AC自动机资料汇总
2014-07-02 21:51
281 查看
概要介绍,一篇不错的文章
关键字:AC自动机 自动机 有限状态自动机 Trie 字母树 字符串匹配 多串匹配算法
Note:阅读本文需要有KMP算法基础,如果你不知道什么是KMP,请看这里:
http://www.matrix67.com/blog/article.asp?id=146 (Matrix67大牛写的)
AC自动机是用来处理多串匹配问题的,即给你很多串,再给你一篇文章,让你在文章中找这些串是否出现过,在哪出现。也许你考虑过AC自动机名字的含义,我也有过同样的想法。你现在已经知道KMP了,他之所以叫做KMP,是因为这个算法是由Knuth、Morris、Pratt三个提出来的,取了这三个人的名字的头一个字母。那么AC自动机也是同样的,他是Aho-Corasick。所以不要再YY地认为AC自动机是AC(cept)自动机,虽然他确实能帮你AC一点题目。
。。。扯远了。。。
要学会AC自动机,我们必须知道什么是Trie,即字母树。如果你会了,请跳过这一段
Trie是由字母组成的。
先看张图:

这就是一棵Trie树。用绿色标出的点表示一个单词的末尾(为什么这样表示?看下去就知道了)。树上一条从root到绿色节点的路径上的字母,组成了一个“单词”。
/* 也许你看了这一段,就知道如何构建Trie了,那请跳过以下几段。*/
那么如何来构建一棵Trie呢?就让我从一棵空树开始,一步步来构建他。
一开始,我们有一个root:

现在,插入第一个单词,she。这就相当于在树中插入一条链。过程很简单。插完以后,我们在最后一个字母’e’上加一个绿色标记,结果如图:

再来一个单词,shr(什么词?…..右位移啊)。由于root下已经有’s’了,我们就不重复插入了,同理,由于’s’下有’h’了,我们也略过他,直接在’h’下插入’r’,并把’r’标为绿色。结果如图:

按同样的方法,我们继续把余下的元素插进树中。
最后结果:

也就是这样:
好了,现在我们已经有一棵Trie了,但这还不够,我们还要在Trie上引入一个很强大的东西:失败指针或者说shift数组或者说Next函数 …..你爱怎么叫怎么叫吧,反正就是KMP的精华所在,这也是我为什么叫你看KMP的原因。
KMP中我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符,当A[i+1]<>B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配(从而使得i和j能继续增加)。
Trie树上的失败指针与此类似。
假设有一个节点k,他的失败指针指向j。那么k,j满足这个性质:设root到j的距离为n,则从k之上的第n个节点到k所组成的长度为n的单词,与从root到j所组成的单词相同。
比如图中she中的’e’的失败指针就应该指向her中的’e’。因为:

图中红框部分是完全一样的。
那么我们要怎样构建这个东西呢?其实我们可以用一个简单的BFS搞定这一切。
对于每个节点,我们可以这样处理:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字目也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root
最开始,我们把root加入队列(root的失败指针显然指向自己),这以后我们每处理一个点,就把它的所有儿子加入队列,直到搞完。
至于为什么这样就搞的定,我们讲下去就知道了。
好了,现在我们有了一棵带失败指针的Trie了,而我的文章也破千字了,接下来,我们就要讲AC自动机是怎么工作的了。
AC自动机是个多串匹配,也就是说会有很多串让你查找,我们先把这些串弄成一棵Trie,再搞一下失败指针,然后我们就可以开始AC自动机了。
一开始,Trie中有一个指针t1指向root,待匹配串(也就是“文章”)中有一个指针t2指向串头。
接下来的操作和KMP很相似:如果t2指向的字母,是Trie树中,t1指向的节点的儿子,那么t2+1,t1改为那个儿子的编号,否则t1顺这当前节点的失败指针向上找,直到t2是t1的一个儿子,或者t1指向根。如果t1路过了一个绿色的点,那么以这个点结尾的单词就算出现过了。或者如果t1所在的点可以顺着失败指针走到一个绿色点,那么以那个绿点结尾的单词就算出现过了。
我们现在回过来讲讲失败指针。实际上找失败指针的过程,是一个自我匹配的过程。
如图,现在假定我们确定了深度小于2(root深度为1)的所有点的失败指针,现在要确定e。这就相当于我们有了这样一颗Trie:

而文章为’she’,要查找’e’在哪里出现。我们接着匹配’say’,那’y’的失败指针就确定了。
好好想想。前面讲的BFS其实就是自我匹配的过程,这也是和KMP很相似的。
好了,就写到这吧,有不明白可以留言或发邮件给我(drdarkraven@gmail.com),或者在推上fo我(@sdraven)....
