机器学习:1、朴素贝叶斯
2014-07-11 15:12
204 查看
朴素贝叶斯分类器是一种应用基于独立假设的贝叶斯定理的简单概率分类器.更精确的描述这种潜在的概率模型为独立特征模型。
简介
贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。举个例子,如果一种水果其具有红,圆,直径大概4英寸等特征,该水果可以被判定为是苹果
尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取得非常好的分类效果。
朴素贝叶斯概率模型
理论上,概率模型分类器是一个条件概率模型。
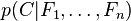
独立的类别变量

有若干类别,条件依赖于若干特征变量
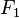
,

,...,
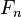
。但问题在于如果特征数量

较大或者每个特征能取大量值时,基于概率模型列出概率表变得不现实。所以我们修改这个模型使之变得可行。 贝叶斯定理有以下式子:
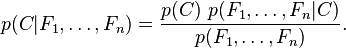
用朴素的语言可以表达为:

实际中,我们只关心分式中的分子部分,因为分母不依赖于
而且特征
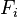
的值是给定的,于是分母可以认为是一个常数。这样分子就等价于联合分布模型。
重复使用链式法则,可将该式写成条件概率的形式,如下所示:
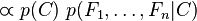
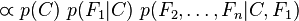
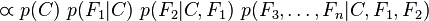


现在“朴素”的条件独立假设开始发挥作用:假设每个特征
对于其他特征
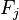
,
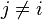
是条件独立的。这就意味着
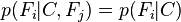
对于
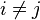
,所以联合分布模型可以表达为
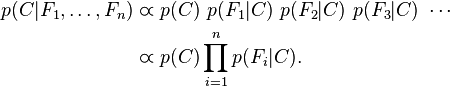
这意味着上述假设下,类变量
的条件分布可以表达为:
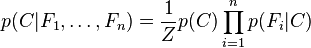
其中
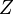
(证据因子)是一个只依赖与
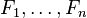
等的缩放因子,当特征变量的值已知时是一个常数。
由于分解成所谓的类先验概率
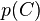
和独立概率分布
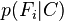
,上述概率模型的可掌控性得到很大的提高
贝叶斯分类器特点
1、 需要知道先验概率
先验概率是计算后验概率的基础。在传统的概率理论中,先验概率可以由大量的重复实验所获得的各类样本出现的频率来近似获得,其基础是“大数定律”。
2、按照获得的信息对先验概率进行修正
在没有获得任何信息的时候,如果要进行分类判别,只能依据各类存在的先验概率,将样本划分到先验概率大的一类中。而在获得了更多关于样本特征的信息后,可以依照贝叶斯公式对先验概率进行修正,得到后验概率,提高分类决策的准确性和置信度。
3、分类决策存在错误率
由于贝叶斯分类是在样本取得某特征值时对它属于各类的概率进行推测,并无法获得样本真实的类别归属情况,所以分类决策一定存在错误率,即使错误率很低,分类错误的情况也可能发生。
参数估计
只要知道先验概率
和独立概率分布
,就可以设计出一个贝叶斯分类器。先验概率
不是一个分布函数,仅仅是一个值,它表达了样本空间中各个类的样本所占数量的比例。依据大数定理,当训练集中样本数量足够多且来自于样本空间的随机选取时,可以以训练集中各类样本所占的比例来估计
的值。独立概率分布
是以某种形式分布的概率密度函数,需要从训练集中样本特征的分布情况进行估计。估计方法可以分为参数估计和非参数估计。
参数估计:先假定类条件概率密度具有某种确定的分布形式,如正态分布、二项分布,再用已经具有类别标签的训练集对概率分布的参数进行估计。
非参数估计:是在不知道或者不假设类条件概率密度的分布形式的基础上,直接用样本集中所包含的信息来估计样本的概率分布情况。
所有的模型参数都可以通过训练集的相关频率来估计。常用方法是概率的最大似然估计。类的先验概率可以通过假设各类等概率来计算(先验概率
= 1 / (类的数量)),或者通过训练集的各类样本出现的次数来估计(A类先验概率=(A类样本的数量)/(样本总数))。为了估计特征的分布参数,我们要先假设训练集数据满足某种分布或者非参数模型。
连续性数据
如果要处理的是连续数据一种通常的假设是这些连续数值为高斯分布。
例如,假设训练集中有一个连续属性,

