[LNU.Machine Learning.Question.1]梯度下降方法的一些理解
2014-06-24 14:22
225 查看
以前学习machine learning,在regression这一节,对求解最优化问题的梯度下降方法,理解总是处于字面意义上的生吞活剥。对梯度的概念感觉费解?究竟是标量还是矢量?为什么沿着负梯度方向函数下降最快?想清楚的回答这些问题,还真需要点探究精神。
我查阅了一些经典的资料(包括wiki百科),还有一些个人的博客,比如http://www.codelast.com/?p=2573,http://blog.csdn.net/xmu_jupiter/article/details/22220987,都对梯度下降概念有个大概的直观解释,参照这些资料中的内容,再结合个人的体会,姑且谈谈.
1.为什么在多元函数自变量的研究中引入方向?
在自变量为一维的情况下,也就是自变量可以视为一个标量,此时,一个实数就可以代表它了,这个时候,如果要改变自变量的值,则其要么减小,要么增加,也就是“非左即右“。所以,说到“自变量在某个方向上移动”这个概念的时候,它并不是十分明显;而在自变量为n(n≥2)维的情况下,这个概念就有用了起来:假设自变量X为3维的,即每一个X是(x1, x2, x3)这样的一个点,其中x1,x2和x3分别是一个实数,即标量。那么,如果要改变X,即将一个点移动到另一个点,你怎么移动?可以选择的方法太多了,例如,我们可以令x1,x2不变,仅使x3改变,也可以令x1,x3不变,仅使x2改变,等等。这些做法也就使得我们有了”方向“的概念,因为在3维空间中,一个点移动到另一个点,并不是像一维情况下那样“非左即右”的,而是有“方向”的。在这样的情况下,找到一个合适的”方向“,使得从一个点移动到另一个点的时候,函数值的改变最符合我们预定的要求(例如,函数值要减小到什么程度),就变得十分有必要了。
2.为什么是梯度下降(Gradient Descent)
根据维基百科的定义,如果实值函数

在点
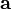
处可微且有定义,那么函数
在
点沿着梯度相反(什么是梯度?这也要问?

)的方向

下降最快。因而我们在回归所导出的优化问题中采用梯度下降的方法来寻找最优点问题


3.那么,为什么方向
下降最快?
爱问为什么的学生死得快(

).解释这一问题,还需要用到Taylor展开,回忆:

在梯度的概念下,这个式子可以进一步化为:

(a)

:代表第k个点的自变量(一个向量)。
d:单位方向(一个向量),即 |d|=1。

:步长(一个实数)。

:目标函数在Xk这一点的梯度(一个向量)。

:α的高阶无穷小。
在(a)式中,
可以忽略不计。
所谓最速下降,即意味着

也就是说希望(a)式取最小,即认为

最小,而
是向量内积的形式(假设向量d与负梯度

的夹角为θ):

(b)
(b)式取最小当且仅当\theta=0,此时方向向量d(自变量的变化方向)取负梯度
方向,这个方向就是梯度变化最大的方向(负变化最小,始终要求方向的概念在脑海中)。
4.几何解释
下面图片示例了这一过程,这里假设 F 定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数 F 为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数 F 值最小的点