DarkRaven原创
做人要厚道,转载请注明出处(否则你将中AC自动机的诅咒,永远A不了题~)
经典介绍
AC自动机简介:
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有字典树Trie和KMP模式匹配算法的基础知识。KMP算法是单模式串的字符匹配算法,AC自动机是多模式串的字符匹配算法。
AC自动机的构造:
1.构造一棵Trie,作为AC自动机的搜索数据结构。
2.构造fail指针,使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。如同 KMP算法一样, AC自动机在匹配时如果当前字符匹配失败,那么利用fail指针进行跳转。由此可知如果跳转,跳转后的串的前缀,必为跳转前的模式串的后缀并且跳转的新位置的深度(匹配字符个数)一定小于跳之前的节点。所以我们可以利用 bfs在 Trie上面进行 fail指针的求解。
3.扫描主串进行匹配。
AC自动机详讲:
我们给出5个单词,say,she,shr,he,her。给定字符串为yasherhs。问多少个单词在字符串中出现过。
一、Trie
首先我们需要建立一棵Trie。但是这棵Trie不是普通的Trie,而是带有一些特殊的性质。
首先会有3个重要的指针,分别为p, p->fail, temp。
1.指针p,指向当前匹配的字符。若p指向root,表示当前匹配的字符序列为空。(root是Trie入口,没有实际含义)。
2.指针p->fail,p的失败指针,指向与字符p相同的结点,若没有,则指向root。
3.指针temp,测试指针(自己命名的,容易理解!~),在建立fail指针时有寻找与p字符匹配的结点的作用,在扫描时作用最大,也最不好理解。
对于Trie树中的一个节点,对应一个序列s[1...m]。此时,p指向字符s[m]。若在下一个字符处失配,即p->next[s[m+1]] == NULL,则由失配指针跳到另一个节点(p->fail)处,该节点对应的序列为s[i...m]。若继续失配,则序列依次跳转直到序列为空或出现匹配。在此过程中,p的值一直在变化,但是p对应节点的字符没有发生变化。在此过程中,我们观察可知,最终求得得序列s则为最长公共后缀。另外,由于这个序列是从root开始到某一节点,则说明这个序列有可能是某些序列的前缀。
再次讨论p指针转移的意义。如果p指针在某一字符s[m+1]处失配(即p->next[s[m+1]] == NULL),则说明没有单词s[1...m+1]存在。此时,如果p的失配指针指向root,则说明当前序列的任意后缀不会是某个单词的前缀。如果p的失配指针不指向root,则说明序列s[i...m]是某一单词的前缀,于是跳转到p的失配指针,以s[i...m]为前缀继续匹配s[m+1]。
对于已经得到的序列s[1...m],由于s[i...m]可能是某单词的后缀,s[1...j]可能是某单词的前缀,所以s[1...m]中可能会出现单词。此时,p指向已匹配的字符,不能动。于是,令temp = p,然后依次测试s[1...m], s[i...m]是否是单词。
构造的Trie为:
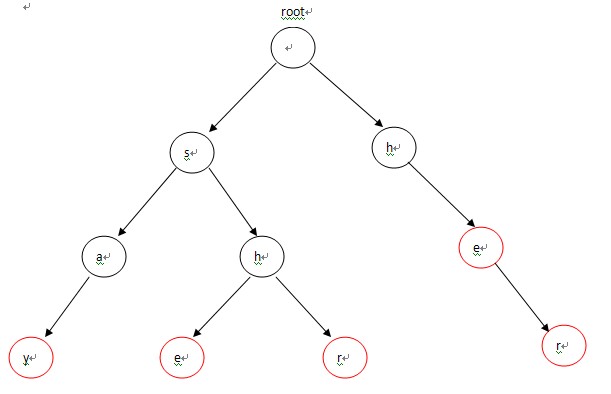
二、构造失败指针
用BFS来构造失败指针,与KMP算法相似的思想。
首先,root入队,第1次循环时处理与root相连的字符,也就是各个单词的第一个字符h和s,因为第一个字符不匹配需要重新匹配,所以第一个字符都指向root(root是Trie入口,没有实际含义)失败指针的指向对应下图中的(1),(2)两条虚线;第2次进入循环后,从队列中先弹出h,接下来p指向h节点的fail指针指向的节点,也就是root;p=p->fail也就是p=NULL说明匹配序列为空,则把节点e的fail指针指向root表示没有匹配序列,对应图-2中的(3),然后节点e进入队列;第3次循环时,弹出的第一个节点a的操作与上一步操作的节点e相同,把a的fail指针指向root,对应图-2中的(4),并入队;第4次进入循环时,弹出节点h(图中左边那个),这时操作略有不同。由于p->next[i]!=NULL(root有h这个儿子节点,图中右边那个),这样便把左边那个h节点的失败指针指向右边那个root的儿子节点h,对应图-2中的(5),然后h入队。以此类推:在循环结束后,所有的失败指针就是图-2中的这种形式。
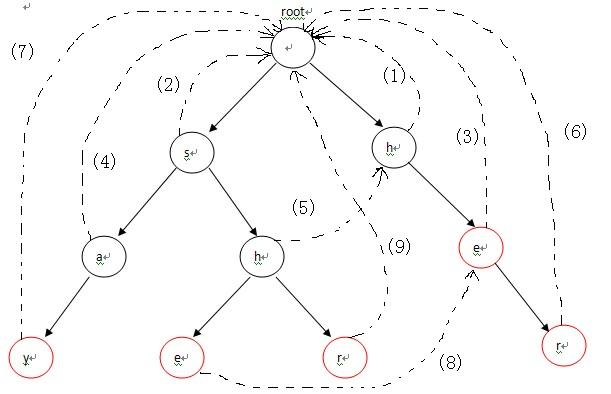
三、扫描
构造好Trie和失败指针后,我们就可以对主串进行扫描了。这个过程和KMP算法很类似,但是也有一定的区别,主要是因为AC自动机处理的是多串模式,需要防止遗漏某个单词,所以引入temp指针。
匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
对照上图,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
到此,AC自动机入门知识就讲完了。HDU 2222入门题必须果断A掉,反正我是参考别人代码敲的。。。
AC自动机貌似还有很多需要优化的地方,等把基础搞定之后再学习一下怎么优化吧。。
关于2222入门题,看下这个博客,代码可能有问题,但是介绍挺好的