。我们首先对数据根据类别分类,然后计算每个类别中
的均值和方差。令
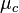
表示为
在c类上的均值,令

为
在c类上的方差。在给定类中某个值的概率,
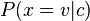
,可以通过将

表示为均值为
方差为
正态分布计算出来。如下,
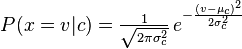
处理连续数值问题的另一种常用的技术是通过离散化连续数值的方法。通常,当训练样本数量较少或者是精确的分布已知时,通过概率分布的方法是一种更好的选择。在大量样本的情形下离散化的方法表现更优,因为大量的样本可以学习到数据的分布。由于朴素贝叶斯是一种典型的用到大量样本的方法(越大计算量的模型可以产生越高的分类精确度),所以朴素贝叶斯方法都用到离散化方法,而不是概率分布估计的方法。
样本修正与Laplace校准
如果一个给定的类和特征值在训练集中没有一起出现过,那么基于频率的估计下该概率将为0,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对每个类别所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的问题。
下面介绍一下贝叶斯理论在分类中的应用
问题:
对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了。例如,当你看到一个陌生人,你的脑子下意识判断TA是男是女;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、那边有个非主流”之类的话,其实这就是一种分类操作。
从数学角度来说,分类问题可做如下定义:
已知集合:
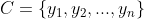
和
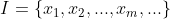
,确定映射规则
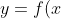)
,使得任意
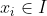
有且仅有一个
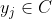
使得
)
成立。(不考虑模糊数学里的模糊集情况)
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合,其中每一个元素是一个待分类项,f 叫做分类器。分类算法的任务就是构造分类器f。
这里要着重强调,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
朴素贝叶斯分类的原理与流程
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设
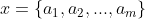
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合
。
3、计算
,P(y_2|x),...,P(y_n|x))
。
4、如果
=max\{P(y_1|x),P(y_2|x),...,P(y_n|x)\})
,则
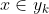
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
,P(a_2|y_1),...,P(a_m|y_1);P(a_1|y_2),P(a_2|y_2),...,P(a_m|y_2);...;P(a_1|y_n),P(a_2|y_n),...,P(a_m|y_n))
。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
=\frac{P(x|y_i)P(y_i)}{P(x)})
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
P(y_i)=P(a_1|y_i)P(a_2|y_i)...P(a_m|y_i)P(y_i)=P(y_i)\prod^m_{j=1}P(a_j|y_i))
根据上述分析,朴素贝叶斯分类的流程可以由下图表示

