Deduplication去重算法基础之可变长度数据分片
2014-07-04 22:20
656 查看
Deduplication(去重,消重)是近年来存储业界非常热门的一个技术,无论是Primary Storage,还是备份系统,抑或是云存储比如百度迅雷的网盘,都需要考虑dedup来减少冗余,降低成本。当然了各种系统对dedup的需求是不一样的。Primary Storage对性能要求高,特别是IOPS指标,这样很难实现在线的dedup,往往只会采用离线的dedup在闲时进行去重。备份系统则是各有千秋,去重备份系统的领头羊DataDomain是采用榨干CPU能力的在线dedup,由于有一些独特的技术,能做到吞吐量每小时数T。而网盘服务中,多用户可能存在重复文件,但各用户的带宽有限,往往是采用文件级去重,客户端在上传文件之前就进行文件hash计算,只传输云端没有的新文件。
Dedup从技术上说,分文件级去重和块级去重。文件级的去重,最原始是对整个文件做一个hash取得key值,实现简单,效果一般。如上所述,在多用户环境中重复文件很多的条件下,能取得一定的去重效果。但是在实践中,往往完全相同的文件还是不多见的。例如网盘中的电影文件,往往同一个电影同一个文件,有些用户获取文件时,部分数据不全(往往出现在BT下载中种子没了的情况下)。这时候文件还是可以流畅观看的,但是如果用全文件级别的hash,一点差异就会导致完全不同的hash值。而且动辄数G的文件做全文的hash消耗太大。据我所知,有些网盘服务是在大文件的某些特定偏移取出特定大小的数据块,然后算出多个hash值。如果两个文件的多个hash值匹配,就判断两个文件是相同文件。
块级的去重,除了能消除重复的文件,还能在同一个文件有部分变化时,只保留变化部分。而实现块级的去重,数据如何分块是关键。数据分块方法分为固定长度分块和可变长分块。固定长度分块实现起来也相当的简单,但是如果文件中有小小的新增或者删除改动,会造成旧的分块失效,从增删数据位置开始,所有的分块hash值都改变。如图:

所以,变长分块才是最终解决之道。变长分块要达到的目标就是,当数据中有新增或者删除的数据时,变动的数据只影响周围1-2个数据块,只有这1-2个数据块的hash值发生改变,而后续更多的数据块还是按照原来的方式分块,hash值不变。
这样一来,可以想到的解决方法是,变长分块要根据数据内容特征来分块。如果能根据数据内容的特征来分块的话,如果发生文件内容改变,情况会如下图:
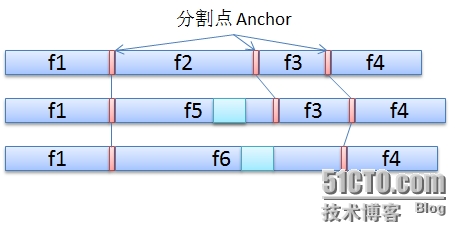
这样,除了1-2个数据块以外,其他的数据块hash值没有发生变化。但是问题来了,如何找到和定义这些分割点(Anchor)呢?
首先能想到的最粗糙的,就是按数据本身的内容值来找。比如,我们可以搜索数据流中所有连续4个字节为0的数据,把这4个字节,做为如上图中红色的分割点。这样是不是就可以了呢?