http://www.cppblog.com/mythit/archive/2009/04/21/80633.html
关于这题代码,这里有一份数组版加注释,还是挺不错的
另一份整合代码,效率低一些
#define DeBUG
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <cstdlib>
#include <algorithm>
#include <vector>
#include <stack>
#include <queue>
#include <string>
#include <set>
#include <sstream>
#include <map>
#include <list>
#include <bitset>
using namespace std ;
#define zero {0}
#define INF 0x3f3f3f3f
#define EPS 1e-6
typedef long long LL;
const double PI = acos(-1.0);
//#pragma comment(linker, "/STACK:102400000,102400000")
inline int sgn(double x)
{
return fabs(x) < EPS ? 0 : (x < 0 ? -1 : 1);
}
#define N 500010
struct Trie
{
int next
[26], fail
, end
;
int root, L;
int newnode()
{
for (int i = 0; i < 26; i++)
next[L][i] = -1;
end[L++] = 0;
return L - 1;
}
void init()
{
L = 0;
root = newnode();
}
void insert(char buf[])
{
int len = strlen(buf);
int now = root;
for (int i = 0; i < len; i++)
{
if (next[now][buf[i] - 'a'] == -1)
next[now][buf[i] - 'a'] = newnode();
now = next[now][buf[i] - 'a'];
}
end[now]++;
}
void build()
{
queue<int>Q;
fail[root] = root;
for (int i = 0; i < 26; i++)
{
if (next[root][i] == -1)
next[root][i] = root;
else
{
fail[next[root][i]] = root;
Q.push(next[root][i]);
}
}
while (!Q.empty())
{
int now = Q.front();
Q.pop();
for (int i = 0; i < 26; i++)
{
if (next[now][i] == -1)
next[now][i] = next[fail[now]][i];
else
{
fail[next[now][i]] = next[fail[now]][i];
Q.push(next[now][i]);
}
}
}
}
int query(char buf[])
{
int len = strlen(buf);
int now = root;
int res = 0;
for (int i = 0; i < len; i++)
{
now = next[now][buf[i] - 'a'];
int temp = now;
while (temp != root)
{
res += end[temp];
end[temp] = 0;
temp = fail[temp];
}
}
return res;
}
void debug()
{
for (int i = 0; i < L; i++)
{
printf("id = %3d,fail = %3d,end = %3d,chi = [", i, fail[i], end[i]);
for (int j = 0; j < 26; j++)
printf("%2d", next[i][j]);
printf("]\n");
}
}
};
char buf[1000010];
Trie ac;
int main()
{
#ifdef DeBUGs
freopen("C:\\Users\\Sky\\Desktop\\1.in", "r", stdin);
#endif
int T;
int n;
scanf("%d", &T);
while(T--)
{
scanf("%d", &n);
ac.init();
for(int i=0;i<n;i++)
{
scanf("%s", buf);
ac.insert(buf);
}
ac.build();
scanf("%s", buf);
printf("%d\n", ac.query(buf));
}
return 0;
}
更多题目详见
http://www.cnblogs.com/kuangbin/p/3164106.html
AC自动机