梯度下降法几何解释:
由于我们的任务是求得经验损失函数的最小值,所以上图的过程实际上是一个“下坡”的过程。在每一个点上,我们希望往下走一步(假设一步为固定值0.5米),使得下降的高度最大,那么我们就要选择坡度变化率最大的方向往下走,这个方向就是经验损失函数在这一点梯度的反方向。每走一步,我们都要重新计算函数在当前点的梯度,然后选择梯度的反方向作为走下去的方向。随着每一步迭代,梯度不断地减小,到最后减小为零。这就是为什么叫“梯度下降法”。
先说到这里,敲符号、磊代码太累......
在此,向Orange先生、learnhard、wiki表示由衷的感谢
我查阅了一些经典的资料(包括wiki百科),还有一些个人的博客,比如http://www.codelast.com/?p=2573,http://blog.csdn.net/xmu_jupiter/article/details/22220987,都对梯度下降概念有个大概的直观解释,参照这些资料中的内容,再结合个人的体会,姑且谈谈.
1.为什么在多元函数自变量的研究中引入方向?
在自变量为一维的情况下,也就是自变量可以视为一个标量,此时,一个实数就可以代表它了,这个时候,如果要改变自变量的值,则其要么减小,要么增加,也就是“非左即右“。所以,说到“自变量在某个方向上移动”这个概念的时候,它并不是十分明显;而在自变量为n(n≥2)维的情况下,这个概念就有用了起来:假设自变量X为3维的,即每一个X是(x1, x2, x3)这样的一个点,其中x1,x2和x3分别是一个实数,即标量。那么,如果要改变X,即将一个点移动到另一个点,你怎么移动?可以选择的方法太多了,例如,我们可以令x1,x2不变,仅使x3改变,也可以令x1,x3不变,仅使x2改变,等等。这些做法也就使得我们有了”方向“的概念,因为在3维空间中,一个点移动到另一个点,并不是像一维情况下那样“非左即右”的,而是有“方向”的。在这样的情况下,找到一个合适的”方向“,使得从一个点移动到另一个点的时候,函数值的改变最符合我们预定的要求(例如,函数值要减小到什么程度),就变得十分有必要了。
2.为什么是梯度下降(Gradient Descent)
根据维基百科的定义,如果实值函数
在点
处可微且有定义,那么函数
在
点沿着梯度相反(什么是梯度?这也要问?
)的方向
下降最快。因而我们在回归所导出的优化问题中采用梯度下降的方法来寻找最优点问题
3.那么,为什么方向
下降最快?
爱问为什么的学生死得快(
).解释这一问题,还需要用到Taylor展开,回忆:
在梯度的概念下,这个式子可以进一步化为:
(a)
:代表第k个点的自变量(一个向量)。
d:单位方向(一个向量),即 |d|=1。
:步长(一个实数)。
:目标函数在Xk这一点的梯度(一个向量)。
:α的高阶无穷小。
在(a)式中,
可以忽略不计。
所谓最速下降,即意味着
也就是说希望(a)式取最小,即认为
最小,而
是向量内积的形式(假设向量d与负梯度
的夹角为θ):
(b)
(b)式取最小当且仅当\theta=0,此时方向向量d(自变量的变化方向)取负梯度
方向,这个方向就是梯度变化最大的方向(负变化最小,始终要求方向的概念在脑海中)。
4.几何解释
下面图片示例了这一过程,这里假设 F 定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数 F 为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数 F 值最小的点
梯度下降法几何解释:
由于我们的任务是求得经验损失函数的最小值,所以上图的过程实际上是一个“下坡”的过程。在每一个点上,我们希望往下走一步(假设一步为固定值0.5米),使得下降的高度最大,那么我们就要选择坡度变化率最大的方向往下走,这个方向就是经验损失函数在这一点梯度的反方向。每走一步,我们都要重新计算函数在当前点的梯度,然后选择梯度的反方向作为走下去的方向。随着每一步迭代,梯度不断地减小,到最后减小为零。这就是为什么叫“梯度下降法”。
先说到这里,敲符号、磊代码太累......
在此,向Orange先生、learnhard、wiki表示由衷的感谢

相关文章推荐
- 梯度下降方法的一些理解
- [LNU.Machine Learning.Question.1]梯度下降方法的一些理解
- 一些知识点的初步理解_5(梯度下降,ing...)
- Caffe Solver理解篇(2) SGD, AdaDelta, Ada-Grad, Adam, NAG, RMSprop 六种梯度下降方法横向对比
- 关于梯度下降的的一些理解
- 一些知识点的初步理解_5(梯度下降,ing...)
- openWRT自学---对官方的开发指导文档的解读和理解 记录3:一些常用方法
- UIView的一些基本方法理解:loadView、viewDidLoad、viewDidUnload、viewWillAppear、viewWillDisappear
- 黑马程序员_对绘图方法paint的一些理解
- 对梯度下降法的简单理解
- 迭代器就是重复地做一些事情,可以简单的理解为循环,在python中实现了__iter__方法的对象是可迭代的,实现了next()方法的对象是迭代器,这样说起来有
- IPhone 之 UIView的一些基本方法理解
- 梯度下降方法
- 最优化方法:梯度下降(批梯度下降和随机梯度下降)
- 几种常用的优化方法梯度下降法、牛顿法、)
- 关于hashcode和equals方法重写的一些理解!
- UIView的一些基本方法理解
- UIView的一些基本方法理解:loadView、viewDidLoad、viewDidUnload、viewWillAppear、viewWillDisappear
- UIView的一些基本方法理解
- IOS学习笔记10-UIView的一些基本方法理解:loadView、viewDidLoad、viewDidUnload、viewWillAppear、viewWillDisappear、