Lucene学习总结之七:Lucene搜索过程解析
2014-06-25 14:23
399 查看
一、Lucene搜索过程总论
搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程。其可用如下图示:

总共包括以下几个过程:
IndexReader打开索引文件,读取并打开指向索引文件的流。
用户输入查询语句
将查询语句转换为查询对象Query对象树
构造Weight对象树,用于计算词的权重Term Weight,也即计算打分公式中与仅与搜索语句相关与文档无关的部分(红色部分)。
构造Scorer对象树,用于计算打分(TermScorer.score())。
在构造Scorer对象树的过程中,其叶子节点的TermScorer会将词典和倒排表从索引中读出来。
构造SumScorer对象树,其是为了方便合并倒排表对Scorer对象树的从新组织,它的叶子节点仍为TermScorer,包含词典和倒排表。此步将倒排表合并后得到结果文档集,并对结果文档计算打分公式中的蓝色部分。打分公式中的求和符合,并非简单的相加,而是根据子查询倒排表的合并方式(与或非)来对子查询的打分求和,计算出父查询的打分。
将收集的结果集合及打分返回给用户。
二、Lucene搜索详细过程
为了解析Lucene对索引文件搜索的过程,预先写入索引了如下几个文件:file01.txt: apple apples cat dog
file02.txt: apple boy cat category
file03.txt: apply dog eat etc
file04.txt: apply cat foods
2.1、打开IndexReader指向索引文件夹
代码为:IndexReader reader = IndexReader.open(FSDirectory.open(indexDir));
其实是调用了DirectoryReader.open(Directory, IndexDeletionPolicy, IndexCommit, boolean, int) 函数,其主要作用是生成一个SegmentInfos.FindSegmentsFile对象,并用它来找到此索引文件中所有的段,并打开这些段。
SegmentInfos.FindSegmentsFile.run(IndexCommit commit)主要做以下事情:
2.1.1、找到最新的segment_N文件
由于segment_N是整个索引中总的元数据,因而正确的选择segment_N更加重要。然而有时候为了使得索引能够保存在另外的存储系统上,有时候需要用NFS mount一个远程的磁盘来存放索引,然而NFS为了提高性能,在本地有Cache,因而有可能使得此次打开的索引不是另外的writer写入的最新信息,所以在此处用了双保险。
一方面,列出所有的segment_N,并取出其中的最大的N,设为genA
| String[] files = directory.listAll(); long genA = getCurrentSegmentGeneration(files); |
| long getCurrentSegmentGeneration(String[] files) { long max = -1; for (int i = 0; i < files.length; i++) { String file = files[i]; if (file.startsWith(IndexFileNames.SEGMENTS) //"segments_N" && !file.equals(IndexFileNames.SEGMENTS_GEN)) { //"segments.gen" long gen = generationFromSegmentsFileName(file); if (gen > max) { max = gen; } } } return max; } |
| IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN); int version = genInput.readInt(); long gen0 = genInput.readLong(); long gen1 = genInput.readLong(); if (gen0 == gen1) { genB = gen0; } |
| if (genA > genB) gen = genA; else gen = genB; String segmentFileName = IndexFileNames.fileNameFromGeneration(IndexFileNames.SEGMENTS, "", gen); //segmentFileName "segments_4" |
2.1.2、通过segment_N文件中保存的各个段的信息打开各个段
从segment_N中读出段的元数据信息,生成SegmentInfos| SegmentInfos infos = new SegmentInfos(); infos.read(directory, segmentFileName); |
| SegmentInfos.read(Directory, String) 代码如下: int format = input.readInt(); version = input.readLong(); counter = input.readInt(); for (int i = input.readInt(); i > 0; i—) { //读出每一个段,并构造SegmentInfo对象 add(new SegmentInfo(directory, format, input)); } |
| SegmentInfo(Directory dir, int format, IndexInput input)构造函数如下: name = input.readString(); docCount = input.readInt(); delGen = input.readLong(); docStoreOffset = input.readInt(); if (docStoreOffset != -1) { docStoreSegment = input.readString(); docStoreIsCompoundFile = (1 == input.readByte()); } else { docStoreSegment = name; docStoreIsCompoundFile = false; } hasSingleNormFile = (1 == input.readByte()); int numNormGen = input.readInt(); normGen = new long[numNormGen]; for(int j=0;j normGen[j] = input.readLong(); } isCompoundFile = input.readByte(); delCount = input.readInt(); hasProx = input.readByte() == 1; 其实不用多介绍,看过Lucene学习总结之三:Lucene的索引文件格式 (2)一章,就很容易明白。 |
| SegmentReader[] readers = new SegmentReader[sis.size()]; for (int i = sis.size()-1; i >= 0; i—) { //打开每一个段 readers[i] = SegmentReader.get(readOnly, sis.info(i), termInfosIndexDivisor); } |
| SegmentReader.get(boolean, Directory, SegmentInfo, int, boolean, int) 代码如下: instance.core = new CoreReaders(dir, si, readBufferSize, termInfosIndexDivisor); instance.core.openDocStores(si); //生成用于读取存储域和词向量的对象。 instance.loadDeletedDocs(); //读取被删除文档(.del)文件 instance.openNorms(instance.core.cfsDir, readBufferSize); //读取标准化因子(.nrm) |
| CoreReaders(Directory dir, SegmentInfo si, int readBufferSize, int termsIndexDivisor)构造函数代码如下: cfsReader = new CompoundFileReader(dir, segment + "." + IndexFileNames.COMPOUND_FILE_EXTENSION, readBufferSize); //读取cfs的reader fieldInfos = new FieldInfos(cfsDir, segment + "." + IndexFileNames.FIELD_INFOS_EXTENSION); //读取段元数据信息(.fnm) TermInfosReader reader = new TermInfosReader(cfsDir, segment, fieldInfos, readBufferSize, termsIndexDivisor); //用于读取词典信息(.tii .tis) freqStream = cfsDir.openInput(segment + "." + IndexFileNames.FREQ_EXTENSION, readBufferSize); //用于读取freq proxStream = cfsDir.openInput(segment + "." + IndexFileNames.PROX_EXTENSION, readBufferSize); //用于读取prox |
| FieldInfos(Directory d, String name)构造函数如下: IndexInput input = d.openInput(name); int firstInt = input.readVInt(); size = input.readVInt(); for (int i = 0; i < size; i++) { //读取域名 String name = StringHelper.intern(input.readString()); //读取域的各种标志位 byte bits = input.readByte(); boolean isIndexed = (bits & IS_INDEXED) != 0; boolean storeTermVector = (bits & STORE_TERMVECTOR) != 0; boolean storePositionsWithTermVector = (bits & STORE_POSITIONS_WITH_TERMVECTOR) != 0; boolean storeOffsetWithTermVector = (bits & STORE_OFFSET_WITH_TERMVECTOR) != 0; boolean omitNorms = (bits & OMIT_NORMS) != 0; boolean storePayloads = (bits & STORE_PAYLOADS) != 0; boolean omitTermFreqAndPositions = (bits & OMIT_TERM_FREQ_AND_POSITIONS) != 0; //将读出的域生成FieldInfo对象,加入fieldinfos进行管理 addInternal(name, isIndexed, storeTermVector, storePositionsWithTermVector, storeOffsetWithTermVector, omitNorms, storePayloads, omitTermFreqAndPositions); } |
| CoreReaders.openDocStores(SegmentInfo)主要代码如下: fieldsReaderOrig = new FieldsReader(storeDir, storesSegment, fieldInfos, readBufferSize, si.getDocStoreOffset(), si.docCount); //用于读取存储域(.fdx, .fdt) termVectorsReaderOrig = new TermVectorsReader(storeDir, storesSegment, fieldInfos, readBufferSize, si.getDocStoreOffset(), si.docCount); //用于读取词向量(.tvx, .tvd, .tvf) |
| 在Lucene中,每个段中的文档编号都是从0开始的,而一个索引有多个段,需要重新进行编号,于是维护数组start[],来保存每个段的文档号的偏移量,从而第i个段的文档号是从start[i]至start[i]+Num private void initialize(SegmentReader[] subReaders) { this.subReaders = subReaders; starts = new int[subReaders.length + 1]; for (int i = 0; i < subReaders.length; i++) { starts[i] = maxDoc; maxDoc += subReaders[i].maxDoc(); if (subReaders[i].hasDeletions()) hasDeletions = true; } starts[subReaders.length] = maxDoc; } |
2.1.3、得到的IndexReader对象如下
| reader ReadOnlyDirectoryReader (id=466) closed false deletionPolicy null //索引文件夹 directory SimpleFSDirectory (id=31) checked false chunkSize 104857600 directory File (id=487) path "D://lucene-3.0.0//TestSearch//index" prefixLength 3 isOpen true lockFactory NativeFSLockFactory (id=488) hasChanges false hasDeletions false maxDoc 12 normsCache HashMap (id=483) numDocs -1 readOnly true refCount 1 rollbackHasChanges false rollbackSegmentInfos null //段元数据信息 segmentInfos SegmentInfos (id=457) elementCount 3 elementData Object[10] (id=532) [0] SegmentInfo (id=464) delCount 0 delGen -1 diagnostics HashMap (id=537) dir SimpleFSDirectory (id=31) docCount 4 docStoreIsCompoundFile false docStoreOffset -1 docStoreSegment "_0" files null hasProx true hasSingleNormFile true isCompoundFile 1 name "_0" normGen null preLockless false sizeInBytes -1 [1] SegmentInfo (id=517) delCount 0 delGen -1 diagnostics HashMap (id=542) dir SimpleFSDirectory (id=31) docCount 4 docStoreIsCompoundFile false docStoreOffset -1 docStoreSegment "_1" files null hasProx true hasSingleNormFile true isCompoundFile 1 name "_1" normGen null preLockless false sizeInBytes -1 [2] SegmentInfo (id=470) delCount 0 delGen -1 diagnostics HashMap (id=547) dir SimpleFSDirectory (id=31) docCount 4 docStoreIsCompoundFile false docStoreOffset -1 docStoreSegment "_2" files null hasProx true hasSingleNormFile true isCompoundFile 1 name "_2" normGen null preLockless false sizeInBytes -1 generation 4 lastGeneration 4 modCount 4 pendingSegnOutput null userData HashMap (id=533) version 1268193441675 segmentInfosStart null stale false starts int[4] (id=484) //每个段的Reader subReaders SegmentReader[3] (id=467) [0] ReadOnlySegmentReader (id=492) closed false core SegmentReader$CoreReaders (id=495) cfsDir CompoundFileReader (id=552) cfsReader CompoundFileReader (id=552) dir SimpleFSDirectory (id=31) fieldInfos FieldInfos (id=553) fieldsReaderOrig FieldsReader (id=554) freqStream CompoundFileReader$CSIndexInput (id=555) proxStream CompoundFileReader$CSIndexInput (id=556) readBufferSize 1024 ref SegmentReader$Ref (id=557) segment "_0" storeCFSReader null termsIndexDivisor 1 termVectorsReaderOrig null tis TermInfosReader (id=558) tisNoIndex null deletedDocs null deletedDocsDirty false deletedDocsRef null fieldsReaderLocal SegmentReader$FieldsReaderLocal (id=496) hasChanges false norms HashMap (id=500) normsDirty false pendingDeleteCount 0 readBufferSize 1024 readOnly true refCount 1 rollbackDeletedDocsDirty false rollbackHasChanges false rollbackNormsDirty false rollbackPendingDeleteCount 0 si SegmentInfo (id=464) singleNormRef SegmentReader$Ref (id=504) singleNormStream CompoundFileReader$CSIndexInput (id=506) termVectorsLocal CloseableThreadLocal (id=508) [1] ReadOnlySegmentReader (id=493) closed false core SegmentReader$CoreReaders (id=511) cfsDir CompoundFileReader (id=561) cfsReader CompoundFileReader (id=561) dir SimpleFSDirectory (id=31) fieldInfos FieldInfos (id=562) fieldsReaderOrig FieldsReader (id=563) freqStream CompoundFileReader$CSIndexInput (id=564) proxStream CompoundFileReader$CSIndexInput (id=565) readBufferSize 1024 ref SegmentReader$Ref (id=566) segment "_1" storeCFSReader null termsIndexDivisor 1 termVectorsReaderOrig null tis TermInfosReader (id=567) tisNoIndex null deletedDocs null deletedDocsDirty false deletedDocsRef null fieldsReaderLocal SegmentReader$FieldsReaderLocal (id=512) hasChanges false norms HashMap (id=514) normsDirty false pendingDeleteCount 0 readBufferSize 1024 readOnly true refCount 1 rollbackDeletedDocsDirty false rollbackHasChanges false rollbackNormsDirty false rollbackPendingDeleteCount 0 si SegmentInfo (id=517) singleNormRef SegmentReader$Ref (id=519) singleNormStream CompoundFileReader$CSIndexInput (id=520) termVectorsLocal CloseableThreadLocal (id=521) [2] ReadOnlySegmentReader (id=471) closed false core SegmentReader$CoreReaders (id=475) cfsDir CompoundFileReader (id=476) cfsReader CompoundFileReader (id=476) dir SimpleFSDirectory (id=31) fieldInfos FieldInfos (id=480) fieldsReaderOrig FieldsReader (id=570) freqStream CompoundFileReader$CSIndexInput (id=571) proxStream CompoundFileReader$CSIndexInput (id=572) readBufferSize 1024 ref SegmentReader$Ref (id=573) segment "_2" storeCFSReader null termsIndexDivisor 1 termVectorsReaderOrig null tis TermInfosReader (id=574) tisNoIndex null deletedDocs null deletedDocsDirty false deletedDocsRef null fieldsReaderLocal SegmentReader$FieldsReaderLocal (id=524) hasChanges false norms HashMap (id=525) normsDirty false pendingDeleteCount 0 readBufferSize 1024 readOnly true refCount 1 rollbackDeletedDocsDirty false rollbackHasChanges false rollbackNormsDirty false rollbackPendingDeleteCount 0 si SegmentInfo (id=470) singleNormRef SegmentReader$Ref (id=527) singleNormStream CompoundFileReader$CSIndexInput (id=528) termVectorsLocal CloseableThreadLocal (id=530) synced HashSet (id=485) termInfosIndexDivisor 1 writeLock null writer null |
段元数据信息已经被读入到内存中,因而索引文件夹中因为新添加文档而新增加的段对已经打开的reader是不可见的。
.del文件已经读入内存,因而其他的reader或者writer删除的文档对打开的reader也是不可见的。
打开的reader已经有inputstream指向cfs文件,从段合并的过程我们知道,一个段文件从生成起就不会改变,新添加的文档都在新的段中,删除的文档都在.del中,段之间的合并是生成新的段,而不会改变旧的段,只不过在段的合并过程中,会将旧的段文件删除,这没有问题,因为从操作系统的角度来讲,一旦一个文件被打开一个inputstream也即打开了一个文件描述符,在内核中,此文件会保持reference count,只要reader还没有关闭,文件描述符还在,文件是不会被删除的,仅仅reference
count减一。
以上三点保证了IndexReader的snapshot的性质,也即一个IndexReader打开一个索引,就好像对此索引照了一张像,无论背后索引如何改变,此IndexReader在被重新打开之前,看到的信息总是相同的。
严格的来讲,Lucene的文档号仅仅对打开的某个reader有效,当索引发生了变化,再打开另外一个reader的时候,前面reader的文档0就不一定是后面reader的文档0了,因而我们进行查询的时候,从结果中得到文档号的时候,一定要在reader关闭之前应用,从存储域中得到真正能够唯一标识你的业务逻辑中的文档的信息,如url,md5等等,一旦reader关闭了,则文档号已经无意义,如果用其他的reader查询这些文档号,得到的可能是不期望的文档。
2.2、打开IndexSearcher
代码为:IndexSearcher searcher = new IndexSearcher(reader);
其过程非常简单:
| private IndexSearcher(IndexReader r, boolean closeReader) { reader = r; //当关闭searcher的时候,是否关闭其reader this.closeReader = closeReader; //对文档号进行编号 List subReadersList = new ArrayList(); gatherSubReaders(subReadersList, reader); subReaders = subReadersList.toArray(new IndexReader[subReadersList.size()]); docStarts = new int[subReaders.length]; int maxDoc = 0; for (int i = 0; i < subReaders.length; i++) { docStarts[i] = maxDoc; maxDoc += subReaders[i].maxDoc(); } } |
void setSimilarity(Similarity similarity),用户可以实现自己的Similarity对象,从而影响搜索过程的打分,详见有关Lucene的问题(4):影响Lucene对文档打分的四种方式
一系列search函数,是搜索过程的关键,主要负责打分的计算和倒排表的合并。
因而在某些应用之中,只想得到某个词的倒排表的时候,最好不要用IndexSearcher,而直接用IndexReader.termDocs(Term term),则省去了打分的计算。
2.3、QueryParser解析查询语句生成查询对象
代码为:| QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "contents", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse("+(+apple* -boy) (cat* dog) -(eat~ foods)"); |
此处唯一要说明的是,根据查询语句生成的是一个Query树,这棵树很重要,并且会生成其他的树,一直贯穿整个索引过程。
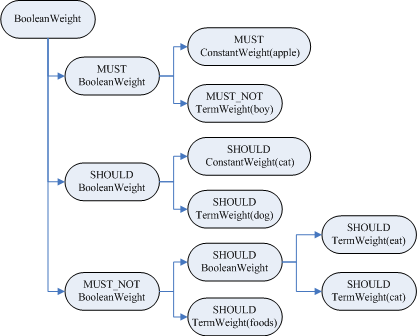
| query BooleanQuery (id=96) | boost 1.0 | clauses ArrayList (id=98) | elementData Object[10] (id=100) |------[0] BooleanClause (id=102) | | occur BooleanClause$Occur$1 (id=106) | | name "MUST" //AND | | ordinal 0 | |---query BooleanQuery (id=108) | | boost 1.0 | | clauses ArrayList (id=112) | | elementData Object[10] (id=113) | |------[0] BooleanClause (id=114) | | | occur BooleanClause$Occur$1 (id=106) | | | name "MUST" //AND | | | ordinal 0 | | |--query PrefixQuery (id=116) | | boost 1.0 | | numberOfTerms 0 | | prefix Term (id=117) | | field "contents" | | text "apple" | | rewriteMethod MultiTermQuery$1 (id=119) | | docCountPercent 0.1 | | termCountCutoff 350 | |------[1] BooleanClause (id=115) | | occur BooleanClause$Occur$3 (id=123) | | name "MUST_NOT" //NOT | | ordinal 2 | |--query TermQuery (id=125) | boost 1.0 | term Term (id=127) | field "contents" | text "boy" | size 2 | disableCoord false | minNrShouldMatch 0 |------[1] BooleanClause (id=104) | | occur BooleanClause$Occur$2 (id=129) | | name "SHOULD" //OR | | ordinal 1 | |---query BooleanQuery (id=131) | | boost 1.0 | | clauses ArrayList (id=133) | | elementData Object[10] (id=134) | |------[0] BooleanClause (id=135) | | | occur BooleanClause$Occur$2 (id=129) | | | name "SHOULD" //OR | | | ordinal 1 | | |--query PrefixQuery (id=137) | | boost 1.0 | | numberOfTerms 0 | | prefix Term (id=138) | | field "contents" | | text "cat" | | rewriteMethod MultiTermQuery$1 (id=119) | | docCountPercent 0.1 | | termCountCutoff 350 | |------[1] BooleanClause (id=136) | | occur BooleanClause$Occur$2 (id=129) | | name "SHOULD" //OR | | ordinal 1 | |--query TermQuery (id=140) | boost 1.0 | term Term (id=141) | field "contents" | text "dog" | size 2 | disableCoord false | minNrShouldMatch 0 |------[2] BooleanClause (id=105) | occur BooleanClause$Occur$3 (id=123) | name "MUST_NOT" //NOT | ordinal 2 |---query BooleanQuery (id=143) | boost 1.0 | clauses ArrayList (id=146) | elementData Object[10] (id=147) |------[0] BooleanClause (id=148) | | occur BooleanClause$Occur$2 (id=129) | | name "SHOULD" //OR | | ordinal 1 | |--query FuzzyQuery (id=150) | boost 1.0 | minimumSimilarity 0.5 | numberOfTerms 0 | prefixLength 0 | rewriteMethod MultiTermQuery$ScoringBooleanQueryRewrite (id=152) | term Term (id=153) | field "contents" | text "eat" | termLongEnough true |------[1] BooleanClause (id=149) | occur BooleanClause$Occur$2 (id=129) | name "SHOULD" //OR | ordinal 1 |--query TermQuery (id=155) boost 1.0 term Term (id=156) field "contents" text "foods" size 2 disableCoord false minNrShouldMatch 0 size 3 disableCoord false minNrShouldMatch 0 |