可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
朴素贝叶斯分类实例:检测SNS社区中不真实账号
下面讨论一个使用朴素贝叶斯分类解决实际问题的例子,为了简单起见,对例子中的数据做了适当的简化。
这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2},a1:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a=0(不是),a=1(是)}。
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
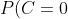=8900/100000=0.89)
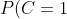=110/100000=0.11)
4、计算每个类别条件下各个特征属性划分的频率
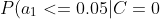=0.3)
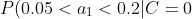=0.5)
=0.2)
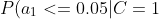=0.8)
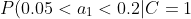=0.1)
=0.1)
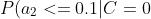=0.1)
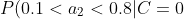=0.7)
=0.2)
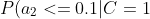=0.7)
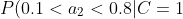=0.2)
=0.1)
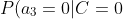=0.2)
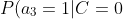=0.8)
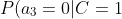=0.9)
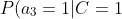=0.1)
5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
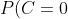P(x|C=0)=P(C=0)P(0.05%3Ca_1%3C0.2|C=0)P(0.1%3Ca_2%3C0.8|C=0)P(a_3=0|C=0)=0.89*0.5*0.7*0.2=0.0623)
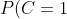P(x|C=1)=P(C=1)P(0.05%3Ca_1%3C0.2|C=1)P(0.1%3Ca_2%3C0.8|C=1)P(a_3=0|C=1)=0.11*0.1*0.2*0.9=0.00198)
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
简介
贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。举个例子,如果一种水果其具有红,圆,直径大概4英寸等特征,该水果可以被判定为是苹果
尽管这些特征相互依赖或者有些特征由其他特征决定,然而朴素贝叶斯分类器认为这些属性在判定该水果是否为苹果的概率分布上独立的。朴素贝叶斯分类器依靠精确的自然概率模型,在有监督学习的样本集中能获取得非常好的分类效果。
朴素贝叶斯概率模型
理论上,概率模型分类器是一个条件概率模型。
独立的类别变量
有若干类别,条件依赖于若干特征变量
,
,...,
。但问题在于如果特征数量
较大或者每个特征能取大量值时,基于概率模型列出概率表变得不现实。所以我们修改这个模型使之变得可行。 贝叶斯定理有以下式子:
用朴素的语言可以表达为:
实际中,我们只关心分式中的分子部分,因为分母不依赖于
而且特征
的值是给定的,于是分母可以认为是一个常数。这样分子就等价于联合分布模型。
重复使用链式法则,可将该式写成条件概率的形式,如下所示:
现在“朴素”的条件独立假设开始发挥作用:假设每个特征
对于其他特征
,
是条件独立的。这就意味着
对于
,所以联合分布模型可以表达为
这意味着上述假设下,类变量
的条件分布可以表达为:
其中
(证据因子)是一个只依赖与
等的缩放因子,当特征变量的值已知时是一个常数。
由于分解成所谓的类先验概率
和独立概率分布
,上述概率模型的可掌控性得到很大的提高
贝叶斯分类器特点
1、 需要知道先验概率
先验概率是计算后验概率的基础。在传统的概率理论中,先验概率可以由大量的重复实验所获得的各类样本出现的频率来近似获得,其基础是“大数定律”。
2、按照获得的信息对先验概率进行修正
在没有获得任何信息的时候,如果要进行分类判别,只能依据各类存在的先验概率,将样本划分到先验概率大的一类中。而在获得了更多关于样本特征的信息后,可以依照贝叶斯公式对先验概率进行修正,得到后验概率,提高分类决策的准确性和置信度。
3、分类决策存在错误率
由于贝叶斯分类是在样本取得某特征值时对它属于各类的概率进行推测,并无法获得样本真实的类别归属情况,所以分类决策一定存在错误率,即使错误率很低,分类错误的情况也可能发生。
参数估计
只要知道先验概率
和独立概率分布
,就可以设计出一个贝叶斯分类器。先验概率
不是一个分布函数,仅仅是一个值,它表达了样本空间中各个类的样本所占数量的比例。依据大数定理,当训练集中样本数量足够多且来自于样本空间的随机选取时,可以以训练集中各类样本所占的比例来估计
的值。独立概率分布
是以某种形式分布的概率密度函数,需要从训练集中样本特征的分布情况进行估计。估计方法可以分为参数估计和非参数估计。
参数估计:先假定类条件概率密度具有某种确定的分布形式,如正态分布、二项分布,再用已经具有类别标签的训练集对概率分布的参数进行估计。
非参数估计:是在不知道或者不假设类条件概率密度的分布形式的基础上,直接用样本集中所包含的信息来估计样本的概率分布情况。
所有的模型参数都可以通过训练集的相关频率来估计。常用方法是概率的最大似然估计。类的先验概率可以通过假设各类等概率来计算(先验概率
= 1 / (类的数量)),或者通过训练集的各类样本出现的次数来估计(A类先验概率=(A类样本的数量)/(样本总数))。为了估计特征的分布参数,我们要先假设训练集数据满足某种分布或者非参数模型。
连续性数据
如果要处理的是连续数据一种通常的假设是这些连续数值为高斯分布。
例如,假设训练集中有一个连续属性,
。我们首先对数据根据类别分类,然后计算每个类别中
的均值和方差。令
表示为
在c类上的均值,令
为
在c类上的方差。在给定类中某个值的概率,
,可以通过将
表示为均值为
方差为
正态分布计算出来。如下,
处理连续数值问题的另一种常用的技术是通过离散化连续数值的方法。通常,当训练样本数量较少或者是精确的分布已知时,通过概率分布的方法是一种更好的选择。在大量样本的情形下离散化的方法表现更优,因为大量的样本可以学习到数据的分布。由于朴素贝叶斯是一种典型的用到大量样本的方法(越大计算量的模型可以产生越高的分类精确度),所以朴素贝叶斯方法都用到离散化方法,而不是概率分布估计的方法。
样本修正与Laplace校准
如果一个给定的类和特征值在训练集中没有一起出现过,那么基于频率的估计下该概率将为0,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对每个类别所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的问题。
下面介绍一下贝叶斯理论在分类中的应用
问题:
对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了。例如,当你看到一个陌生人,你的脑子下意识判断TA是男是女;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、那边有个非主流”之类的话,其实这就是一种分类操作。
从数学角度来说,分类问题可做如下定义:
已知集合:
和
,确定映射规则
,使得任意
有且仅有一个
使得
成立。(不考虑模糊数学里的模糊集情况)
其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合,其中每一个元素是一个待分类项,f 叫做分类器。分类算法的任务就是构造分类器f。
这里要着重强调,分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题缺少足够的信息来构造100%正确的映射规则,而是通过对经验数据的学习从而实现一定概率意义上正确的分类,因此所训练出的分类器并不是一定能将每个待分类项准确映射到其分类,分类器的质量与分类器构造方法、待分类数据的特性以及训练样本数量等诸多因素有关。
例如,医生对病人进行诊断就是一个典型的分类过程,任何一个医生都无法直接看到病人的病情,只能观察病人表现出的症状和各种化验检测数据来推断病情,这时医生就好比一个分类器,而这个医生诊断的准确率,与他当初受到的教育方式(构造方法)、病人的症状是否突出(待分类数据的特性)以及医生的经验多少(训练样本数量)都有密切关系。
朴素贝叶斯分类的原理与流程
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合
。
3、计算
。
4、如果
,则
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
根据上述分析,朴素贝叶斯分类的流程可以由下图表示
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
朴素贝叶斯分类实例:检测SNS社区中不真实账号
下面讨论一个使用朴素贝叶斯分类解决实际问题的例子,为了简单起见,对例子中的数据做了适当的简化。
这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
如果通过纯人工检测,需要耗费大量的人力,效率也十分低下,如能引入自动检测机制,必将大大提升工作效率。这个问题说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先设C=0表示真实账号,C=1表示不真实账号。
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:a1:日志数量/注册天数,a2:好友数量/注册天数,a3:是否使用真实头像。在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。
下面给出划分:a1:{a<=0.05, 0.05<a<0.2, a>=0.2},a1:{a<=0.1, 0.1<a<0.8, a>=0.8},a3:{a=0(不是),a=1(是)}。
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、计算训练样本中每个类别的频率
用训练样本中真实账号和不真实账号数量分别除以一万,得到:
4、计算每个类别条件下各个特征属性划分的频率
5、使用分类器进行鉴别
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。

