算法导论 | 第23章 最小生成树
2014-07-11 00:30
267 查看
最小生成树(Minimum Spanning Tree),全称“最小权值生成树”。在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树。
有两种具体的实现算法
①.Kruskal算法
②.Prim算法
两者都用到了贪心算法。
1:最小生成树的形成
在每次循环之前,我们要保证集合A是某棵最小生成树的一个子集。
在每一步,我们要做的是选择一条边(u,v),将其加入到集合A中,使得A不违反循环不变式。我们称这样的边为安全边。
2:克鲁斯卡尔(Kruskal)算法
(1)算法介绍
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
(2)图示
以上图G4为例,来对克鲁斯卡尔进行演示(假设,用数组R保存最小生成树结果)。

第1步:将边<E,F>加入R中。
边<E,F>的权值最小,因此将它加入到最小生成树结果R中。
第2步:将边<C,D>加入R中。
上一步操作之后,边<C,D>的权值最小,因此将它加入到最小生成树结果R中。
第3步:将边<D,E>加入R中。
上一步操作之后,边<D,E>的权值最小,因此将它加入到最小生成树结果R中。
第4步:将边<B,F>加入R中。
上一步操作之后,边<C,E>的权值最小,但<C,E>会和已有的边构成回路;因此,跳过边<C,E>。同理,跳过边<C,F>。将边<B,F>加入到最小生成树结果R中。
第5步:将边<E,G>加入R中。
上一步操作之后,边<E,G>的权值最小,因此将它加入到最小生成树结果R中。
第6步:将边<A,B>加入R中。
上一步操作之后,边<F,G>的权值最小,但<F,G>会和已有的边构成回路;因此,跳过边<F,G>。同理,跳过边<B,C>。将边<A,B>加入到最小生成树结果R中。
此时,最小生成树构造完成!它包括的边依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
(3)算法解析
根据前面介绍的克鲁斯卡尔算法的基本思想和做法,我们能够了解到,克鲁斯卡尔算法重点需要解决的以下两个问题:
问题一 对图的所有边按照权值大小进行排序。
问题二 将边添加到最小生成树中时,怎么样判断是否形成了回路。
问题一很好解决,采用排序算法进行排序即可。
问题二,处理方式是:记录顶点在"最小生成树"中的终点,顶点的终点是"在最小生成树中与它连通的最大顶点"(关于这一点,后面会通过图片给出说明)。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。 以下图来进行说明:

在将<E,F> <C,D> <D,E>加入到最小生成树R中之后,这几条边的顶点就都有了终点:
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。
关于终点,就是将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点"。 因此,接下来,虽然<C,E>是权值最小的边。但是C和E的重点都是F,即它们的终点相同,因此,将<C,E>加入最小生成树的话,会形成回路。这就是判断回路的方式。
(4)基本定义
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
(5)算法实现
/article/4708233.html
3:普里姆(Prim)算法
(1)算法介绍
普里姆(Prim)算法,和克鲁斯卡尔算法一样,是用来求加权连通图的最小生成树的算法。
基本思想
对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。 从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
(2)图示
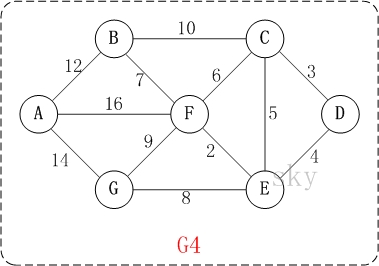
以上图G4为例,来对普里姆进行演示(从第一个顶点A开始通过普里姆算法生成最小生成树)。

初始状态:V是所有顶点的集合,即V={A,B,C,D,E,F,G};U和T都是空!