对于Query对象有以下说明:
BooleanQuery即所有的子语句按照布尔关系合并
+也即MUST表示必须满足的语句
SHOULD表示可以满足的,minNrShouldMatch表示在SHOULD中必须满足的最小语句个数,默认是0,也即既然是SHOULD,也即或的关系,可以一个也不满足(当然没有MUST的时候除外)。
-也即MUST_NOT表示必须不能满足的语句
树的叶子节点中:
最基本的是TermQuery,也即表示一个词
当然也可以是PrefixQuery和FuzzyQuery,这些查询语句由于特殊的语法,可能对应的不是一个词,而是多个词,因而他们都有rewriteMethod对象指向MultiTermQuery的Inner Class,表示对应多个词,在查询过程中会得到特殊处理。
2.4、搜索查询对象
代码为:TopDocs docs = searcher.search(query, 50);
其最终调用search(createWeight(query), filter, n);
索引过程包含以下子过程:
创建weight树,计算term weight
创建scorer及SumScorer树,为合并倒排表做准备
用SumScorer进行倒排表合并
收集文档结果集合及计算打分
2.4.1、创建Weight对象树,计算Term Weight
IndexSearcher(Searcher).createWeight(Query) 代码如下:| protected Weight createWeight(Query query) throws IOException { return query.weight(this); } |
| BooleanQuery(Query).weight(Searcher) 代码为: public Weight weight(Searcher searcher) throws IOException { //重写Query对象树 Query query = searcher.rewrite(this); //创建Weight对象树 Weight weight = query.createWeight(searcher); //计算Term Weight分数 float sum = weight.sumOfSquaredWeights(); float norm = getSimilarity(searcher).queryNorm(sum); weight.normalize(norm); return weight; } |
重写Query对象树
创建Weight对象树
计算Term Weight分数
[b]2.4.1.1、重写Query对象树[/b]
从BooleanQuery的rewrite函数我们可以看出,重写过程也是一个递归的过程,一直到Query对象树的叶子节点。
| BooleanQuery.rewrite(IndexReader) 代码如下: BooleanQuery clone = null; for (int i = 0 ; i < clauses.size(); i++) { BooleanClause c = clauses.get(i); //对每一个子语句的Query对象进行重写 Query query = c.getQuery().rewrite(reader); if (query != c.getQuery()) { if (clone == null) clone = (BooleanQuery)this.clone(); //重写后的Query对象加入复制的新Query对象树 clone.clauses.set(i, new BooleanClause(query, c.getOccur())); } } if (clone != null) { return clone; //如果有子语句被重写,则返回复制的新Query对象树。 } else return this; //否则将老的Query对象树返回。 |
对此类的Query,Lucene不能够直接进行查询,必须进行重写处理:
首先,要从索引文件的词典中,把多个Term都找出来,比如"appl*",我们在索引文件的词典中可以找到如下Term:"apple","apples","apply",这些Term都要参与查询过程,而非原来的"appl*"参与查询过程,因为词典中根本就没有"appl*"。
然后,将取出的多个Term重新组织成新的Query对象进行查询,基本有两种方式:
方式一:将多个Term看成一个Term,将包含它们的文档号取出来放在一起(DocId Set),作为一个统一的倒排表来参与倒排表的合并。
方式二:将多个Term组成一个BooleanQuery,它们之间是OR的关系。
从上面的Query对象树中,我们可以看到,MultiTermQuery都有一个RewriteMethod成员变量,就是用来重写Query对象的,有以下几种:
ConstantScoreFilterRewrite采取的是方式一,其rewrite函数实现如下:
| public Query rewrite(IndexReader reader, MultiTermQuery query) { Query result = new ConstantScoreQuery(new MultiTermQueryWrapperFilter(query)); result.setBoost(query.getBoost()); return result; } |
| MultiTermQueryWrapperFilter中的getDocIdSet函数实现如下: public DocIdSet getDocIdSet(IndexReader reader) throws IOException { //得到MultiTermQuery的Term枚举器 final TermEnum enumerator = query.getEnum(reader); try { if (enumerator.term() == null) return DocIdSet.EMPTY_DOCIDSET; //创建包含多个Term的文档号集合 final OpenBitSet bitSet = new OpenBitSet(reader.maxDoc()); final int[] docs = new int[32]; final int[] freqs = new int[32]; TermDocs termDocs = reader.termDocs(); try { int termCount = 0; //一个循环,取出对应MultiTermQuery的所有的Term,取出他们的文档号,加入集合 do { Term term = enumerator.term(); if (term == null) break; termCount++; termDocs.seek(term); while (true) { final int count = termDocs.read(docs, freqs); if (count != 0) { for(int i=0;i bitSet.set(docs[i]); } } else { break; } } } while (enumerator.next()); query.incTotalNumberOfTerms(termCount); } finally { termDocs.close(); } return bitSet; } finally { enumerator.close(); } } |
| public Query rewrite(IndexReader reader, MultiTermQuery query) throws IOException { //得到MultiTermQuery的Term枚举器 FilteredTermEnum enumerator = query.getEnum(reader); BooleanQuery result = new BooleanQuery(true); int count = 0; try { //一个循环,取出对应MultiTermQuery的所有的Term,加入BooleanQuery do { Term t = enumerator.term(); if (t != null) { TermQuery tq = new TermQuery(t); tq.setBoost(query.getBoost() * enumerator.difference()); result.add(tq, BooleanClause.Occur.SHOULD); count++; } } while (enumerator.next()); } finally { enumerator.close(); } query.incTotalNumberOfTerms(count); return result; } |
方式一使得MultiTermQuery对应的所有的Term看成一个Term,组成一个docid set,作为统一的倒排表参与倒排表的合并,这样无论这样的Term在索引中有多少,都只会有一个倒排表参与合并,不会产生TooManyClauses异常,也使得性能得到提高。但是多个Term之间的tf, idf等差别将被忽略,所以采用方式二的RewriteMethod为ConstantScoreXXX,也即除了用户指定的Query boost,其他的打分计算全部忽略。
方式二使得整个Query对象树被展开,叶子节点都为TermQuery,MultiTermQuery中的多个Term可根据在索引中的tf, idf等参与打分计算,然而我们事先并不知道索引中和MultiTermQuery相对应的Term到底有多少个,因而会出现TooManyClauses异常,也即一个BooleanQuery中的子查询太多。这样会造成要合并的倒排表非常多,从而影响性能。
Lucene认为对于MultiTermQuery这种查询,打分计算忽略是很合理的,因为当用户输入"appl*"的时候,他并不知道索引中有什么与此相关,也并不偏爱其中之一,因而计算这些词之间的差别对用户来讲是没有意义的。从而Lucene对方式二也提供了ConstantScoreXXX,来提高搜索过程的性能,从后面的例子来看,会影响文档打分,在实际的系统应用中,还是存在问题的。
为了兼顾上述两种方式,Lucene提供了ConstantScoreAutoRewrite,来根据不同的情况,选择不同的方式。
| ConstantScoreAutoRewrite.rewrite代码如下: public Query rewrite(IndexReader reader, MultiTermQuery query) throws IOException { final Collection pendingTerms = new ArrayList(); //计算文档数目限制,docCountPercent默认为0.1,也即索引文档总数的0.1% final int docCountCutoff = (int) ((docCountPercent / 100.) * reader.maxDoc()); //计算Term数目限制,默认为350 final int termCountLimit = Math.min(BooleanQuery.getMaxClauseCount(), termCountCutoff); int docVisitCount = 0; FilteredTermEnum enumerator = query.getEnum(reader); try { //一个循环,取出与MultiTermQuery相关的所有的Term。 while(true) { Term t = enumerator.term(); if (t != null) { pendingTerms.add(t); docVisitCount += reader.docFreq(t); } //如果Term数目超限,或者文档数目超限,则可能非常影响倒排表合并的性能,因而选用方式一,也即ConstantScoreFilterRewrite的方式 if (pendingTerms.size() >= termCountLimit || docVisitCount >= docCountCutoff) { Query result = new ConstantScoreQuery(new MultiTermQueryWrapperFilter(query)); result.setBoost(query.getBoost()); return result; } else if (!enumerator.next()) { //如果Term数目不太多,而且文档数目也不太多,不会影响倒排表合并的性能,因而选用方式二,也即ConstantScoreBooleanQueryRewrite的方式。 BooleanQuery bq = new BooleanQuery(true); for (final Term term: pendingTerms) { TermQuery tq = new TermQuery(term); bq.add(tq, BooleanClause.Occur.SHOULD); } Query result = new ConstantScoreQuery(new QueryWrapperFilter(bq)); result.setBoost(query.getBoost()); query.incTotalNumberOfTerms(pendingTerms.size()); return result; } } } finally { enumerator.close(); } } |
MultiTermQuery的getEnum返回的是FilteredTermEnum,它有两个成员变量,其中TermEnum actualEnum是用来枚举索引中所有的Term的,而Term currentTerm指向的是当前满足条件的Term,FilteredTermEnum的next()函数如下:
| public boolean next() throws IOException { if (actualEnum == null) return false; currentTerm = null; //不断得到下一个索引中的Term while (currentTerm == null) { if (endEnum()) return false; if (actualEnum.next()) { Term term = actualEnum.term(); //如果当前索引中的Term满足条件,则赋值为当前的Term if (termCompare(term)) { currentTerm = term; return true; } } else return false; } currentTerm = null; return false; } |
| 不同的MultiTermQuery的termCompare不同: 对于PrefixQuery的getEnum(IndexReader reader)得到的是PrefixTermEnum,其termCompare实现如下: protected boolean termCompare(Term term) { //只要前缀相同,就满足条件 if (term.field() == prefix.field() && term.text().startsWith(prefix.text())){ return true; } endEnum = true; return false; } 对于FuzzyQuery的getEnum得到的是FuzzyTermEnum,其termCompare实现如下: protected final boolean termCompare(Term term) { //对于FuzzyQuery,其prefix设为空"",也即这一条件一定满足,只要计算的是similarity if (field == term.field() && term.text().startsWith(prefix)) { final String target = term.text().substring(prefix.length()); this.similarity = similarity(target); return (similarity > minimumSimilarity); } endEnum = true; return false; } //计算Levenshtein distance 也即 edit distance,对于两个字符串,从一个转换成为另一个所需要的最少基本操作(添加,删除,替换)数。 private synchronized final float similarity(final String target) { final int m = target.length(); final int n = text.length(); // init matrix d for (int i = 0; i<=n; ++i) { p[i] = i; } // start computing edit distance for (int j = 1; j<=m; ++j) { // iterates through target int bestPossibleEditDistance = m; final char t_j = target.charAt(j-1); // jth character of t d[0] = j; for (int i=1; i<=n; ++i) { // iterates through text // minimum of cell to the left+1, to the top+1, diagonally left and up +(0|1) if (t_j != text.charAt(i-1)) { d[i] = Math.min(Math.min(d[i-1], p[i]), p[i-1]) + 1; } else { d[i] = Math.min(Math.min(d[i-1]+1, p[i]+1), p[i-1]); } bestPossibleEditDistance = Math.min(bestPossibleEditDistance, d[i]); } // copy current distance counts to 'previous row' distance counts: swap p and d int _d[] = p; p = d; d = _d; } return 1.0f - ((float)p / (float) (Math.min(n, m))); } |
| 有关edit distance的算法详见http://www.merriampark.com/ld.htm 计算两个字符串s和t的edit distance算法如下: Step 1: Set n to be the length of s. Set m to be the length of t. If n = 0, return m and exit. If m = 0, return n and exit. Construct a matrix containing 0..m rows and 0..n columns. Step 2: Initialize the first row to 0..n. Initialize the first column to 0..m. Step 3: Examine each character of s (i from 1 to n). Step 4: Examine each character of t (j from 1 to m). Step 5: If s[i] equals t[j], the cost is 0. If s[i] doesn't equal t[j], the cost is 1. Step 6: Set cell d[i,j] of the matrix equal to the minimum of: a. The cell immediately above plus 1: d[i-1,j] + 1. b. The cell immediately to the left plus 1: d[i,j-1] + 1. c. The cell diagonally above and to the left plus the cost: d[i-1,j-1] + cost. Step 7: After the iteration steps (3, 4, 5, 6) are complete, the distance is found in cell d[n,m]. 举例说明其过程如下: 比较的两个字符串为:“GUMBO” 和 "GAMBOL".  |
| 在索引中,添加了以下四篇文档: file01.txt : apple other other other other file02.txt : apple apple other other other file03.txt : apple apple apple other other file04.txt : apple apple apple other other 搜索"apple"结果如下: docid : 3 score : 0.67974937 docid : 2 score : 0.58868027 docid : 1 score : 0.4806554 docid : 0 score : 0.33987468 文档按照包含"apple"的多少排序。 而搜索"apple*"结果如下: docid : 0 score : 1.0 docid : 1 score : 1.0 docid : 2 score : 1.0 docid : 3 score : 1.0 也即Lucene放弃了对score的计算。 |
| query BooleanQuery (id=89) | boost 1.0 | clauses ArrayList (id=90) | elementData Object[3] (id=97) |------[0] BooleanClause (id=99) | | occur BooleanClause$Occur$1 (id=103) | | name "MUST" | | ordinal 0 | |---query BooleanQuery (id=105) | | boost 1.0 | | clauses ArrayList (id=115) | | elementData Object[2] (id=120) | | //"apple*"被用方式一重写为ConstantScoreQuery | |---[0] BooleanClause (id=121) | | | occur BooleanClause$Occur$1 (id=103) | | | name "MUST" | | | ordinal 0 | | |---query ConstantScoreQuery (id=123) | | boost 1.0 | | filter MultiTermQueryWrapperFilter (id=125) | | query PrefixQuery (id=48) | | boost 1.0 | | numberOfTerms 0 | | prefix Term (id=127) | | field "contents" | | text "apple" | | rewriteMethod MultiTermQuery$1 (id=50) | |---[1] BooleanClause (id=122) | | occur BooleanClause$Occur$3 (id=111) | | name "MUST_NOT" | | ordinal 2 | |---query TermQuery (id=124) | boost 1.0 | term Term (id=130) | field "contents" | text "boy" | modCount 0 | size 2 | disableCoord false | minNrShouldMatch 0 |------[1] BooleanClause (id=101) | | occur BooleanClause$Occur$2 (id=108) | | name "SHOULD" | | ordinal 1 | |---query BooleanQuery (id=110) | | boost 1.0 | | clauses ArrayList (id=117) | | elementData Object[2] (id=132) | | //"cat*"被用方式一重写为ConstantScoreQuery | |------[0] BooleanClause (id=133) | | | occur BooleanClause$Occur$2 (id=108) | | | name "SHOULD" | | | ordinal 1 | | |---query ConstantScoreQuery (id=135) | | boost 1.0 | | filter MultiTermQueryWrapperFilter (id=137) | | query PrefixQuery (id=63) | | boost 1.0 | | numberOfTerms 0 | | prefix Term (id=138) | | field "contents" | | text "cat" | | rewriteMethod MultiTermQuery$1 (id=50) | |------[1] BooleanClause (id=134) | | occur BooleanClause$Occur$2 (id=108) | | name "SHOULD" | | ordinal 1 | |---query TermQuery (id=136) | boost 1.0 | term Term (id=140) | field "contents" | text "dog" | modCount 0 | size 2 | disableCoord false | minNrShouldMatch 0 |------[2] BooleanClause (id=102) | occur BooleanClause$Occur$3 (id=111) | name "MUST_NOT" | ordinal 2 |---query BooleanQuery (id=113) | boost 1.0 | clauses ArrayList (id=119) | elementData Object[2] (id=142) |------[0] BooleanClause (id=143) | | occur BooleanClause$Occur$2 (id=108) | | name "SHOULD" | | ordinal 1 | | //"eat~"作为FuzzyQuery,被重写成BooleanQuery, | | 索引中满足 条件的Term有"eat"和"cat"。FuzzyQuery | | 不用上述的任何一种RewriteMethod,而是用方式二自己 | | 实现了rewrite函数,是将同"eat"的edit distance最近的 | | 最多maxClauseCount(默认1024)个Term组成BooleanQuery。 | |---query BooleanQuery (id=145) | | boost 1.0 | | clauses ArrayList (id=146) | | elementData Object[10] (id=147) | |------[0] BooleanClause (id=148) | | | occur BooleanClause$Occur$2 (id=108) | | | name "SHOULD" | | | ordinal 1 | | |---query TermQuery (id=150) | | boost 1.0 | | term Term (id=152) | | field "contents" | | text "eat" | |------[1] BooleanClause (id=149) | | occur BooleanClause$Occur$2 (id=108) | | name "SHOULD" | | ordinal 1 | |---query TermQuery (id=151) | boost 0.33333325 | term Term (id=153) | field "contents" | text "cat" | modCount 2 | size 2 | disableCoord true | minNrShouldMatch 0 |------[1] BooleanClause (id=144) | occur BooleanClause$Occur$2 (id=108) | name "SHOULD" | ordinal 1 |---query TermQuery (id=154) boost 1.0 term Term (id=155) field "contents" text "foods" modCount 0 size 2 disableCoord false minNrShouldMatch 0 modCount 0 size 3 disableCoord false minNrShouldMatch 0 |