相关文章推荐
- 机器学习之旅---朴素贝叶斯分类器
- 读书笔记:机器学习实战(3)——章4的朴素贝叶斯分类代码和个人理解与注释
- 机器学习实战 朴素贝叶斯原理及代码
- 机器学习实战第四章朴素贝叶斯(1)
- 机器学习练习之朴素贝叶斯
- 机器学习实战-4朴素贝叶斯-python3
- 机器学习实战笔记(3.1)-朴素贝叶斯算法(原理分析)
- 机器学习实战python版第四章基于概率论的分类方法 朴素贝叶斯
- 机器学习之朴素贝叶斯模型及代码示例
- 机器学习:一些常见的监督型学习方法(K近邻、决策树、朴素贝叶斯、逻辑回归)
- 机器学习实战第4章-朴素贝叶斯(bayes)
- 机器学习实战_初识朴素贝叶斯算法_理解其python代码(二)
- 机器学习实战——朴素贝叶斯
- 机器学习实战学习笔记8——朴素贝叶斯
- 机器学习笔记:朴素贝叶斯方法(Naive Bayes)原理和实现
- 机器学习实战之朴素贝叶斯naive bayes
- 机器学习实战笔记4(朴素贝叶斯)
- 机器学习实战——python实现简单的朴素贝叶斯分类器
- 机器学习实战--基于概率论的分类方法:朴素贝叶斯
- 机器学习实战笔记4(朴素贝叶斯)