关键字:AC自动机 自动机 有限状态自动机 Trie 字母树 字符串匹配 多串匹配算法Note:阅读本文需要有KMP算法基础,如果你不知道什么是KMP,请看这里:
http://www.matrix67.com/blog/article.asp?id=146 (Matrix67大牛写的)
AC自动机是用来处理多串匹配问题的,即给你很多串,再给你一篇文章,让你在文章中找这些串是否出现过,在哪出现。也许你考虑过AC自动机名字的含义,我也有过同样的想法。你现在已经知道KMP了,他之所以叫做KMP,是因为这个算法是由Knuth、Morris、Pratt三个提出来的,取了这三个人的名字的头一个字母。那么AC自动机也是同样的,他是Aho-Corasick。所以不要再YY地认为AC自动机是AC(cept)自动机,虽然他确实能帮你AC一点题目。
。。。扯远了。。。
要学会AC自动机,我们必须知道什么是Trie,即字母树。如果你会了,请跳过这一段
Trie是由字母组成的。
先看张图:
这就是一棵Trie树。用绿色标出的点表示一个单词的末尾(为什么这样表示?看下去就知道了)。树上一条从root到绿色节点的路径上的字母,组成了一个“单词”。
/* 也许你看了这一段,就知道如何构建Trie了,那请跳过以下几段。*/
那么如何来构建一棵Trie呢?就让我从一棵空树开始,一步步来构建他。
一开始,我们有一个root:
现在,插入第一个单词,she。这就相当于在树中插入一条链。过程很简单。插完以后,我们在最后一个字母’e’上加一个绿色标记,结果如图:
再来一个单词,shr(什么词?…..右位移啊)。由于root下已经有’s’了,我们就不重复插入了,同理,由于’s’下有’h’了,我们也略过他,直接在’h’下插入’r’,并把’r’标为绿色。结果如图:
按同样的方法,我们继续把余下的元素插进树中。
最后结果:
也就是这样:
好了,现在我们已经有一棵Trie了,但这还不够,我们还要在Trie上引入一个很强大的东西:失败指针或者说shift数组或者说Next函数 …..你爱怎么叫怎么叫吧,反正就是KMP的精华所在,这也是我为什么叫你看KMP的原因。
KMP中我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符,当A[i+1]<>B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配(从而使得i和j能继续增加)。
Trie树上的失败指针与此类似。
假设有一个节点k,他的失败指针指向j。那么k,j满足这个性质:设root到j的距离为n,则从k之上的第n个节点到k所组成的长度为n的单词,与从root到j所组成的单词相同。
比如图中she中的’e’的失败指针就应该指向her中的’e’。因为:
图中红框部分是完全一样的。
那么我们要怎样构建这个东西呢?其实我们可以用一个简单的BFS搞定这一切。
对于每个节点,我们可以这样处理:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字目也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root
最开始,我们把root加入队列(root的失败指针显然指向自己),这以后我们每处理一个点,就把它的所有儿子加入队列,直到搞完。
至于为什么这样就搞的定,我们讲下去就知道了。
好了,现在我们有了一棵带失败指针的Trie了,而我的文章也破千字了,接下来,我们就要讲AC自动机是怎么工作的了。
AC自动机是个多串匹配,也就是说会有很多串让你查找,我们先把这些串弄成一棵Trie,再搞一下失败指针,然后我们就可以开始AC自动机了。
一开始,Trie中有一个指针t1指向root,待匹配串(也就是“文章”)中有一个指针t2指向串头。
接下来的操作和KMP很相似:如果t2指向的字母,是Trie树中,t1指向的节点的儿子,那么t2+1,t1改为那个儿子的编号,否则t1顺这当前节点的失败指针向上找,直到t2是t1的一个儿子,或者t1指向根。如果t1路过了一个绿色的点,那么以这个点结尾的单词就算出现过了。或者如果t1所在的点可以顺着失败指针走到一个绿色点,那么以那个绿点结尾的单词就算出现过了。
我们现在回过来讲讲失败指针。实际上找失败指针的过程,是一个自我匹配的过程。
如图,现在假定我们确定了深度小于2(root深度为1)的所有点的失败指针,现在要确定e。这就相当于我们有了这样一颗Trie:
而文章为’she’,要查找’e’在哪里出现。我们接着匹配’say’,那’y’的失败指针就确定了。
好好想想。前面讲的BFS其实就是自我匹配的过程,这也是和KMP很相似的。
好了,就写到这吧,有不明白可以留言或发邮件给我(drdarkraven@gmail.com),或者在推上fo我(@sdraven)....
DarkRaven原创
做人要厚道,转载请注明出处(否则你将中AC自动机的诅咒,永远A不了题~)
经典介绍
AC自动机简介:
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有字典树Trie和KMP模式匹配算法的基础知识。KMP算法是单模式串的字符匹配算法,AC自动机是多模式串的字符匹配算法。
AC自动机的构造:
1.构造一棵Trie,作为AC自动机的搜索数据结构。
2.构造fail指针,使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。如同 KMP算法一样, AC自动机在匹配时如果当前字符匹配失败,那么利用fail指针进行跳转。由此可知如果跳转,跳转后的串的前缀,必为跳转前的模式串的后缀并且跳转的新位置的深度(匹配字符个数)一定小于跳之前的节点。所以我们可以利用 bfs在 Trie上面进行 fail指针的求解。
3.扫描主串进行匹配。
AC自动机详讲:
我们给出5个单词,say,she,shr,he,her。给定字符串为yasherhs。问多少个单词在字符串中出现过。
一、Trie
首先我们需要建立一棵Trie。但是这棵Trie不是普通的Trie,而是带有一些特殊的性质。
首先会有3个重要的指针,分别为p, p->fail, temp。
1.指针p,指向当前匹配的字符。若p指向root,表示当前匹配的字符序列为空。(root是Trie入口,没有实际含义)。
2.指针p->fail,p的失败指针,指向与字符p相同的结点,若没有,则指向root。
3.指针temp,测试指针(自己命名的,容易理解!~),在建立fail指针时有寻找与p字符匹配的结点的作用,在扫描时作用最大,也最不好理解。
对于Trie树中的一个节点,对应一个序列s[1...m]。此时,p指向字符s[m]。若在下一个字符处失配,即p->next[s[m+1]] == NULL,则由失配指针跳到另一个节点(p->fail)处,该节点对应的序列为s[i...m]。若继续失配,则序列依次跳转直到序列为空或出现匹配。在此过程中,p的值一直在变化,但是p对应节点的字符没有发生变化。在此过程中,我们观察可知,最终求得得序列s则为最长公共后缀。另外,由于这个序列是从root开始到某一节点,则说明这个序列有可能是某些序列的前缀。
再次讨论p指针转移的意义。如果p指针在某一字符s[m+1]处失配(即p->next[s[m+1]] == NULL),则说明没有单词s[1...m+1]存在。此时,如果p的失配指针指向root,则说明当前序列的任意后缀不会是某个单词的前缀。如果p的失配指针不指向root,则说明序列s[i...m]是某一单词的前缀,于是跳转到p的失配指针,以s[i...m]为前缀继续匹配s[m+1]。
对于已经得到的序列s[1...m],由于s[i...m]可能是某单词的后缀,s[1...j]可能是某单词的前缀,所以s[1...m]中可能会出现单词。此时,p指向已匹配的字符,不能动。于是,令temp = p,然后依次测试s[1...m], s[i...m]是否是单词。
构造的Trie为:
二、构造失败指针
用BFS来构造失败指针,与KMP算法相似的思想。
首先,root入队,第1次循环时处理与root相连的字符,也就是各个单词的第一个字符h和s,因为第一个字符不匹配需要重新匹配,所以第一个字符都指向root(root是Trie入口,没有实际含义)失败指针的指向对应下图中的(1),(2)两条虚线;第2次进入循环后,从队列中先弹出h,接下来p指向h节点的fail指针指向的节点,也就是root;p=p->fail也就是p=NULL说明匹配序列为空,则把节点e的fail指针指向root表示没有匹配序列,对应图-2中的(3),然后节点e进入队列;第3次循环时,弹出的第一个节点a的操作与上一步操作的节点e相同,把a的fail指针指向root,对应图-2中的(4),并入队;第4次进入循环时,弹出节点h(图中左边那个),这时操作略有不同。由于p->next[i]!=NULL(root有h这个儿子节点,图中右边那个),这样便把左边那个h节点的失败指针指向右边那个root的儿子节点h,对应图-2中的(5),然后h入队。以此类推:在循环结束后,所有的失败指针就是图-2中的这种形式。
三、扫描
构造好Trie和失败指针后,我们就可以对主串进行扫描了。这个过程和KMP算法很类似,但是也有一定的区别,主要是因为AC自动机处理的是多串模式,需要防止遗漏某个单词,所以引入temp指针。
匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
对照上图,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
到此,AC自动机入门知识就讲完了。HDU 2222入门题必须果断A掉,反正我是参考别人代码敲的。。。
AC自动机貌似还有很多需要优化的地方,等把基础搞定之后再学习一下怎么优化吧。。
关于2222入门题,看下这个博客,代码可能有问题,但是介绍挺好的
http://www.cppblog.com/mythit/archive/2009/04/21/80633.html
关于这题代码,这里有一份数组版加注释,还是挺不错的
//hdu2222
//ACauto
//构造失败指针:设当前节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的。然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。