2.4、搜索查询对象
[b]2.4.1.2、创建Weight对象树[/b]BooleanQuery.createWeight(Searcher) 最终返回return new BooleanWeight(searcher),BooleanWeight构造函数的具体实现如下:
| public BooleanWeight(Searcher searcher) { this.similarity = getSimilarity(searcher); weights = new ArrayList(clauses.size()); //也是一个递归的过程,沿着新的Query对象树一直到叶子节点 for (int i = 0 ; i < clauses.size(); i++) { weights.add(clauses.get(i).getQuery().createWeight(searcher)); } } |
| public TermWeight(Searcher searcher) { this.similarity = getSimilarity(searcher); //此处计算了idf idfExp = similarity.idfExplain(term, searcher); idf = idfExp.getIdf(); } |
//idf的计算完全符合文档中的公式: public IDFExplanation idfExplain(final Term term, final Searcher searcher) { final int df = searcher.docFreq(term); final int max = searcher.maxDoc(); final float idf = idf(df, max); return new IDFExplanation() { public float getIdf() { return idf; }}; } |
| public float idf(int docFreq, int numDocs) { return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0); } |
由此创建的Weight对象树如下:
| weight BooleanQuery$BooleanWeight (id=169) | similarity DefaultSimilarity (id=177) | this$0 BooleanQuery (id=89) | weights ArrayList (id=188) | elementData Object[3] (id=190) |------[0] BooleanQuery$BooleanWeight (id=171) | | similarity DefaultSimilarity (id=177) | | this$0 BooleanQuery (id=105) | | weights ArrayList (id=193) | | elementData Object[2] (id=199) | |------[0] ConstantScoreQuery$ConstantWeight (id=183) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //ConstantScore(contents:apple*) | | this$0 ConstantScoreQuery (id=123) | |------[1] TermQuery$TermWeight (id=175) | idf 2.0986123 | idfExp Similarity$1 (id=241) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:boy | this$0 TermQuery (id=124) | value 0.0 | modCount 2 | size 2 |------[1] BooleanQuery$BooleanWeight (id=179) | | similarity DefaultSimilarity (id=177) | | this$0 BooleanQuery (id=110) | | weights ArrayList (id=195) | | elementData Object[2] (id=204) | |------[0] ConstantScoreQuery$ConstantWeight (id=206) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //ConstantScore(contents:cat*) | | this$0 ConstantScoreQuery (id=135) | |------[1] TermQuery$TermWeight (id=207) | idf 1.5389965 | idfExp Similarity$1 (id=210) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:dog | this$0 TermQuery (id=136) | value 0.0 | modCount 2 | size 2 |------[2] BooleanQuery$BooleanWeight (id=182) | similarity DefaultSimilarity (id=177) | this$0 BooleanQuery (id=113) | weights ArrayList (id=197) | elementData Object[2] (id=216) |------[0] BooleanQuery$BooleanWeight (id=181) | | similarity BooleanQuery$1 (id=220) | | this$0 BooleanQuery (id=145) | | weights ArrayList (id=221) | | elementData Object[2] (id=224) | |------[0] TermQuery$TermWeight (id=226) | | idf 2.0986123 | | idfExp Similarity$1 (id=229) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //contents:eat | | this$0 TermQuery (id=150) | | value 0.0 | |------[1] TermQuery$TermWeight (id=227) | idf 1.1823215 | idfExp Similarity$1 (id=231) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:cat^0.33333325 | this$0 TermQuery (id=151) | value 0.0 | modCount 2 | size 2 |------[1] TermQuery$TermWeight (id=218) idf 2.0986123 idfExp Similarity$1 (id=233) queryNorm 0.0 queryWeight 0.0 similarity DefaultSimilarity (id=177) //contents:foods this$0 TermQuery (id=154) value 0.0 modCount 2 size 2 modCount 3 size 3 |
[b]2.4.1.3、计算Term Weight分数[/b]
(1) 首先计算sumOfSquaredWeights
按照公式:
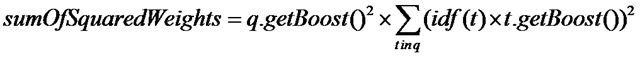
代码如下:
float sum = weight.sumOfSquaredWeights();
| //可以看出,也是一个递归的过程 public float sumOfSquaredWeights() throws IOException { float sum = 0.0f; for (int i = 0 ; i < weights.size(); i++) { float s = weights.get(i).sumOfSquaredWeights(); if (!clauses.get(i).isProhibited()) sum += s; } sum *= getBoost() * getBoost(); //乘以query boost return sum ; } |
| public float sumOfSquaredWeights() { //计算一部分打分,idf*t.getBoost(),将来还会用到。 queryWeight = idf * getBoost(); //计算(idf*t.getBoost())^2 return queryWeight * queryWeight; } |
| public float sumOfSquaredWeights() { //除了用户指定的boost以外,其他都不计算在打分内 queryWeight = getBoost(); return queryWeight * queryWeight; } |
其公式如下:

其代码如下:
| public float queryNorm(float sumOfSquaredWeights) { return (float)(1.0 / Math.sqrt(sumOfSquaredWeights)); } |
代码为:
weight.normalize(norm);
| //又是一个递归的过程 public void normalize(float norm) { norm *= getBoost(); for (Weight w : weights) { w.normalize(norm); } } |
| public void normalize(float queryNorm) { this.queryNorm = queryNorm; //原来queryWeight为idf*t.getBoost(),现在为queryNorm*idf*t.getBoost()。 queryWeight *= queryNorm; //打分到此计算了queryNorm*idf*t.getBoost()*idf = queryNorm*idf^2*t.getBoost()部分。 value = queryWeight * idf; } |
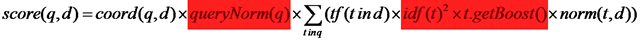
2.4.2、创建Scorer及SumScorer对象树
当创建完Weight对象树的时候,调用IndexSearcher.search(Weight, Filter, int),代码如下:| //(a)创建文档号收集器 TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder()); search(weight, filter, collector); //(b)返回搜索结果 return collector.topDocs(); |
| public void search(Weight weight, Filter filter, Collector collector) throws IOException { if (filter == null) { for (int i = 0; i < subReaders.length; i++) { collector.setNextReader(subReaders[i], docStarts[i]); //(c)创建Scorer对象树,以及SumScorer树用来合并倒排表 Scorer scorer = weight.scorer(subReaders[i], !collector.acceptsDocsOutOfOrder(), true); if (scorer != null) { //(d)合并倒排表,(e)收集文档号 scorer.score(collector); } } } else { for (int i = 0; i < subReaders.length; i++) { collector.setNextReader(subReaders[i], docStarts[i]); searchWithFilter(subReaders[i], weight, filter, collector); } } } |
BooleanQuery$BooleanWeight.scorer(IndexReader, boolean, boolean) 代码如下:
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer){ //存放对应于MUST语句的Scorer List required = new ArrayList(); //存放对应于MUST_NOT语句的Scorer List prohibited = new ArrayList(); //存放对应于SHOULD语句的Scorer List optional = new ArrayList(); //遍历每一个子语句,生成子Scorer对象,并加入相应的集合,这是一个递归的过程。 Iterator cIter = clauses.iterator(); for (Weight w : weights) { BooleanClause c = cIter.next(); Scorer subScorer = w.scorer(reader, true, false); if (subScorer == null) { if (c.isRequired()) { return null; } } else if (c.isRequired()) { required.add(subScorer); } else if (c.isProhibited()) { prohibited.add(subScorer); } else { optional.add(subScorer); } } //此处在有关BooleanScorer及scoreDocsInOrder一节会详细描述 if (!scoreDocsInOrder && topScorer && required.size() == 0 && prohibited.size() < 32) { return new BooleanScorer(similarity, minNrShouldMatch, optional, prohibited); } //生成Scorer对象树,同时生成SumScorer对象树 return new BooleanScorer2(similarity, minNrShouldMatch, required, prohibited, optional); } |
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer) throws IOException { //此Term的倒排表 TermDocs termDocs = reader.termDocs(term); if (termDocs == null) return null; return new TermScorer(this, termDocs, similarity, reader.norms(term.field())); } |
| TermScorer(Weight weight, TermDocs td, Similarity similarity, byte[] norms) { super(similarity); this.weight = weight; this.termDocs = td; //得到标准化因子 this.norms = norms; //得到原来计算得的打分:queryNorm*idf^2*t.getBoost() this.weightValue = weight.getValue(); for (int i = 0; i < SCORE_CACHE_SIZE; i++) scoreCache[i] = getSimilarity().tf(i) * weightValue; } |
| public ConstantScorer(Similarity similarity, IndexReader reader, Weight w) { super(similarity); theScore = w.getValue(); //得到所有的文档号,形成统一的倒排表,参与倒排表合并。 DocIdSet docIdSet = filter.getDocIdSet(reader); DocIdSetIterator docIdSetIterator = docIdSet.iterator(); } |
| public BooleanScorer2(Similarity similarity, int minNrShouldMatch, List required, List prohibited, List optional) { super(similarity); //为了计算打分公式中的coord项做统计 coordinator = new Coordinator(); this.minNrShouldMatch = minNrShouldMatch; //SHOULD的部分 optionalScorers = optional; coordinator.maxCoord += optional.size(); //MUST的部分 requiredScorers = required; coordinator.maxCoord += required.size(); //MUST_NOT的部分 prohibitedScorers = prohibited; //事先计算好各种情况的coord值 coordinator.init(); //创建SumScorer为倒排表合并做准备 countingSumScorer = makeCountingSumScorer(); } |
| Coordinator.init() { coordFactors = new float[maxCoord + 1]; Similarity sim = getSimilarity(); for (int i = 0; i <= maxCoord; i++) { //计算总的子语句的个数和一个文档满足的子语句的个数之间的关系,自然是一篇文档满足的子语句个个数越多,打分越高。 coordFactors[i] = sim.coord(i, maxCoord); } } |
在解析BooleanScorer2.makeCountingSumScorer() 之前,我们先来看不同的语句之间都存在什么样的关系,又将如何影响倒排表合并呢?
语句主要分三类:MUST,SHOULD,MUST_NOT
语句之间的组合主要有以下几种情况:
多个MUST,如"(+apple +boy +dog)",则会生成ConjunctionScorer(Conjunction 交集),也即倒排表取交集
MUST和SHOULD,如"(+apple boy)",则会生成ReqOptSumScorer(required optional),也即MUST的倒排表返回,如果文档包括SHOULD的部分,则增加打分。
MUST和MUST_NOT,如"(+apple –boy)",则会生成ReqExclScorer(required exclusive),也即返回MUST的倒排表,但扣除MUST_NOT的倒排表中的文档。
多个SHOULD,如"(apple boy dog)",则会生成DisjunctionSumScorer(Disjunction 并集),也即倒排表去并集
SHOULD和MUST_NOT,如"(apple –boy)",则SHOULD被认为成MUST,会生成ReqExclScorer
MUST,SHOULD,MUST_NOT同时出现,则MUST首先和MUST_NOT组合成ReqExclScorer,SHOULD单独成为SingleMatchScorer,然后两者组合成ReqOptSumScorer。
下面分析生成SumScorer的过程:
BooleanScorer2.makeCountingSumScorer() 分两种情况:
当有MUST的语句的时候,则调用makeCountingSumScorerSomeReq()
当没有MUST的语句的时候,则调用makeCountingSumScorerNoReq()
首先来看makeCountingSumScorerSomeReq代码如下:
| private Scorer makeCountingSumScorerSomeReq() { if (optionalScorers.size() == minNrShouldMatch) { //如果optional的语句个数恰好等于最少需满足的optional的个数,则所有的optional都变成required。于是首先所有的optional生成ConjunctionScorer(交集),然后再通过addProhibitedScorers将prohibited加入,生成ReqExclScorer(required exclusive) ArrayList allReq = new ArrayList(requiredScorers); allReq.addAll(optionalScorers); return addProhibitedScorers(countingConjunctionSumScorer(allReq)); } else { //首先所有的required的语句生成ConjunctionScorer(交集) Scorer requiredCountingSumScorer = requiredScorers.size() == 1 ? new SingleMatchScorer(requiredScorers.get(0)) : countingConjunctionSumScorer(requiredScorers); if (minNrShouldMatch > 0) { //如果最少需满足的optional的个数有一定的限制,则意味着optional中有一部分要相当于required,会影响倒排表的合并。因而required生成的ConjunctionScorer(交集)和optional生成的DisjunctionSumScorer(并集)共同组合成一个ConjunctionScorer(交集),然后再加入prohibited,生成ReqExclScorer return addProhibitedScorers( dualConjunctionSumScorer( requiredCountingSumScorer, countingDisjunctionSumScorer( optionalScorers, minNrShouldMatch))); } else { // minNrShouldMatch == 0 //如果最少需满足的optional的个数没有一定的限制,则optional并不影响倒排表的合并,仅仅在文档包含optional部分的时候增加打分。所以required和prohibited首先生成ReqExclScorer,然后再加入optional,生成ReqOptSumScorer(required optional) return new ReqOptSumScorer( addProhibitedScorers(requiredCountingSumScorer), optionalScorers.size() == 1 ? new SingleMatchScorer(optionalScorers.get(0)) : countingDisjunctionSumScorer(optionalScorers, 1)); } } } |
| private Scorer makeCountingSumScorerNoReq() { // minNrShouldMatch optional scorers are required, but at least 1 int nrOptRequired = (minNrShouldMatch < 1) ? 1 : minNrShouldMatch; Scorer requiredCountingSumScorer; if (optionalScorers.size() > nrOptRequired) //如果optional的语句个数多于最少需满足的optional的个数,则optional中一部分相当required,影响倒排表的合并,所以生成DisjunctionSumScorer requiredCountingSumScorer = countingDisjunctionSumScorer(optionalScorers, nrOptRequired); else if (optionalScorers.size() == 1) //如果optional的语句只有一个,则返回SingleMatchScorer,不存在倒排表合并的问题。 requiredCountingSumScorer = new SingleMatchScorer(optionalScorers.get(0)); else //如果optional的语句个数少于等于最少需满足的optional的个数,则所有的optional都算required,所以生成ConjunctionScorer requiredCountingSumScorer = countingConjunctionSumScorer(optionalScorers); //将prohibited加入,生成ReqExclScorer return addProhibitedScorers(requiredCountingSumScorer); } |
| scorer BooleanScorer2 (id=50) | coordinator BooleanScorer2$Coordinator (id=53) | countingSumScorer ReqOptSumScorer (id=54) | minNrShouldMatch 0 |---optionalScorers ArrayList (id=55) | | elementData Object[10] (id=69) | |---[0] BooleanScorer2 (id=73) | | coordinator BooleanScorer2$Coordinator (id=74) | | countingSumScorer BooleanScorer2$1 (id=75) | | minNrShouldMatch 0 | |---optionalScorers ArrayList (id=76) | | | elementData Object[10] (id=83) | | |---[0] ConstantScoreQuery$ConstantScorer (id=86) | | | docIdSetIterator OpenBitSetIterator (id=88) | | | similarity DefaultSimilarity (id=64) | | | theScore 0.47844642 | | | //ConstantScore(contents:cat*) | | | this$0 ConstantScoreQuery (id=90) | | |---[1] TermScorer (id=87) | | doc -1 | | doc 0 | | docs int[32] (id=93) | | freqs int[32] (id=95) | | norms byte[4] (id=96) | | pointer 0 | | pointerMax 2 | | scoreCache float[32] (id=98) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=103) | | //weight(contents:dog) | | weight TermQuery$TermWeight (id=106) | | weightValue 1.1332052 | | modCount 2 | | size 2 | |---prohibitedScorers ArrayList (id=77) | | elementData Object[10] (id=84) | | size 0 | |---requiredScorers ArrayList (id=78) | elementData Object[10] (id=85) | size 0 | similarity DefaultSimilarity (id=64) | size 1 |---prohibitedScorers ArrayList (id=60) | | elementData Object[10] (id=71) | |---[0] BooleanScorer2 (id=81) | | coordinator BooleanScorer2$Coordinator (id=114) | | countingSumScorer BooleanScorer2$1 (id=115) | | minNrShouldMatch 0 | |---optionalScorers ArrayList (id=116) | | | elementData Object[10] (id=119) | | |---[0] BooleanScorer2 (id=122) | | | | coordinator BooleanScorer2$Coordinator (id=124) | | | | countingSumScorer BooleanScorer2$1 (id=125) | | | | minNrShouldMatch 0 | | | |---optionalScorers ArrayList (id=126) | | | | | elementData Object[10] (id=138) | | | | |---[0] TermScorer (id=156) | | | | | docs int[32] (id=162) | | | | | freqs int[32] (id=163) | | | | | norms byte[4] (id=96) | | | | | pointer 0 | | | | | pointerMax 1 | | | | | scoreCache float[32] (id=164) | | | | | similarity DefaultSimilarity (id=64) | | | | | termDocs SegmentTermDocs (id=165) | | | | | //weight(contents:eat) | | | | | weight TermQuery$TermWeight (id=166) | | | | | weightValue 2.107161 | | | | |---[1] TermScorer (id=157) | | | | doc -1 | | | | doc 1 | | | | docs int[32] (id=171) | | | | freqs int[32] (id=172) | | | | norms byte[4] (id=96) | | | | pointer 1 | | | | pointerMax 3 | | | | scoreCache float[32] (id=173) | | | | similarity DefaultSimilarity (id=64) | | | | termDocs SegmentTermDocs (id=180) | | | | //weight(contents:cat^0.33333325) | | | | weight TermQuery$TermWeight (id=181) | | | | weightValue 0.22293752 | | | | size 2 | | | |---prohibitedScorers ArrayList (id=127) | | | | elementData Object[10] (id=140) | | | | modCount 0 | | | | size 0 | | | |---requiredScorers ArrayList (id=128) | | | elementData Object[10] (id=142) | | | modCount 0 | | | size 0 | | | similarity BooleanQuery$1 (id=129) | | |---[1] TermScorer (id=123) | | doc -1 | | doc 3 | | docs int[32] (id=131) | | freqs int[32] (id=132) | | norms byte[4] (id=96) | | pointer 0 | | pointerMax 1 | | scoreCache float[32] (id=133) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=134) | | //weight(contents:foods) | | weight TermQuery$TermWeight (id=135) | | weightValue 2.107161 | | size 2 | |---prohibitedScorers ArrayList (id=117) | | elementData Object[10] (id=120) | | size 0 | |---requiredScorers ArrayList (id=118) | elementData Object[10] (id=121) | size 0 | similarity DefaultSimilarity (id=64) | size 1 |---requiredScorers ArrayList (id=63) | elementData Object[10] (id=72) |---[0] BooleanScorer2 (id=82) | coordinator BooleanScorer2$Coordinator (id=183) | countingSumScorer ReqExclScorer (id=184) | minNrShouldMatch 0 |---optionalScorers ArrayList (id=185) | elementData Object[10] (id=189) | size 0 |---prohibitedScorers ArrayList (id=186) | | elementData Object[10] (id=191) | |---[0] TermScorer (id=195) | docs int[32] (id=197) | freqs int[32] (id=198) | norms byte[4] (id=96) | pointer 0 | pointerMax 0 | scoreCache float[32] (id=199) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=200) | //weight(contents:boy) | weight TermQuery$TermWeight (id=201) | weightValue 2.107161 | size 1 |---requiredScorers ArrayList (id=187) | elementData Object[10] (id=193) |---[0] ConstantScoreQuery$ConstantScorer (id=203) docIdSetIterator OpenBitSetIterator (id=206) similarity DefaultSimilarity (id=64) theScore 0.47844642 //ConstantScore(contents:apple*) this$0 ConstantScoreQuery (id=207) size 1 similarity DefaultSimilarity (id=64) size 1 similarity DefaultSimilarity (id=64) |