第1步:将顶点A加入到U中。
此时,U={A}。
第2步:将顶点B加入到U中。
上一步操作之后,U={A}, V-U={B,C,D,E,F,G};因此,边(A,B)的权值最小。将顶点B添加到U中;此时,U={A,B}。
第3步:将顶点F加入到U中。
上一步操作之后,U={A,B}, V-U={C,D,E,F,G};因此,边(B,F)的权值最小。将顶点F添加到U中;此时,U={A,B,F}。
第4步:将顶点E加入到U中。
上一步操作之后,U={A,B,F}, V-U={C,D,E,G};因此,边(F,E)的权值最小。将顶点E添加到U中;此时,U={A,B,F,E}。
第5步:将顶点D加入到U中。
上一步操作之后,U={A,B,F,E}, V-U={C,D,G};因此,边(E,D)的权值最小。将顶点D添加到U中;此时,U={A,B,F,E,D}。
第6步:将顶点C加入到U中。
上一步操作之后,U={A,B,F,E,D}, V-U={C,G};因此,边(D,C)的权值最小。将顶点C添加到U中;此时,U={A,B,F,E,D,C}。
第7步:将顶点G加入到U中。
上一步操作之后,U={A,B,F,E,D,C}, V-U={G};因此,边(F,G)的权值最小。将顶点G添加到U中;此时,U=V。
此时,最小生成树构造完成!它包括的顶点依次是:A B F E D C G。
(3)基本定义
Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
(4)算法实现
/article/4708236.html
4:时间复杂度分析
对于克鲁斯卡尔(Kruskal)算法:时间复杂度为O(ElgV)
对于普里姆(Prim)算法:
其取决于最小优先队列Q的实现方式,时间复杂度与克鲁斯卡尔(Kruskal)算法相同,O(ElgV)。
如果使用斐波那契堆来实现最小优先队列,时间复杂度为O(E+VlgV)。
有两种具体的实现算法
①.Kruskal算法
②.Prim算法
两者都用到了贪心算法。
1:最小生成树的形成
在每次循环之前,我们要保证集合A是某棵最小生成树的一个子集。
在每一步,我们要做的是选择一条边(u,v),将其加入到集合A中,使得A不违反循环不变式。我们称这样的边为安全边。
GENERIC_MST(G, w)
A <- 空集
while A does not form a spanning tree
do find an edge(u, v) that is safe for A
A <- A 并 {(u, v)}
return A2:克鲁斯卡尔(Kruskal)算法
(1)算法介绍
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
(2)图示
以上图G4为例,来对克鲁斯卡尔进行演示(假设,用数组R保存最小生成树结果)。
第1步:将边<E,F>加入R中。
边<E,F>的权值最小,因此将它加入到最小生成树结果R中。
第2步:将边<C,D>加入R中。
上一步操作之后,边<C,D>的权值最小,因此将它加入到最小生成树结果R中。
第3步:将边<D,E>加入R中。
上一步操作之后,边<D,E>的权值最小,因此将它加入到最小生成树结果R中。
第4步:将边<B,F>加入R中。
上一步操作之后,边<C,E>的权值最小,但<C,E>会和已有的边构成回路;因此,跳过边<C,E>。同理,跳过边<C,F>。将边<B,F>加入到最小生成树结果R中。
第5步:将边<E,G>加入R中。
上一步操作之后,边<E,G>的权值最小,因此将它加入到最小生成树结果R中。
第6步:将边<A,B>加入R中。
上一步操作之后,边<F,G>的权值最小,但<F,G>会和已有的边构成回路;因此,跳过边<F,G>。同理,跳过边<B,C>。将边<A,B>加入到最小生成树结果R中。
此时,最小生成树构造完成!它包括的边依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
(3)算法解析
根据前面介绍的克鲁斯卡尔算法的基本思想和做法,我们能够了解到,克鲁斯卡尔算法重点需要解决的以下两个问题:
问题一 对图的所有边按照权值大小进行排序。
问题二 将边添加到最小生成树中时,怎么样判断是否形成了回路。
问题一很好解决,采用排序算法进行排序即可。
问题二,处理方式是:记录顶点在"最小生成树"中的终点,顶点的终点是"在最小生成树中与它连通的最大顶点"(关于这一点,后面会通过图片给出说明)。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。 以下图来进行说明:
在将<E,F> <C,D> <D,E>加入到最小生成树R中之后,这几条边的顶点就都有了终点:
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。
关于终点,就是将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是"与它连通的最大顶点"。 因此,接下来,虽然<C,E>是权值最小的边。但是C和E的重点都是F,即它们的终点相同,因此,将<C,E>加入最小生成树的话,会形成回路。这就是判断回路的方式。
(4)基本定义
// 邻接矩阵
typedef struct _graph
{
char vexs[MAX]; // 顶点集合
int vexnum; // 顶点数
int edgnum; // 边数
int matrix[MAX][MAX]; // 邻接矩阵
}Graph, *PGraph;
// 边的结构体
typedef struct _EdgeData
{
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
}EData;Graph是邻接矩阵对应的结构体。vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
(5)算法实现
/article/4708233.html
3:普里姆(Prim)算法
(1)算法介绍
普里姆(Prim)算法,和克鲁斯卡尔算法一样,是用来求加权连通图的最小生成树的算法。
基本思想
对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。 从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
(2)图示
以上图G4为例,来对普里姆进行演示(从第一个顶点A开始通过普里姆算法生成最小生成树)。
初始状态:V是所有顶点的集合,即V={A,B,C,D,E,F,G};U和T都是空!