//匹配(1)当前字符匹配,只需沿该路径走向下一个节点继续匹配即可;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配.重复这2个过程中的一个,直到模式串走完。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<queue>
#define cha 26
#define Root 0
#define N 500001
using namespace std;
struct node
{
int data;//结点信息
int count;//从根到此处是否是关键字,并且记录是多少个关键字的结尾
int fail;
int next[cha];
} tree
;
void init(node &a, int data)
{
a.data = data;
a.count = 0;
a.fail = Root;
for (int i = 0; i < cha; i++)
a.next[i] = -1;
}
int k = 1;
void Insert(char s[])
{
int p = Root;
for (int i = 0; s[i]; i++)
{
int data = s[i] - 'a';
if (tree[p].next[data] == -1) //不存在该结点
{
init(tree[k], data);
tree[p].next[data] = k;
k++;
}
p = tree[p].next[data];
}
tree[p].count++;
}
queue<node> q;
void AC_automation()
{
q.push(tree[Root]);
while (!q.empty())
{
node k = q.front();
q.pop();
for (int j = 0; j < cha; j++)
{
if ( k.next[j] != -1 )
{
if ( k.data == -1 ) tree[k.next[j]].fail = Root;
else
{
int t = k.fail;
while ( t != Root && tree[t].next[j] == -1 ) t = tree[t].fail;
tree[ k.next[j] ].fail = max( tree[t].next[j], Root );
}
q.push(tree[k.next[j]]);
}
}
}
}
int get_ans(char s[])
{
int k = Root, ans = 0;
for (int i = 0; s[i]; i++)
{
int t = s[i] - 'a';
while (tree[k].next[t] == -1 && k ) k = tree[k].fail;
k = tree[k].next[t];
if (k == -1)
{
k = Root;
continue;
}
int j = k;
while ( tree[j].count )
{
ans += tree[j].count;
tree[j].count = 0;
j = tree[j].fail;
}
//下面两句很重要,如果走到头以后当前字母不是关键字终点然而其fail指针指向字母是关键字终点的话,
//应当加入此关键值,而网上大多数程序忽视了这一点导致hdu的discuss里反例过不了
ans += tree[ tree[j].fail ].count;
tree[ tree[j].fail ].count = 0;
}
return ans;
}
char tar[2 * N];
int main()
{
// freopen("C:\\Users\\Sky\\Desktop\\1.in","r",stdin);
int T, n;
scanf("%d", &T);
while (T--)
{
scanf("%d", &n);
init(tree[Root], -1);
char a[55];
while (n--)
{
scanf("%s", a);
Insert(a);
}
AC_automation();
scanf("%s", tar);
printf("%d\n", get_ans(tar));
}
return 0;
}另一份整合代码,效率低一些
#define DeBUG
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cmath>
#include <cstdlib>
#include <algorithm>
#include <vector>
#include <stack>
#include <queue>
#include <string>
#include <set>
#include <sstream>
#include <map>
#include <list>
#include <bitset>
using namespace std ;
#define zero {0}
#define INF 0x3f3f3f3f
#define EPS 1e-6
typedef long long LL;
const double PI = acos(-1.0);