生成的SumScorer对象树如下:
| scorer BooleanScorer2 (id=50) | coordinator BooleanScorer2$Coordinator (id=53) |---countingSumScorer ReqOptSumScorer (id=54) |---optScorer BooleanScorer2$SingleMatchScorer (id=79) | | lastDocScore NaN | | lastScoredDoc -1 | |---scorer BooleanScorer2 (id=73) | | coordinator BooleanScorer2$Coordinator (id=74) | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=75) | | currentDoc -1 | | currentScore NaN | | doc -1 | | lastDocScore NaN | | lastScoredDoc -1 | | minimumNrMatchers 1 | | nrMatchers -1 | | nrScorers 2 | | scorerDocQueue ScorerDocQueue (id=243) | | similarity null | |---subScorers ArrayList (id=76) | | elementData Object[10] (id=83) | |---[0] ConstantScoreQuery$ConstantScorer (id=86) | | doc -1 | | doc -1 | | docIdSetIterator OpenBitSetIterator (id=88) | | similarity DefaultSimilarity (id=64) | | theScore 0.47844642 | | //ConstantScore(contents:cat*) | | this$0 ConstantScoreQuery (id=90) | |---[1] TermScorer (id=87) | doc -1 | doc 0 | docs int[32] (id=93) | freqs int[32] (id=95) | norms byte[4] (id=96) | pointer 0 | pointerMax 2 | scoreCache float[32] (id=98) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=103) | //weight(contents:dog) | weight TermQuery$TermWeight (id=106) | weightValue 1.1332052 | size 2 | this$0 BooleanScorer2 (id=73) | minNrShouldMatch 0 | optionalScorers ArrayList (id=76) | prohibitedScorers ArrayList (id=77) | requiredScorers ArrayList (id=78) | similarity DefaultSimilarity (id=64) | similarity DefaultSimilarity (id=64) | this$0 BooleanScorer2 (id=50) |---reqScorer ReqExclScorer (id=80) |---exclDisi BooleanScorer2 (id=81) | | coordinator BooleanScorer2$Coordinator (id=114) | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=115) | | currentDoc -1 | | currentScore NaN | | doc -1 | | lastDocScore NaN | | lastScoredDoc -1 | | minimumNrMatchers 1 | | nrMatchers -1 | | nrScorers 2 | | scorerDocQueue ScorerDocQueue (id=260) | | similarity null | |---subScorers ArrayList (id=116) | | elementData Object[10] (id=119) | |---[0] BooleanScorer2 (id=122) | | | coordinator BooleanScorer2$Coordinator (id=124) | | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=125) | | | currentDoc 0 | | | currentScore 0.11146876 | | | doc -1 | | | lastDocScore NaN | | | lastScoredDoc -1 | | | minimumNrMatchers 1 | | | nrMatchers 1 | | | nrScorers 2 | | | scorerDocQueue ScorerDocQueue (id=270) | | | similarity null | | |---subScorers ArrayList (id=126) | | | elementData Object[10] (id=138) | | |---[0] TermScorer (id=156) | | | doc -1 | | | doc 2 | | | docs int[32] (id=162) | | | freqs int[32] (id=163) | | | norms byte[4] (id=96) | | | pointer 0 | | | pointerMax 1 | | | scoreCache float[32] (id=164) | | | similarity DefaultSimilarity (id=64) | | | termDocs SegmentTermDocs (id=165) | | | //weight(contents:eat) | | | weight TermQuery$TermWeight (id=166) | | | weightValue 2.107161 | | |---[1] TermScorer (id=157) | | doc -1 | | doc 1 | | docs int[32] (id=171) | | freqs int[32] (id=172) | | norms byte[4] (id=96) | | pointer 1 | | pointerMax 3 | | scoreCache float[32] (id=173) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=180) | | //weight(contents:cat^0.33333325) | | weight TermQuery$TermWeight (id=181) | | weightValue 0.22293752 | | size 2 | | this$0 BooleanScorer2 (id=122) | | doc -1 | | doc 0 | | minNrShouldMatch 0 | | optionalScorers ArrayList (id=126) | | prohibitedScorers ArrayList (id=127) | | requiredScorers ArrayList (id=128) | | similarity BooleanQuery$1 (id=129) | |---[1] TermScorer (id=123) | doc -1 | doc 3 | docs int[32] (id=131) | freqs int[32] (id=132) | norms byte[4] (id=96) | pointer 0 | pointerMax 1 | scoreCache float[32] (id=133) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=134) | //weight(contents:foods) | weight TermQuery$TermWeight (id=135) | weightValue 2.107161 | size 2 | this$0 BooleanScorer2 (id=81) | doc -1 | doc -1 | minNrShouldMatch 0 | optionalScorers ArrayList (id=116) | prohibitedScorers ArrayList (id=117) | requiredScorers ArrayList (id=118) | similarity DefaultSimilarity (id=64) |---reqScorer BooleanScorer2$SingleMatchScorer (id=237) | doc -1 | lastDocScore NaN | lastScoredDoc -1 |---scorer BooleanScorer2 (id=82) | coordinator BooleanScorer2$Coordinator (id=183) |---countingSumScorer ReqExclScorer (id=184) |---exclDisi TermScorer (id=195) | doc -1 | doc -1 | docs int[32] (id=197) | freqs int[32] (id=198) | norms byte[4] (id=96) | pointer 0 | pointerMax 0 | scoreCache float[32] (id=199) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=200) | //weight(contents:boy) | weight TermQuery$TermWeight (id=201) | weightValue 2.107161 |---reqScorer BooleanScorer2$2(ConjunctionScorer) (id=281) | coord 1.0 | doc -1 | lastDoc -1 | lastDocScore NaN | lastScoredDoc -1 |---scorers Scorer[1] (id=283) |---[0] ConstantScoreQuery$ConstantScorer (id=203) doc -1 doc -1 docIdSetIterator OpenBitSetIterator (id=206) similarity DefaultSimilarity (id=64) theScore 0.47844642 //ConstantScore(contents:apple*) this$0 ConstantScoreQuery (id=207) similarity DefaultSimilarity (id=64) this$0 BooleanScorer2 (id=82) val$requiredNrMatchers 1 similarity null minNrShouldMatch 0 optionalScorers ArrayList (id=185) prohibitedScorers ArrayList (id=186) requiredScorers ArrayList (id=187) similarity DefaultSimilarity (id=64) similarity DefaultSimilarity (id=64) this$0 BooleanScorer2 (id=50) similarity null similarity null minNrShouldMatch 0 optionalScorers ArrayList (id=55) prohibitedScorers ArrayList (id=60) requiredScorers ArrayList (id=63) similarity DefaultSimilarity (id=64) |
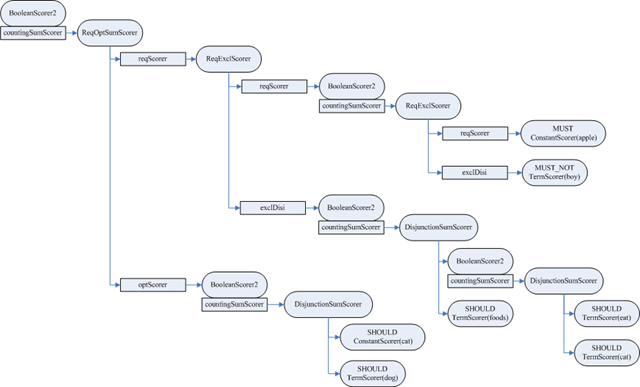
2.4、搜索查询对象
2.4.3、进行倒排表合并
在得到了Scorer对象树以及SumScorer对象树后,便是倒排表的合并以及打分计算的过程。合并倒排表在此节中进行分析,而Scorer对象树来进行打分的计算则在下一节分析。
BooleanScorer2.score(Collector) 代码如下:
| public void score(Collector collector) throws IOException { collector.setScorer(this); while ((doc = countingSumScorer.nextDoc()) != NO_MORE_DOCS) { collector.collect(doc); } } |
取下一篇文档的过程,就是合并倒排表的过程,也就是对多个查询条件进行综合考虑后的下一篇文档的编号。
由于SumScorer是一棵树,因而合并倒排表也是按照树的结构进行的,先合并子树,然后子树与子树再进行合并,直到根。
按照上一节的分析,倒排表的合并主要用了以下几个SumScorer:
交集ConjunctionScorer
并集DisjunctionSumScorer
差集ReqExclScorer
ReqOptSumScorer
下面我们一一分析:
[b]2.4.3.1、交集ConjunctionScorer(+A +B)[/b]
ConjunctionScorer中有成员变量Scorer[] scorers,是一个Scorer的数组,每一项代表一个倒排表,ConjunctionScorer就是对这些倒排表取交集,然后将交集中的文档号在nextDoc()函数中依次返回。
为了描述清楚此过程,下面举一个具体的例子来解释倒排表合并的过程:
(1) 倒排表最初如下:
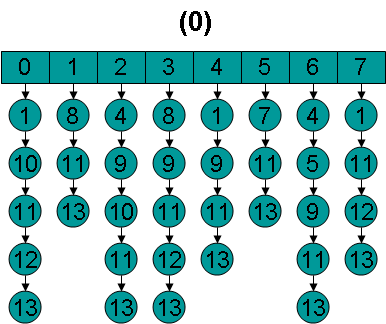
(2) 在ConjunctionScorer的构造函数中,首先调用每个Scorer的nextDoc()函数,使得每个Scorer得到自己的第一篇文档号。
| for (int i = 0; i < scorers.length; i++) { if (scorers[i].nextDoc() == NO_MORE_DOCS) { //由于是取交集,因而任何一个倒排表没有文档,交集就为空。 lastDoc = NO_MORE_DOCS; return; } } |
| Arrays.sort(scorers, new Comparator() { public int compare(Scorer o1, Scorer o2) { return o1.docID() - o2.docID(); } }); |
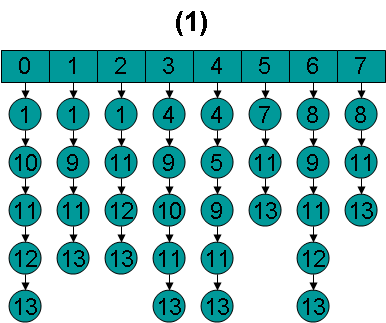
(4) 在ConjunctionScorer的构造函数中,第一次调用doNext()函数。
| if (doNext() == NO_MORE_DOCS) { lastDoc = NO_MORE_DOCS; return; } |
| private int doNext() throws IOException { int first = 0; int doc = scorers[scorers.length - 1].docID(); Scorer firstScorer; while ((firstScorer = scorers[first]).docID() < doc) { doc = firstScorer.advance(doc); first = first == scorers.length - 1 ? 0 : first + 1; } return doc; } |
而此时scorer[scorers.length - 1]拥有最大的文档号,doNext()中的循环,将所有的小于当前数组中最大文档号的文档全部用firstScorer.advance(doc)(其跳到大于或等于doc的文档)函数跳过,因为既然它们小于最大的文档号,而ConjunctionScorer又是取交集,它们当然不会在交集中。
此过程如下:
doc = 8,first指向第0项,advance到大于8的第一篇文档,也即文档10,然后设doc = 10,first指向第1项。