第1步:将顶点A加入到U中。
此时,U={A}。
第2步:将顶点B加入到U中。
上一步操作之后,U={A}, V-U={B,C,D,E,F,G};因此,边(A,B)的权值最小。将顶点B添加到U中;此时,U={A,B}。
第3步:将顶点F加入到U中。
上一步操作之后,U={A,B}, V-U={C,D,E,F,G};因此,边(B,F)的权值最小。将顶点F添加到U中;此时,U={A,B,F}。
第4步:将顶点E加入到U中。
上一步操作之后,U={A,B,F}, V-U={C,D,E,G};因此,边(F,E)的权值最小。将顶点E添加到U中;此时,U={A,B,F,E}。
第5步:将顶点D加入到U中。
上一步操作之后,U={A,B,F,E}, V-U={C,D,G};因此,边(E,D)的权值最小。将顶点D添加到U中;此时,U={A,B,F,E,D}。
第6步:将顶点C加入到U中。
上一步操作之后,U={A,B,F,E,D}, V-U={C,G};因此,边(D,C)的权值最小。将顶点C添加到U中;此时,U={A,B,F,E,D,C}。
第7步:将顶点G加入到U中。
上一步操作之后,U={A,B,F,E,D,C}, V-U={G};因此,边(F,G)的权值最小。将顶点G添加到U中;此时,U=V。
此时,最小生成树构造完成!它包括的顶点依次是:A B F E D C G。
(3)基本定义
// 邻接矩阵
typedef struct _graph
{
char vexs[MAX]; // 顶点集合
int vexnum; // 顶点数
int edgnum; // 边数
int matrix[MAX][MAX]; // 邻接矩阵
}Graph, *PGraph;
// 边的结构体
typedef struct _EdgeData
{
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
}EData;Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
(4)算法实现
/article/4708236.html
4:时间复杂度分析
对于克鲁斯卡尔(Kruskal)算法:时间复杂度为O(ElgV)
对于普里姆(Prim)算法:
其取决于最小优先队列Q的实现方式,时间复杂度与克鲁斯卡尔(Kruskal)算法相同,O(ElgV)。
如果使用斐波那契堆来实现最小优先队列,时间复杂度为O(E+VlgV)。

相关文章推荐
- 算法导论-第23章-最小生成树:Prime算法(基于vector)的C++实现
- 最小生成树(算法导论第23章)
- 【算法导论】第23章最小生成树
- 【算法导论】最小生成树之Prime法
- 【算法导论】最小生成树之Kruskal法
- 【算法导论笔记】最小生成树
- 【算法导论】最小生成树之Prime法
- POJ 1679 The Unique MST(算法导论23-1次优最小生成树)
- 【算法导论】最小生成树(prim算法)
- 算法导论--最小生成树(Kruskal和Prim算法)
- 【算法导论】最小生成树扩展
- 算法导论之图的最小生成树
- 【算法导论】最小生成树之Kruskal法
- 最小生成树----算法导论
- 【算法导论】最小生成树(prim算法)
- 无向图基本算法 -- 遍历及最小生成树算法
- acm pku 1287 Networking的Prim最小生成树算法实现
- 用克鲁斯尔算法求最小生成树
- hdu1301 Jungle Roads(Prime算法求最小生成树)
- hdu 1162Eddy's picture Prime算法求最小生成树