//#pragma comment(linker, "/STACK:102400000,102400000")
inline int sgn(double x)
{
return fabs(x) < EPS ? 0 : (x < 0 ? -1 : 1);
}
#define N 500010
struct Trie
{
int next
[26], fail
, end
;
int root, L;
int newnode()
{
for (int i = 0; i < 26; i++)
next[L][i] = -1;
end[L++] = 0;
return L - 1;
}
void init()
{
L = 0;
root = newnode();
}
void insert(char buf[])
{
int len = strlen(buf);
int now = root;
for (int i = 0; i < len; i++)
{
if (next[now][buf[i] - 'a'] == -1)
next[now][buf[i] - 'a'] = newnode();
now = next[now][buf[i] - 'a'];
}
end[now]++;
}
void build()
{
queue<int>Q;
fail[root] = root;
for (int i = 0; i < 26; i++)
{
if (next[root][i] == -1)
next[root][i] = root;
else
{
fail[next[root][i]] = root;
Q.push(next[root][i]);
}
}
while (!Q.empty())
{
int now = Q.front();
Q.pop();
for (int i = 0; i < 26; i++)
{
if (next[now][i] == -1)
next[now][i] = next[fail[now]][i];
else
{
fail[next[now][i]] = next[fail[now]][i];
Q.push(next[now][i]);
}
}
}
}
int query(char buf[])
{
int len = strlen(buf);
int now = root;
int res = 0;
for (int i = 0; i < len; i++)
{
now = next[now][buf[i] - 'a'];
int temp = now;
while (temp != root)
{
res += end[temp];
end[temp] = 0;
temp = fail[temp];
}
}
return res;
}
void debug()
{
for (int i = 0; i < L; i++)
{
printf("id = %3d,fail = %3d,end = %3d,chi = [", i, fail[i], end[i]);
for (int j = 0; j < 26; j++)
printf("%2d", next[i][j]);
printf("]\n");
}
}
};
char buf[1000010];
Trie ac;
int main()
{
#ifdef DeBUGs
freopen("C:\\Users\\Sky\\Desktop\\1.in", "r", stdin);
#endif
int T;
int n;
scanf("%d", &T);
while(T--)
{
scanf("%d", &n);
ac.init();
for(int i=0;i<n;i++)
{
scanf("%s", buf);
ac.insert(buf);
}
ac.build();
scanf("%s", buf);
printf("%d\n", ac.query(buf));
}
return 0;
}
更多题目详见
http://www.cnblogs.com/kuangbin/p/3164106.html

相关文章推荐
- Andorid中xml资料汇总
- ajax提交form表单资料详细汇总
- 机器学习&深度学习视频资料大汇总
- python的nltk中文使用和学习资料汇总帮你入门提高
- django学习资料网址汇总
- tolua学习资料汇总贴
- 115个Oracle免积分资料(教程+工具+源码)地址汇总
- Windows Phone7 学习资料汇总。
- 158个JAVA免豆精品资料汇总
- EBS系统管理常用SQL语句整理汇总(参考网上资料&其他人博客)
- XGBoost学习资料汇总
- .Net最新精品资料汇总 C# 2008 经典大放送
- [VCAP5] VCAP5-DCA DCD学习资料汇总 存储(VDCA510为主)
- iOS超全开源框架、项目和学习资料汇总(3)网络和Model篇
- 程序员常访问的国外技术交流网站汇总(附NLP入门资料链接)
- 决策树资料汇总
- cisco live 2008 PDF资料精华汇总
- java异常处理学习资料汇总
- 数据库相关的资料汇总
- [置顶] 树莓派Android Things物联网开发:入门及资料汇总