doc = 10,first指向第1项,advance到文档11,然后设doc = 11,first指向第2项。
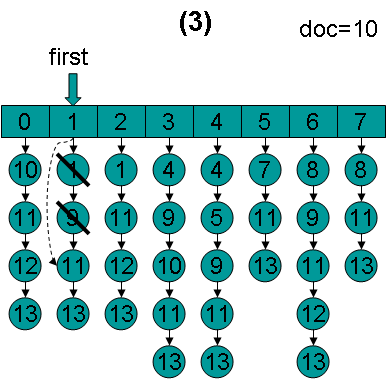
doc = 11,first指向第2项,advance到文档11,然后设doc = 11,first指向第3项。
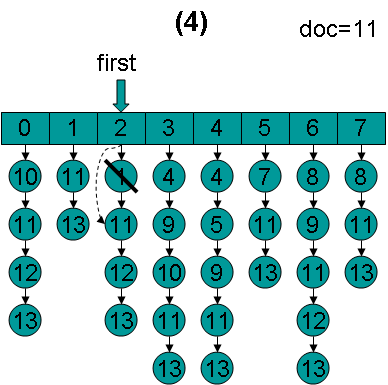
doc = 11,first指向第3项,advance到文档11,然后设doc = 11,first指向第4项。
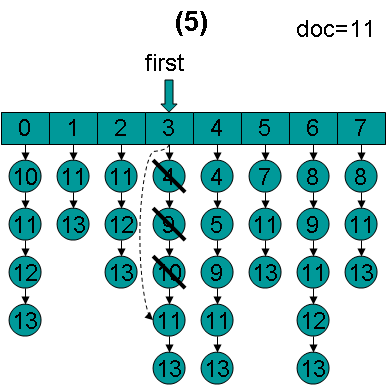
doc = 11,first指向第4项,advance到文档11,然后设doc = 11,first指向第5项。
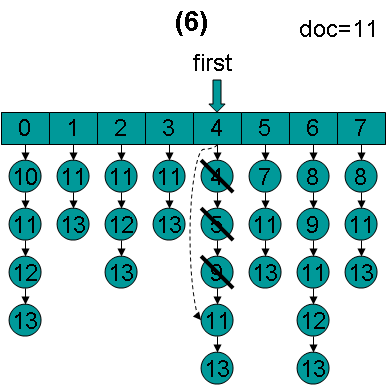
doc = 11,first指向第5项,advance到文档11,然后设doc = 11,first指向第6项。
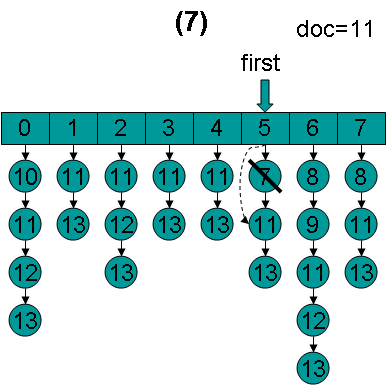
doc = 11,first指向第6项,advance到文档11,然后设doc = 11,first指向第7项。
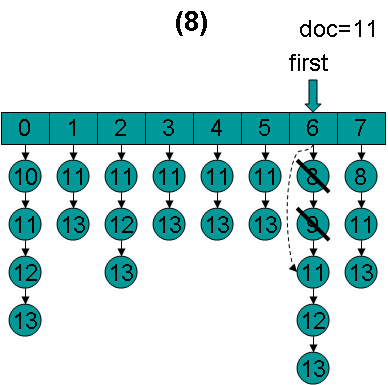
doc = 11,first指向第7项,advance到文档11,然后设doc = 11,first指向第0项。
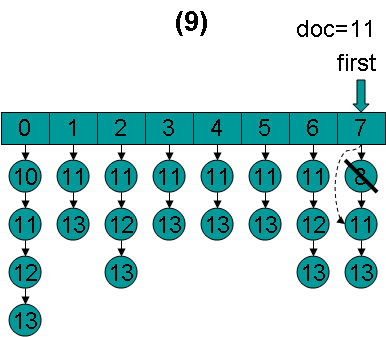
doc = 11,first指向第0项,advance到文档11,然后设doc = 11,first指向第1项。
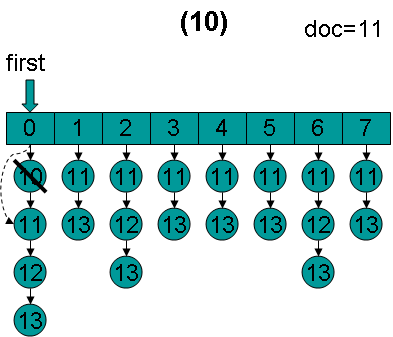
doc = 11,first指向第1项。因为11 < 11为false,因而结束循环,返回doc = 11。这时候我们会发现,在循环退出的时候,所有的倒排表的第一篇文档都是11。

(5) 当BooleanScorer2.score(Collector)中第一次调用ConjunctionScorer.nextDoc()的时候,lastDoc为-1,根据nextDoc函数的实现,返回lastDoc = scorers[scorers.length - 1].docID()也即返回11,lastDoc也设为11。
| public int nextDoc() throws IOException { if (lastDoc == NO_MORE_DOCS) { return lastDoc; } else if (lastDoc == -1) { return lastDoc = scorers[scorers.length - 1].docID(); } scorers[(scorers.length - 1)].nextDoc(); return lastDoc = doNext(); } |
(7) 当BooleanScorer2.score(Collector)第二次调用ConjunctionScorer.nextDoc()时:
根据nextDoc函数的实现,首先调用scorers[(scorers.length - 1)].nextDoc(),取最后一项的下一篇文档13。
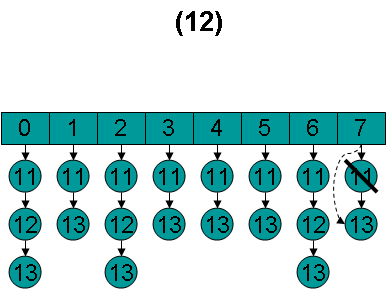
然后调用lastDoc = doNext(),设doc = 13,first = 0,进入循环。
doc = 13,first指向第0项,advance到文档13,然后设doc = 13,first指向第1项。
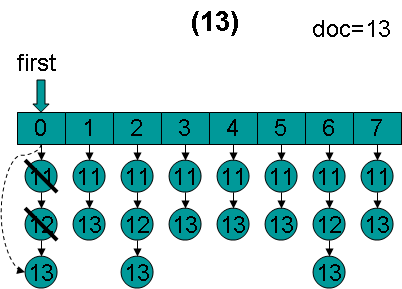
doc = 13,first指向第1项,advance到文档13,然后设doc = 13,first指向第2项。
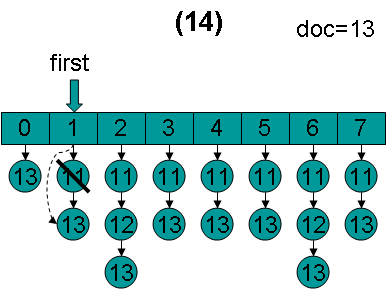
doc = 13,first指向第2项,advance到文档13,然后设doc = 13,first指向第3项。
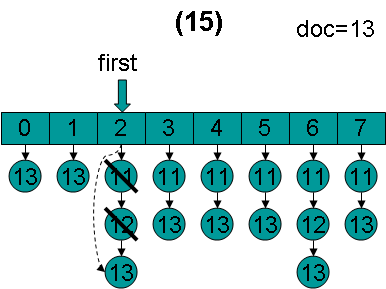
doc = 13,first指向第3项,advance到文档13,然后设doc = 13,first指向第4项。
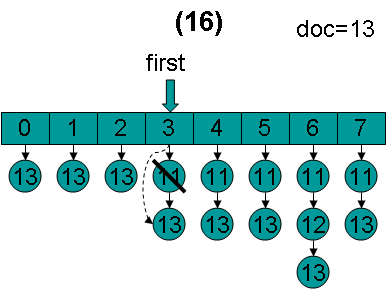
doc = 13,first指向第4项,advance到文档13,然后设doc = 13,first指向第5项。

doc = 13,first指向第5项,advance到文档13,然后设doc = 13,first指向第6项。
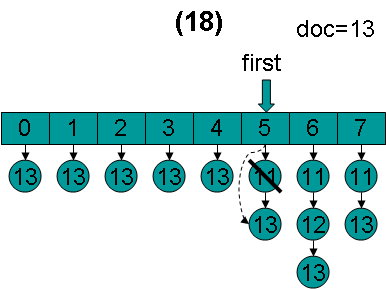
doc = 13,first指向第6项,advance到文档13,然后设doc = 13,first指向第7项。

doc = 13,first指向第7项,advance到文档13,然后设doc = 13,first指向第0项。
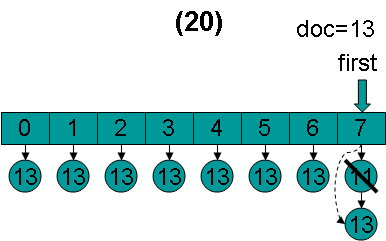
doc = 13,first指向第0项。因为13 < 13为false,因而结束循环,返回doc = 13。在循环退出的时候,所有的倒排表的第一篇文档都是13。

(8) lastDoc设为13,在收集文档的过程中,ConjunctionScorer.docID()会被调用,返回lastDoc,也即当前的文档号为13。
(9) 当再次调用nextDoc()的时候,返回NO_MORE_DOCS,倒排表合并结束。
[b]2.4.3.2、并集DisjunctionSumScorer(A OR B)[/b]
DisjunctionSumScorer中有成员变量List subScorers,是一个Scorer的链表,每一项代表一个倒排表,DisjunctionSumScorer就是对这些倒排表取并集,然后将并集中的文档号在nextDoc()函数中依次返回。
DisjunctionSumScorer还有一个成员变量minimumNrMatchers,表示最少需满足的子条件的个数,也即subScorer中,必须有至少minimumNrMatchers个Scorer都包含某个文档号,此文档号才能够返回。
为了描述清楚此过程,下面举一个具体的例子来解释倒排表合并的过程:
(1) 假设minimumNrMatchers = 4,倒排表最初如下:

(2) 在DisjunctionSumScorer的构造函数中,将倒排表放入一个优先级队列scorerDocQueue中(scorerDocQueue的实现是一个最小堆),队列中的Scorer按照第一篇文档的大小排序。
| private void initScorerDocQueue() throws IOException { scorerDocQueue = new ScorerDocQueue(nrScorers); for (Scorer se : subScorers) { if (se.nextDoc() != NO_MORE_DOCS) { //此处的nextDoc使得每个Scorer得到第一篇文档号。 scorerDocQueue.insert(se); } } } |