理论上,这样粗糙的分割可以完成变长切分的功能。但是这样的特征值分布效果不好,一个文件中很容易出现完全没有4个连续0的情况,也可能文件中出现大段的连续0,造成大量无效数据分割点。这种粗糙的分割点造成我们完全无法预测文件中分割点的分布情况,无法预测最终数据块的大小。数据块太大会造成修改后失效率高,数据块太小会造成读写性能低下。
所以,我们对一个好的变长数据切分算法的要求是,通过数学方法能对最终切分的效果有一定的预期。数据块的大小最好能在我们需要的大小附近正态分布,最终平均大小是我们期望的大小。下面就来介绍一个靠谱的分块算法,源自一片论文《A Low-bandwidth Network File System》
这个文章介绍的方法简单来说,就是如果期望分块大小在8K上下,那么就算数据流中每一个48字节的数据块的hash值(顺序计算0-47字节,1-48字节,2-49字节等等等等),然后把hash值对8K取模(xor 0x1fff),最后找出数据流中所有模值的数据块做为分割点。
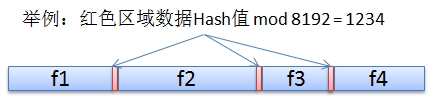
论文中做了一些实验,论证了窗口(分割点数据块大小)取24字节或者48字节影响不大,48字节结果略好。Hash算法采用rabin hash。最终数据块大小的分布,中位值是5.8K,平均值非常接近8K。可以说,这是一个相当令人满意的算法。论文中的算法为了避免出现极端情况(过多或者过少分割点造成过大或者过小数据块),设置了数据块的上下限,数据块最小2K,最大64K。
在实际产品中,这些参数都要根据实际的数据流特征来进行微调。比如某公司产品,数据块下限4K,上限12K。在计算分割点的hash算法的选择上,实际产品中为了减轻计算负担(因为CPU还有大量去重运算),很可能选择虽然分布效果不好但更轻量级的算法。
变长分块的奥秘就介绍到这,以后有时间还会介绍Dedup产品其它的关键技术点。
(写这篇文章主要原因是,现有中文文章对变长数据块的分割介绍的实在太晦涩难懂了!)
鸣谢参考过的博文:
http://qing.blog.sina.com.cn/tj/88ca09aa33000uyo.html Data Dedup技术简介 EMC研究院
http://mss.sjtu.edu.cn/bencandy.php?fid=14&id=167 上海交大 海量存储实验室 重复数据删除综述
/article/2433916.html 重复数据删除
本文出自 “计算-存储-互联网” 博客,请务必保留此出处http://besmart.blog.51cto.com/8957700/1434672
Dedup从技术上说,分文件级去重和块级去重。文件级的去重,最原始是对整个文件做一个hash取得key值,实现简单,效果一般。如上所述,在多用户环境中重复文件很多的条件下,能取得一定的去重效果。但是在实践中,往往完全相同的文件还是不多见的。例如网盘中的电影文件,往往同一个电影同一个文件,有些用户获取文件时,部分数据不全(往往出现在BT下载中种子没了的情况下)。这时候文件还是可以流畅观看的,但是如果用全文件级别的hash,一点差异就会导致完全不同的hash值。而且动辄数G的文件做全文的hash消耗太大。据我所知,有些网盘服务是在大文件的某些特定偏移取出特定大小的数据块,然后算出多个hash值。如果两个文件的多个hash值匹配,就判断两个文件是相同文件。
块级的去重,除了能消除重复的文件,还能在同一个文件有部分变化时,只保留变化部分。而实现块级的去重,数据如何分块是关键。数据分块方法分为固定长度分块和可变长分块。固定长度分块实现起来也相当的简单,但是如果文件中有小小的新增或者删除改动,会造成旧的分块失效,从增删数据位置开始,所有的分块hash值都改变。如图:
所以,变长分块才是最终解决之道。变长分块要达到的目标就是,当数据中有新增或者删除的数据时,变动的数据只影响周围1-2个数据块,只有这1-2个数据块的hash值发生改变,而后续更多的数据块还是按照原来的方式分块,hash值不变。
这样一来,可以想到的解决方法是,变长分块要根据数据内容特征来分块。如果能根据数据内容的特征来分块的话,如果发生文件内容改变,情况会如下图:
这样,除了1-2个数据块以外,其他的数据块hash值没有发生变化。但是问题来了,如何找到和定义这些分割点(Anchor)呢?
首先能想到的最粗糙的,就是按数据本身的内容值来找。比如,我们可以搜索数据流中所有连续4个字节为0的数据,把这4个字节,做为如上图中红色的分割点。这样是不是就可以了呢?
