${dfs.nameservices}个数多于1个,则属性haEnabled为true,state的初始状态即为STANDBY
HAUtil.isHAEnabled(Configuration conf, String nsId) {
//根据${dfs.nameservices}获取dfs.ha.namenodes.${dfs.nameservices}
Map<String, Map<String, InetSocketAddress>> addresses =
DFSUtil.getHaNnRpcAddresses(conf);
if (addresses == null) return false;
Map<String, InetSocketAddress> nnMap = addresses.get(nsId);
//如果ndId对应的ha.namenodes个数大于1并且nnMap不为空,返回true
return nnMap != null && nnMap.size() > 1;
}
//NN启动过程中首先判断haEnabled属性值,为true则初始状态为STANDBY
NameNode.createHAState() {
return !haEnabled ? ACTIVE_STATE : STANDBY_STATE;
} 假设集群中有两个NN,这两个NN在初始启动时,都为STANDBY状态,如果不配置Automatic Failover,则需要手动将其中的一个NN切换为ACTIVE模式,命令如下hdfs haadmin-transitionToActive nn1如果配置并启动zkfc组件,则会自动将本节点的一个NameNode切换为ACTIVE状态,这个取决于先在哪台NN上启动ZKFC,ZKFC和NN的启动顺序并没有强制的要求。下面来主要分析下,当配置的两个NN节点都启动之后,ZKFC组件的启动主要做了哪些事。ZKFC的启动类是DFSZKFailoverController,继承自ZKFailoverController,首先从main方法入手
DFSZKFailoverController.main(String args[]){
if (DFSUtil.parseHelpArgument(args,
ZKFailoverController.USAGE, System.out, true)) {
System.exit(0);
}
//加载hdfs的配置信息
GenericOptionsParser parser = new GenericOptionsParser(
new HdfsConfiguration(), args);
//根据配置信息构造DFSZKFailoverController
//根据nsId,nnId实例化NNHAServiceTarget对象,并设置到zkfc对象中
//HAServiceTarget对象用来建立到指定NN的各种网络参数
DFSZKFailoverController zkfc = DFSZKFailoverController.create(
parser.getConfiguration());
//建立与zk的连接并格式化zk的目录
//实例化ActiveStandbyElector和HealthMonitor
//启动RPCServer
System.exit(zkfc.run(parser.getRemainingArgs()));
} 在ZKFC启动的过程中,启动了两个非常重要的进程内组件:HealthMonitor和ActiveStandbyElector。ZKFC主要从HealthMonitor和ActiveStandbyElector中订阅事件并管理NN的状态并负责fencing。HealthMonitor定期检查NN的健康状况,如果出现问题,以捕获异常的方式通过回调方法将变化通知给ZKFailoverController。ActiveStandbyElector主要用于管理NN在zk上的状态,包括创建节点,节点监控等。HealthMonitor在初始启动时,如果本地节点处于健康状态,则会触发一系列的事件使当前NN节点参加选举并切换为ACTIVE状态,具体代码如下HealthMonitor.doHealthChecks() {
while (shouldRun) {
HAServiceStatus status = null;
boolean healthy = false;
try {
//通过proxy获取NN的状态
status = proxy.getServiceStatus();
proxy.monitorHealth();
healthy = true;
} catch (HealthCheckFailedException e) {
LOG.warn("Service health check failed for " + targetToMonitor
+ ": " + e.getMessage());
//调用callbacks集合中的回调方法,以事件的形式通知ZKFC
enterState(State.SERVICE_UNHEALTHY);
} catch (Throwable t) {
RPC.stopProxy(proxy);
proxy = null;
enterState(State.SERVICE_NOT_RESPONDING);
Thread.sleep(sleepAfterDisconnectMillis);
return;
}
if (status != null) {
setLastServiceStatus(status);
}
if (healthy) {
//初始启动时State=INITIALIZING,当前状态与初始状态不一致时,触发状态转移
enterState(State.SERVICE_HEALTHY);
}
Thread.sleep(checkIntervalMillis);
}
}
HealthMonitor.enterState(State newState) {
//本次状态和上一次状态不一致的时候,触发回调
if (newState != state) {
LOG.info("Entering state " + newState);
state = newState;
synchronized (callbacks) {
for (Callback cb : callbacks) {
cb.enteredState(newState);
}
}
}
}
HealthCallbacks.enteredState(HealthMonitor.State newState) {
setLastHealthState(newState);
//根据当前状态判断是否可以参加选举
recheckElectability();
}
HealthMonitor.recheckElectability() {
synchronized (elector) {
synchronized (this) {
boolean healthy = lastHealthState == State.SERVICE_HEALTHY;
long remainingDelay = delayJoiningUntilNanotime - System.nanoTime();
if (remainingDelay > 0) {
if (healthy) {
LOG.info("Would have joined master election, but this node is " +
"prohibited from doing so for " +
TimeUnit.NANOSECONDS.toMillis(remainingDelay) + " more ms");
}
scheduleRecheck(remainingDelay);
return;
}
switch (lastHealthState) {
//状态为SERVICE_HEALTHY,可参加选举
case SERVICE_HEALTHY:
elector.joinElection(targetToData(localTarget));
break;
//状态为INITIALIZING,失去选举资格
case INITIALIZING:
elector.quitElection(false);
break;
//状态为SERVICE_UNHEALTHY或者SERVICE_NOT_RESPONDING,失去选举资格
case SERVICE_UNHEALTHY:
case SERVICE_NOT_RESPONDING:
elector.quitElection(true);
break;
case HEALTH_MONITOR_FAILED:
fatalError("Health monitor failed!");
break;
default:
throw new IllegalArgumentException("Unhandled state:" + lastHealthState);
}
}
}
}
ActiveStandbyElector.joinElectionInternal() {
Preconditions.checkState(appData != null,
"trying to join election without any app data");
if (zkClient == null) {
if (!reEstablishSession()) {
fatalError("Failed to reEstablish connection with ZooKeeper");
return;
}
}
createRetryCount = 0;
wantToBeInElection = true;
//向zk写入ephemeral类型的znode,当NN挂掉后,会被自动删除
createLockNodeAsync();
}
ActiveStandbyElector.createLockNodeAsync() {
//异步调用,当方法返回时,触发回调方法
//processResult(int rc, String path, Object ctx,String name)
zkClient.create(zkLockFilePath, appData, zkAcl, CreateMode.EPHEMERAL,
this, zkClient);
}
ActiveStandbyElector.processResult(int rc, String path, Object ctx,
String name) {
Code code = Code.get(rc);
if (isSuccess(code)) {
//创建成功,试图使节点变为ACTIVE状态
//becomeActive()通过与本地NN进行RPC通信,将NN的state设置为ACTIVE
//从而使得当前节点的NN更新为主节点
if (becomeActive()) {
//监控节点
monitorActiveStatus();
} else {
reJoinElectionAfterFailureToBecomeActive();
}
return;
}
//节点已经存在,说明已经有NN成为了主节点,此时本节点只能作为热备节点存在
//故状态设置为STANDBY
if (isNodeExists(code)) {
if (createRetryCount == 0) {
becomeStandby();
}
//监控ACTIVE NN写入的znode,当节点状态改变时,通过watch机制触发回调事件
monitorActiveStatus();
return;
}
ActiveStandbyElector.becomeActive() {
if (state == State.ACTIVE) {
// already active
return true;
}
try {
//获取上一个ACTIVE NN的面包屑节点数据,并对上一个ACTIVE NN执行fence操作
Stat oldBreadcrumbStat = fenceOldActive();
//更新面包屑节点的数据
writeBreadCrumbNode(oldBreadcrumbStat);
//rpc方式与当前NN交互,使得当前节点的NN变为ACTIVE状态
appClient.becomeActive();
state = State.ACTIVE;
return true;
} catch (Exception e) {
return false;
}
} 处于STANDBY状态的NN会监控ACTIVE NN写入zk的znode节点,当节点状态改变时,触发zk的watch回调,使得STANDBY NN重新参与到选举中,从而完成状态的自动切换,代码如下ActiveStandbyElector.processWatchEvent(ZooKeeper zk, WatchedEvent event) {
String path = event.getPath();
if (path != null) {
switch (eventType) {
case NodeDeleted:
if (state == State.ACTIVE) {
enterNeutralMode();
}
//重新参加选举
joinElectionInternal();
break;
case NodeDataChanged:
monitorActiveStatus();
break;
default:
monitorActiveStatus();
}
} 上述主要是从代码的角度去理解和分析了NN自动切换的大致流程,相比手动切换的方式,可用性大大提升,同时减轻了运维的负担。

相关文章推荐
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- NameNode HA自动Failover设计文档(HDFS-3042/HDFS-2185:Automatic failover support for NN HA)
- Hadoop 2.x之HDFS利用QJM实现HA高可用
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享
- 云计算(七)-HDFS利用QJM实现HA(HDFS High Availability Using the Quorum Journal Manager)
- 利用QJM实现HDFS的HA策略部署与验证工作记录分享 推荐
- HDFS利用QJM实现HA(HDFS High Availability Using the Quorum Journal Manager)
- 关于hadoop-2.6.0 HA模式下HDFS自动failover切换的一点经验
- 利用面向对象的思想实现主从线程下多次循环的切换(因为他们要同步,所以他们是有关联的,所以把它们放在一个类里)
- 通过Keepalived实现Redis Failover自动故障切换功能[实践分享] =转载
- HDFS-HA的配置-----自动Failover
- 通过Keepalived实现Redis Failover自动故障切换功能
- redis主从配置及通过keepalived实现redis自动切换,redis主从实现10秒检查与恢复
- 利用AT91 SARM8260 USART mulit_Drop mode 实现数据地址自动切换
- HDFS-HA:Hadoop-Cloudera-cdh4版本的HDFS自动Failover(zk-based-failover)分析
- HDFS-HA的配置-----自动Failover(ZKFC)
- 利用RSVIEW32的事件机制实现软冗余自动切换
- 利用心跳heartbeat实现三台主机自动切换网络参数
- 通过Keepalived实现Redis Failover自动故障切换功能
- 通过Keepalived实现Redis Failover自动故障切换功能[实践分享]