(3) 当BooleanScorer2.score(Collector)中第一次调用nextDoc()的时候,advanceAfterCurrent被调用。
| public int nextDoc() throws IOException { if (scorerDocQueue.size() < minimumNrMatchers || !advanceAfterCurrent()) { currentDoc = NO_MORE_DOCS; } return currentDoc; } |
| protected boolean advanceAfterCurrent() throws IOException { do { currentDoc = scorerDocQueue.topDoc(); //当前的文档号为最顶层 currentScore = scorerDocQueue.topScore(); //当前文档的打分 nrMatchers = 1; //当前文档满足的子条件的个数,也即包含当前文档号的Scorer的个数 do { //所谓topNextAndAdjustElsePop是指,最顶层(top)的Scorer取下一篇文档(Next),如果能够取到,则最小堆的堆顶可能不再是最小值了,需要调整(Adjust,其实是downHeap()),如果不能够取到,则最顶层的Scorer已经为空,则弹出队列(Pop)。 if (!scorerDocQueue.topNextAndAdjustElsePop()) { if (scorerDocQueue.size() == 0) { break; // nothing more to advance, check for last match. } } //当最顶层的Scorer取到下一篇文档,并且调整完毕后,再取出此时最上层的Scorer的第一篇文档,如果不是currentDoc,说明currentDoc此文档号已经统计完毕nrMatchers,则退出内层循环。 if (scorerDocQueue.topDoc() != currentDoc) { break; // All remaining subscorers are after currentDoc. } //否则nrMatchers加一,也即又多了一个Scorer也包含此文档号。 currentScore += scorerDocQueue.topScore(); nrMatchers++; } while (true); //如果统计出的nrMatchers大于最少需满足的子条件的个数,则此currentDoc就是满足条件的文档,则返回true,在收集文档的过程中,DisjunctionSumScorer.docID()会被调用,返回currentDoc。 if (nrMatchers >= minimumNrMatchers) { return true; } else if (scorerDocQueue.size() < minimumNrMatchers) { return false; } } while (true); } |
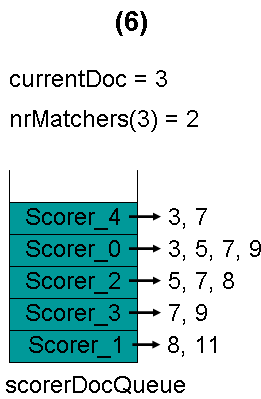
最初,currentDoc=2,文档2的nrMatchers=1

最顶层的Scorer 0取得下一篇文档,为文档3,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 1的第一篇文档号,都为2,文档2的nrMatchers为2。

最顶层的Scorer 1取得下一篇文档,为文档8,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 3的第一篇文档号,都为2,文档2的nrMatchers为3。

最顶层的Scorer 3取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc还为2,不等于最顶层Scorer 2的第一篇文档3,于是退出内循环。此时检查,发现文档2的nrMatchers为3,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 2的第一篇文档3,nrMatchers设为1,重新进入下一轮循环。

最顶层的Scorer 2取得下一篇文档,为文档5,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 4的第一篇文档号,都为3,文档3的nrMatchers为2。
最顶层的Scorer 4取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 0的第一篇文档号,都为3,文档3的nrMatchers为3。

最顶层的Scorer 0取得下一篇文档,为文档5,重新调整最小堆后如下图。此时currentDoc还为3,不等于最顶层Scorer 0的第一篇文档5,于是退出内循环。此时检查,发现文档3的nrMatchers为3,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 0的第一篇文档5,nrMatchers设为1,重新进入下一轮循环。
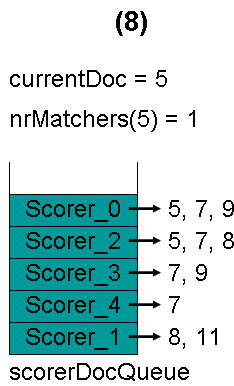
最顶层的Scorer 0取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 2的第一篇文档号,都为5,文档5的nrMatchers为2。
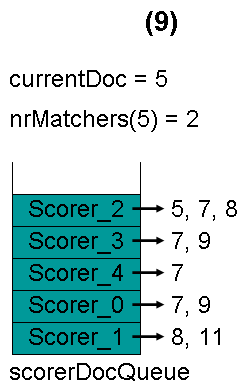
最顶层的Scorer 2取得下一篇文档,为文档7,重新调整最小堆后如下图。此时currentDoc还为5,不等于最顶层Scorer 2的第一篇文档7,于是退出内循环。此时检查,发现文档5的nrMatchers为2,小于minimumNrMatchers,不满足条件。于是currentDoc设为最顶层Scorer 2的第一篇文档7,nrMatchers设为1,重新进入下一轮循环。

最顶层的Scorer 2取得下一篇文档,为文档8,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 3的第一篇文档号,都为7,文档7的nrMatchers为2。
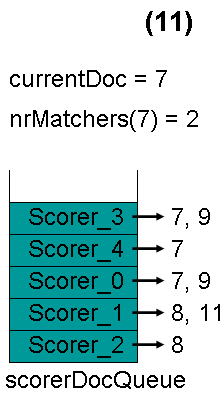
最顶层的Scorer 3取得下一篇文档,为文档9,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 4的第一篇文档号,都为7,文档7的nrMatchers为3。

最顶层的Scorer 4取得下一篇文档,结果为空,Scorer 4所有的文档遍历完毕,弹出队列,重新调整最小堆后如下图。此时currentDoc等于最顶层Scorer 0的第一篇文档号,都为7,文档7的nrMatchers为4。