理论上,这样粗糙的分割可以完成变长切分的功能。但是这样的特征值分布效果不好,一个文件中很容易出现完全没有4个连续0的情况,也可能文件中出现大段的连续0,造成大量无效数据分割点。这种粗糙的分割点造成我们完全无法预测文件中分割点的分布情况,无法预测最终数据块的大小。数据块太大会造成修改后失效率高,数据块太小会造成读写性能低下。
所以,我们对一个好的变长数据切分算法的要求是,通过数学方法能对最终切分的效果有一定的预期。数据块的大小最好能在我们需要的大小附近正态分布,最终平均大小是我们期望的大小。下面就来介绍一个靠谱的分块算法,源自一片论文《A Low-bandwidth Network File System》
这个文章介绍的方法简单来说,就是如果期望分块大小在8K上下,那么就算数据流中每一个48字节的数据块的hash值(顺序计算0-47字节,1-48字节,2-49字节等等等等),然后把hash值对8K取模(xor 0x1fff),最后找出数据流中所有模值的数据块做为分割点。
论文中做了一些实验,论证了窗口(分割点数据块大小)取24字节或者48字节影响不大,48字节结果略好。Hash算法采用rabin hash。最终数据块大小的分布,中位值是5.8K,平均值非常接近8K。可以说,这是一个相当令人满意的算法。论文中的算法为了避免出现极端情况(过多或者过少分割点造成过大或者过小数据块),设置了数据块的上下限,数据块最小2K,最大64K。
在实际产品中,这些参数都要根据实际的数据流特征来进行微调。比如某公司产品,数据块下限4K,上限12K。在计算分割点的hash算法的选择上,实际产品中为了减轻计算负担(因为CPU还有大量去重运算),很可能选择虽然分布效果不好但更轻量级的算法。
变长分块的奥秘就介绍到这,以后有时间还会介绍Dedup产品其它的关键技术点。
(写这篇文章主要原因是,现有中文文章对变长数据块的分割介绍的实在太晦涩难懂了!)
鸣谢参考过的博文:
http://qing.blog.sina.com.cn/tj/88ca09aa33000uyo.html Data Dedup技术简介 EMC研究院
http://mss.sjtu.edu.cn/bencandy.php?fid=14&id=167 上海交大 海量存储实验室 重复数据删除综述
/article/2433916.html 重复数据删除
本文出自 “计算-存储-互联网” 博客,请务必保留此出处http://besmart.blog.51cto.com/8957700/1434672

相关文章推荐
- 使用boost的archive做可变长度的网络消息数据打包
- 可变长度数据存储结构动态删除元素
- C++各基础数据类型长度以及范围
- STM32使用DMA从串口读可变长度数据到内存
- JAVA基础 数据类型长度
- sql server 2005 T-SQL binary 和 varbinary (Transact-SQL)固定长度或可变长度的 Binary 数据类型。
- TensorFlow入门(十-II)tfrecord 可变长度的序列数据
- Java基本数据类型数组与可变长度参数
- 基础数据类型长度
- JAVA基础复习十六-LinkedList、栈和队列数据类型、泛型、增强for循环、可变参数、Arrays工具类
- Java基础加强:静态导入及可变参数和增强for循环 ,基本数据类型的自动拆箱和装箱
- 可变长度数据的管道实现方法
- .一数据报的总长度为3820字节,其数据部分为3800字节长(使用固定首部),需要分片为长度不超过1420字节的数据报片。试给出分片后每个数据报片相关字段的值(包括MF、DF、片偏移)。
- Python 基础之字符串(不可变数据类型)
- c#基础之长度可变类型相同的参数列表
- c语言基础数据类型的长度 留下来看看
- 多张表struts2导入excel数据 其中一张表是一对多 ,故excel横向cell长度可变
- 基础数据类型长度
- Java基础知识2.3.3--可变长度字符串
- 计算机基础理论知识梳理篇(一):数据类型长度、内存页、IPC