最顶层的Scorer 0取得下一篇文档,为文档9,重新调整最小堆后如下图。此时currentDoc还为7,不等于最顶层Scorer 1的第一篇文档8,于是退出内循环。此时检查,发现文档7的nrMatchers为4,大于等于minimumNrMatchers,满足条件,返回true,退出外循环。
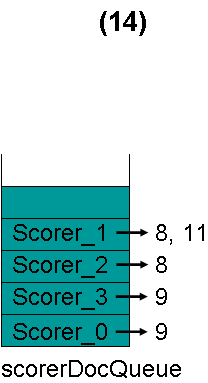
(4) currentDoc设为7,在收集文档的过程中,DisjunctionSumScorer.docID()会被调用,返回currentDoc,也即当前的文档号为7。
(5) 当再次调用nextDoc()的时候,文档8, 9, 11都不满足要求,最后返回NO_MORE_DOCS,倒排表合并结束。
[b]2.4.3.3、差集ReqExclScorer(+A -B)[/b]
ReqExclScorer有成员变量Scorer reqScorer表示必须满足的部分(required),成员变量DocIdSetIterator exclDisi表示必须不能满足的部分,ReqExclScorer就是返回reqScorer和exclDisi的倒排表的差集,也即在reqScorer的倒排表中排除exclDisi中的文档号。
当nextDoc()调用的时候,首先取得reqScorer的第一个文档号,然后toNonExcluded()函数则判断此文档号是否被exclDisi排除掉,如果没有,则返回此文档号,如果排除掉,则取下一个文档号,看是否被排除掉,依次类推,直到找到一个文档号,或者返回NO_MORE_DOCS。
| public int nextDoc() throws IOException { if (reqScorer == null) { return doc; } doc = reqScorer.nextDoc(); if (doc == NO_MORE_DOCS) { reqScorer = null; return doc; } if (exclDisi == null) { return doc; } return doc = toNonExcluded(); } |
| private int toNonExcluded() throws IOException { //取得被排除的文档号 int exclDoc = exclDisi.docID(); //取得当前required文档号 int reqDoc = reqScorer.docID(); do { //如果required文档号小于被排除的文档号,由于倒排表是按照从小到大的顺序排列的,因而此required文档号不会被排除,返回。 if (reqDoc < exclDoc) { return reqDoc; } else if (reqDoc > exclDoc) { //如果required文档号大于被排除的文档号,则此required文档号有可能被排除。于是exclDisi移动到大于或者等于required文档号的文档。 exclDoc = exclDisi.advance(reqDoc); //如果被排除的倒排表遍历结束,则required文档号不会被排除,返回。 if (exclDoc == NO_MORE_DOCS) { exclDisi = null; return reqDoc; } //如果exclDisi移动后,大于required文档号,则required文档号不会被排除,返回。 if (exclDoc > reqDoc) { return reqDoc; // not excluded } } //如果required文档号等于被排除的文档号,则被排除,取下一个required文档号。 } while ((reqDoc = reqScorer.nextDoc()) != NO_MORE_DOCS); reqScorer = null; return NO_MORE_DOCS; } |
ReqOptSumScorer包含两个成员变量,Scorer reqScorer代表必须(required)满足的文档倒排表,Scorer optScorer代表可以(optional)满足的文档倒排表。
如代码显示,在nextDoc()中,返回的就是required的文档倒排表,只不过在计算score的时候打分更高。
| public int nextDoc() throws IOException { return reqScorer.nextDoc(); } |
在BooleanWeight.scorer生成Scorer树的时候,除了生成上述的BooleanScorer2外, 还会生成BooleanScorer,是在以下的条件下:
!scoreDocsInOrder:根据2.4.2节的步骤(c),scoreDocsInOrder = !collector.acceptsDocsOutOfOrder(),此值是在search中调用TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder())的时候设定的,scoreDocsInOrder = !weight.scoresDocsOutOfOrder(),其代码如下:
| public boolean scoresDocsOutOfOrder() { int numProhibited = 0; for (BooleanClause c : clauses) { if (c.isRequired()) { return false; } else if (c.isProhibited()) { ++numProhibited; } } if (numProhibited > 32) { return false; } return true; } |
required.size() == 0,没有必须满足的子语句。
prohibited.size() < 32,不需不能满足的子语句小于32。
从上面可以看出,最后两个条件和scoresDocsOutOfOrder函数中的逻辑是一致的。
下面我们看看BooleanScorer如何合并倒排表的:
| public int nextDoc() throws IOException { boolean more; do { //bucketTable等于是存放合并后的倒排表的文档队列 while (bucketTable.first != null) { //从队列中取出第一篇文档,返回 current = bucketTable.first; bucketTable.first = current.next; if ((current.bits & prohibitedMask) == 0 && (current.bits & requiredMask) == requiredMask && current.coord >= minNrShouldMatch) { return doc = current.doc; } } //如果队列为空,则填充队列。 more = false; end += BucketTable.SIZE; //按照Scorer的顺序,依次用Scorer中的倒排表填充队列,填满为止。 for (SubScorer sub = scorers; sub != null; sub = sub.next) { Scorer scorer = sub.scorer; sub.collector.setScorer(scorer); int doc = scorer.docID(); while (doc < end) { sub.collector.collect(doc); doc = scorer.nextDoc(); } more |= (doc != NO_MORE_DOCS); } } while (bucketTable.first != null || more); return doc = NO_MORE_DOCS; } |
| public final void collect(final int doc) throws IOException { final BucketTable table = bucketTable; final int i = doc & BucketTable.MASK; Bucket bucket = table.buckets[i]; if (bucket == null) table.buckets[i] = bucket = new Bucket(); if (bucket.doc != doc) { bucket.doc = doc; bucket.score = scorer.score(); bucket.bits = mask; bucket.coord = 1; bucket.next = table.first; table.first = bucket; } else { bucket.score += scorer.score(); bucket.bits |= mask; bucket.coord++; } } |
从原理上我们可以理解,在AND的查询条件下,倒排表的合并按照算法需要按照文档号从小到大的顺序排列。然而在没有AND的查询条件下,如果都是OR,则文档号是否按照顺序返回就不重要了,因而scoreDocsInOrder就是false。
因而上面的DisjunctionSumScorer,其实"apple boy dog"是不能产生DisjunctionSumScorer的,而仅有在有AND的查询条件下,才产生DisjunctionSumScorer。
我们做实验如下:
对于查询语句"apple boy dog",生成的Scorer如下:
| scorer BooleanScorer (id=34) bucketTable BooleanScorer$BucketTable (id=39) coordFactors float[4] (id=41) current null doc -1 doc -1 end 0 maxCoord 4 minNrShouldMatch 0 nextMask 1 prohibitedMask 0 requiredMask 0 scorers BooleanScorer$SubScorer (id=43) collector BooleanScorer$BooleanScorerCollector (id=49) next BooleanScorer$SubScorer (id=51) collector BooleanScorer$BooleanScorerCollector (id=68) next BooleanScorer$SubScorer (id=69) collector BooleanScorer$BooleanScorerCollector (id=76) next null prohibited false required false scorer TermScorer (id=77) doc -1 doc 0 docs int[32] (id=79) freqs int[32] (id=80) norms byte[4] (id=58) pointer 0 pointerMax 2 scoreCache float[32] (id=81) similarity DefaultSimilarity (id=45) termDocs SegmentTermDocs (id=82) weight TermQuery$TermWeight (id=84) //weight(contents:apple) weightValue 0.828608 prohibited false required false scorer TermScorer (id=70) doc -1 doc 1 docs int[32] (id=72) freqs int[32] (id=73) norms byte[4] (id=58) pointer 0 pointerMax 1 scoreCache float[32] (id=74) similarity DefaultSimilarity (id=45) termDocs SegmentTermDocs (id=86) weight TermQuery$TermWeight (id=87) //weight(contents:boy) weightValue 1.5407716 prohibited false required false scorer TermScorer (id=52) doc -1 doc 0 docs int[32] (id=54) freqs int[32] (id=56) norms byte[4] (id=58) pointer 0 pointerMax 3 scoreCache float[32] (id=61) similarity DefaultSimilarity (id=45) termDocs SegmentTermDocs (id=62) weight TermQuery$TermWeight (id=66) //weight(contents:cat) weightValue 0.48904076 similarity DefaultSimilarity (id=45) |
| scorer BooleanScorer2 (id=40) coordinator BooleanScorer2$Coordinator (id=42) countingSumScorer ReqOptSumScorer (id=43) minNrShouldMatch 0 optionalScorers ArrayList (id=44) elementData Object[10] (id=62) [0] BooleanScorer2 (id=84) coordinator BooleanScorer2$Coordinator (id=87) countingSumScorer BooleanScorer2$1 (id=88) minNrShouldMatch 0 optionalScorers ArrayList (id=89) elementData Object[10] (id=95) [0] TermScorer (id=97) docs int[32] (id=101) freqs int[32] (id=102) norms byte[4] (id=71) pointer 0 pointerMax 2 scoreCache float[32] (id=103) similarity DefaultSimilarity (id=48) termDocs SegmentTermDocs (id=104) //weight(contents:apple) weight TermQuery$TermWeight (id=105) weightValue 0.525491 [1] TermScorer (id=98) docs int[32] (id=107) freqs int[32] (id=108) norms byte[4] (id=71) pointer 0 pointerMax 1 scoreCache float[32] (id=110) similarity DefaultSimilarity (id=48) termDocs SegmentTermDocs (id=111) //weight(contents:boy) weight TermQuery$TermWeight (id=112) weightValue 0.9771348 [2] TermScorer (id=99) docs int[32] (id=114) freqs int[32] (id=118) norms byte[4] (id=71) pointer 0 pointerMax 3 scoreCache float[32] (id=119) similarity DefaultSimilarity (id=48) termDocs SegmentTermDocs (id=120) //weight(contents:cat) weight TermQuery$TermWeight (id=121) weightValue 0.3101425 size 3 prohibitedScorers ArrayList (id=90) requiredScorers ArrayList (id=91) similarity DefaultSimilarity (id=48) size 1 prohibitedScorers ArrayList (id=46) requiredScorers ArrayList (id=47) elementData Object[10] (id=59) [0] TermScorer (id=66) docs int[32] (id=68) freqs int[32] (id=70) norms byte[4] (id=71) pointer 0 pointerMax 0 scoreCache float[32] (id=73) similarity DefaultSimilarity (id=48) termDocs SegmentTermDocs (id=76) weight TermQuery$TermWeight (id=78) //weight(contents:hello) weightValue 2.6944637 size 1 similarity DefaultSimilarity (id=48) |
2.4、搜索查询对象
2.4.4、收集文档结果集合及计算打分
在函数IndexSearcher.search(Weight, Filter, int) 中,有如下代码:TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder());
search(weight, filter, collector);
return collector.topDocs();
[b]2.4.4.1、创建结果文档收集器[/b]
TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder());
| public static TopScoreDocCollector create(int numHits, boolean docsScoredInOrder) { if (docsScoredInOrder) { return new InOrderTopScoreDocCollector(numHits); } else { return new OutOfOrderTopScoreDocCollector(numHits); } } |
[b]2.4.4.2、收集文档号[/b]
当创建完毕Scorer对象树和SumScorer对象树后,IndexSearcher.search(Weight, Filter, Collector) 有以下调用:
scorer.score(collector) ,如下代码所示,其不断的得到合并的倒排表后的文档号,并收集它们。
| public void score(Collector collector) throws IOException { collector.setScorer(this); while ((doc = countingSumScorer.nextDoc()) != NO_MORE_DOCS) { collector.collect(doc); } } |
| public void collect(int doc) throws IOException { float score = scorer.score(); totalHits++; if (score <= pqTop.score) { return; } pqTop.doc = doc + docBase; pqTop.score = score; pqTop = pq.updateTop(); } |
| public void collect(int doc) throws IOException { float score = scorer.score(); totalHits++; doc += docBase; if (score < pqTop.score || (score == pqTop.score && doc > pqTop.doc)) { return; } pqTop.doc = doc; pqTop.score = score; pqTop = pq.updateTop(); } |
然而存在一个问题,如果要取10篇文档,而第8,9,10,11,12篇文档的打分都相同,则抛弃那些呢?Lucene的策略是,在文档打分相同的情况下,文档号小的优先。
也即8,9,10被保留,11,12被抛弃。
由上面的叙述可知,创建collector的时候,根据文档是否将按照文档号从小到大的顺序返回而创建InOrderTopScoreDocCollector或者OutOfOrderTopScoreDocCollector。
对于InOrderTopScoreDocCollector,由于文档是按照顺序返回的,后来的文档号肯定大于前面的文档号,因而当score <= pqTop.score的时候,直接抛弃。
对于OutOfOrderTopScoreDocCollector,由于文档不是按顺序返回的,因而当score
[b]2.4.4.3、打分计算[/b]
BooleanScorer2的打分函数如下:
将子语句的打分乘以coord
| public float score() throws IOException { coordinator.nrMatchers = 0; float sum = countingSumScorer.score(); return sum * coordinator.coordFactors[coordinator.nrMatchers]; } |
将取交集的子语句的打分相加,然后乘以coord
| public float score() throws IOException { float sum = 0.0f; for (int i = 0; i < scorers.length; i++) { sum += scorers[i].score(); } return sum * coord; } |
| public float score() throws IOException { return currentScore; } currentScore计算如下: currentScore += scorerDocQueue.topScore(); 以上计算是在DisjunctionSumScorer的倒排表合并算法中进行的,其是取堆顶的打分函数。 public final float topScore() throws IOException { return topHSD.scorer.score(); } |
仅仅取required语句的打分
| public float score() throws IOException { return reqScorer.score(); } |
上面曾经指出,ReqOptSumScorer的nextDoc()函数仅仅返回required语句的文档号。
而optional的部分仅仅在打分的时候有所体现,从下面的实现可以看出optional的语句的分数加到required语句的分数上,也即文档还是required语句包含的文档,只不过是当此文档能够满足optional的语句的时候,打分得到增加。
| public float score() throws IOException { int curDoc = reqScorer.docID(); float reqScore = reqScorer.score(); if (optScorer == null) { return reqScore; } int optScorerDoc = optScorer.docID(); if (optScorerDoc < curDoc && (optScorerDoc = optScorer.advance(curDoc)) == NO_MORE_DOCS) { optScorer = null; return reqScore; } return optScorerDoc == curDoc ? reqScore + optScorer.score() : reqScore; } |
整个Scorer及SumScorer对象树的打分计算,最终都会源自叶子节点TermScorer上。
从TermScorer的计算可以看出,它计算出tf * norm * weightValue = tf * norm * queryNorm * idf^2 * t.getBoost()
| public float score() { int f = freqs[pointer]; float raw = f < SCORE_CACHE_SIZE ? scoreCache[f] : getSimilarity().tf(f)*weightValue; return norms == null ? raw : raw * SIM_NORM_DECODER[norms[doc] & 0xFF]; } |
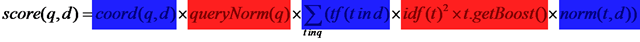
打分计算到此结束。
[b]2.4.4.4、返回打分最高的N篇文档[/b]
IndexSearcher.search(Weight, Filter, int)中,在收集完文档后,调用collector.topDocs()返回打分最高的N篇文档:
| public final TopDocs topDocs() { return topDocs(0, totalHits < pq.size() ? totalHits : pq.size()); } |
| public final TopDocs topDocs(int start, int howMany) { int size = totalHits < pq.size() ? totalHits : pq.size(); howMany = Math.min(size - start, howMany); ScoreDoc[] results = new ScoreDoc[howMany]; //由于pq是最小堆,因而要首先弹出最小的文档。比如qp中总共有50篇文档,想取第5到10篇文档,则应该先弹出打分最小的40篇文档。 for (int i = pq.size() - start - howMany; i > 0; i--) { pq.pop(); } populateResults(results, howMany); return newTopDocs(results, start); } |
| protected void populateResults(ScoreDoc[] results, int howMany) { //然后再从pq弹出第5到10篇文档,并按照打分从大到小的顺序放入results中。 for (int i = howMany - 1; i >= 0; i--) { results[i] = pq.pop(); } } |
| protected TopDocs newTopDocs(ScoreDoc[] results, int start) { return results == null ? EMPTY_TOPDOCS : new TopDocs(totalHits, results); } |
2.4.5、Lucene如何在搜索阶段读取索引信息
以上叙述的是搜索过程中如何进行倒排表合并以及计算打分。然而索引信息是从索引文件中读出来的,下面分析如何读取这些信息。其实读取的信息无非是两种信息,一个是词典信息,一个是倒排表信息。
词典信息的读取是在Scorer对象树生成的时候进行的,真正读取这些信息的是叶子节点TermScorer。
倒排表信息的读取时在合并倒排表的时候进行的,真正读取这些信息的也是叶子节点TermScorer.nextDoc()。
[b]2.4.5.1、读取词典信息[/b]
此步是在TermWeight.scorer(IndexReader, boolean, boolean) 中进行的,其代码如下:
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer) { TermDocs termDocs = reader.termDocs(term); if (termDocs == null) return null; return new TermScorer(this, termDocs, similarity, reader.norms(term.field())); } |
| public TermDocs termDocs(Term term) throws IOException { ensureOpen(); TermDocs termDocs = termDocs(); termDocs.seek(term); return termDocs; } |
| protected SegmentTermDocs(SegmentReader parent) { this.parent = parent; this.freqStream = (IndexInput) parent.core.freqStream.clone();//用于读取freq synchronized (parent) { this.deletedDocs = parent.deletedDocs; } this.skipInterval = parent.core.getTermsReader().getSkipInterval(); this.maxSkipLevels = parent.core.getTermsReader().getMaxSkipLevels(); } |
| public void seek(Term term) throws IOException { TermInfo ti = parent.core.getTermsReader().get(term); seek(ti, term); } |
| TermInfosReader.get(Term, boolean)主要是读取词典中的Term得到TermInfo,代码如下: private TermInfo get(Term term, boolean useCache) { if (size == 0) return null; ensureIndexIsRead(); TermInfo ti; ThreadResources resources = getThreadResources(); SegmentTermEnum enumerator = resources.termEnum; seekEnum(enumerator, getIndexOffset(term)); enumerator.scanTo(term); if (enumerator.term() != null && term.compareTo(enumerator.term()) == 0) { ti = enumerator.termInfo(); } else { ti = null; } return ti; } |
| private final void seekEnum(SegmentTermEnum enumerator, int indexOffset) throws IOException { enumerator.seek(indexPointers[indexOffset], (indexOffset * totalIndexInterval) - 1, indexTerms[indexOffset], indexInfos[indexOffset]); } |
| final void SegmentTermEnum.seek(long pointer, int p, Term t, TermInfo ti) { input.seek(pointer); position = p; termBuffer.set(t); prevBuffer.reset(); termInfo.set(ti); } |
| final int scanTo(Term term) throws IOException { scanBuffer.set(term); int count = 0; //不断取得下一个term到termBuffer中,目标term放入scanBuffer中,当两者相等的时候,目标Term找到。 while (scanBuffer.compareTo(termBuffer) > 0 && next()) { count++; } return count; } |
| public final boolean next() throws IOException { if (position++ >= size - 1) { prevBuffer.set(termBuffer); termBuffer.reset(); return false; } prevBuffer.set(termBuffer); //读取Term的字符串 termBuffer.read(input, fieldInfos); //读取docFreq,也即多少文档包含此Term termInfo.docFreq = input.readVInt(); //读取偏移量 termInfo.freqPointer += input.readVLong(); termInfo.proxPointer += input.readVLong(); if (termInfo.docFreq >= skipInterval) termInfo.skipOffset = input.readVInt(); indexPointer += input.readVLong(); return true; } |
| TermBuffer.read(IndexInput, FieldInfos) 代码如下: public final void read(IndexInput input, FieldInfos fieldInfos) { this.term = null; int start = input.readVInt(); int length = input.readVInt(); int totalLength = start + length; text.setLength(totalLength); input.readChars(text.result, start, length); this.field = fieldInfos.fieldName(input.readVInt()); } |
| void seek(TermInfo ti, Term term) { count = 0; FieldInfo fi = parent.core.fieldInfos.fieldInfo(term.field); df = ti.docFreq; doc = 0; freqBasePointer = ti.freqPointer; proxBasePointer = ti.proxPointer; skipPointer = freqBasePointer + ti.skipOffset; freqStream.seek(freqBasePointer); haveSkipped = false; } |
当读出Term的信息得到TermInfo后,并且freqStream指向此Term的倒排表位置的时候,下面就是在TermScorer.nextDoc()函数中读取倒排表信息:
| public int nextDoc() throws IOException { pointer++; if (pointer >= pointerMax) { pointerMax = termDocs.read(docs, freqs); if (pointerMax != 0) { pointer = 0; } else { termDocs.close(); return doc = NO_MORE_DOCS; } } doc = docs[pointer]; return doc; } |
| public int read(final int[] docs, final int[] freqs) { final int length = docs.length; int i = 0; while (i < length && count < df) { //读取docid final int docCode = freqStream.readVInt(); doc += docCode >>> 1; if ((docCode & 1) != 0) freq = 1; else freq = freqStream.readVInt(); //读取freq count++; if (deletedDocs == null || !deletedDocs.get(doc)) { docs[i] = doc; freqs[i] = freq; ++i; } return i; } } |

相关文章推荐
- Lucene学习总结之七:Lucene搜索过程解析(7)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结:Lucene搜索过程解析
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(8)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(3)