堆排序的算法实现
2014-06-06 00:00
197 查看
摘要: 由于堆排序算法说起来比较长,所以在这里单独讲一下。堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L
看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。
由于堆排序算法说起来比较长,所以在这里单独讲一下。堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L
看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。
一,堆的定义
堆的定义如下:n个关键字序列L
成为堆,当且仅当该序列满足:①L(i) <= L(2i)且L(i) <= L(2i+1) 或者 ②L(i) >= L(2i)且L(i) >= L(2i+1) 其中i属于[1, n/2]。
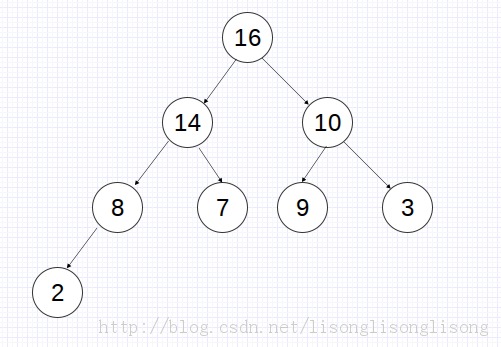
满足第①种情况的堆称为小根堆(小顶堆),满足第②种情况的堆称为大根堆(大顶堆)。在大根堆中,最大元素存放在根结点中,且对任一非根结点,它的值小于或等于其双亲结点值。小根堆则恰恰相反,小根堆的根结点存放的是最小元素。例如{16, 14, 10, 8, 7, 9, 3, 2}表示的大根堆:
二,构造初始堆
堆排序的关键就是构造初始堆。n个结点的完全二叉树中,最后一个结点是第n/2(向下取整)个结点的孩子。所以构造初始堆的流程是:对第n/2(向下取整)个结点为根的子树进行筛选(以大根堆为例,若根结点的关键字小于左右子女中关键字的较大者,则交换),使该子树成为堆。之后向前依次对从n/2-1到1的各结点为根的子树进行筛选,看该结点值是否大于其左右子结点的值,若不是,将左右子结点中较大值与之交换,交换后可能会破坏下一级的堆,于是继续采用上述方法构造下一级的堆,直到以该结点为根的子树构成堆为止。反复利用上述调整堆的方法建堆,直到根结点。
由于在数组中下标从0开始,所以在堆中i的左子结点为2*i+1,右子结点为2*i+2。下面是将某个结点i向下调整建堆的算法实现:
建堆,从n/2(向下取整)到1依次对各结点向下调整,当然由于数组下标从0开始,所以:
三,堆排序
构造初始堆成功以后,堆排序的思路就很简单了:首先将存放在L
中的n个元素建成初始堆,由于堆本身的特点(以大根堆为例),堆顶元素就是最大值。输出堆顶元素后,通常将堆底元素送入堆顶,此时根结点已不满足大根堆的性质,堆被破坏。这时将堆顶元素向下调整使其继续保持大根堆的性质,再输出堆顶元素。如此重复,直到堆中仅剩下一个元素为止。算法实现如下:
四,性能
时间复杂度:向下调整的时间与树高有关,为O(h)。可以证明在元素个数为n的序列上建堆,其时间复杂度为O(n)。之后还有n-1次向下调整操作,每次调整的时间为O(h),故在最好,最坏和平均情况下,堆排序的时间复杂度为O(nlogn)。
空间复杂度:仅使用了常数个辅助单元,空间复杂度为O(1)。
稳定性:不稳定。
个人博客:http://songlee24.github.com
看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。
由于堆排序算法说起来比较长,所以在这里单独讲一下。堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L
看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。
一,堆的定义
堆的定义如下:n个关键字序列L
成为堆,当且仅当该序列满足:①L(i) <= L(2i)且L(i) <= L(2i+1) 或者 ②L(i) >= L(2i)且L(i) >= L(2i+1) 其中i属于[1, n/2]。
满足第①种情况的堆称为小根堆(小顶堆),满足第②种情况的堆称为大根堆(大顶堆)。在大根堆中,最大元素存放在根结点中,且对任一非根结点,它的值小于或等于其双亲结点值。小根堆则恰恰相反,小根堆的根结点存放的是最小元素。例如{16, 14, 10, 8, 7, 9, 3, 2}表示的大根堆:
二,构造初始堆
堆排序的关键就是构造初始堆。n个结点的完全二叉树中,最后一个结点是第n/2(向下取整)个结点的孩子。所以构造初始堆的流程是:对第n/2(向下取整)个结点为根的子树进行筛选(以大根堆为例,若根结点的关键字小于左右子女中关键字的较大者,则交换),使该子树成为堆。之后向前依次对从n/2-1到1的各结点为根的子树进行筛选,看该结点值是否大于其左右子结点的值,若不是,将左右子结点中较大值与之交换,交换后可能会破坏下一级的堆,于是继续采用上述方法构造下一级的堆,直到以该结点为根的子树构成堆为止。反复利用上述调整堆的方法建堆,直到根结点。
由于在数组中下标从0开始,所以在堆中i的左子结点为2*i+1,右子结点为2*i+2。下面是将某个结点i向下调整建堆的算法实现:
void AdjustDown(ElementType A[], int i, int len)
{
ElementType temp = A[i]; // 暂存A[i]
for(int largest=2*i+1; largest<len; largest=2*largest+1)
{
if(largest!=len-1 && A[largest+1]>A[largest])
++largest; // 如果右子结点大
if(temp < A[largest])
{
A[i] = A[largest];
i = largest; // 记录交换后的位置
}
else
break;
}
A[i] = temp; // 被筛选结点的值放入最终位置
}建堆,从n/2(向下取整)到1依次对各结点向下调整,当然由于数组下标从0开始,所以:
void BuildMaxHeap(ElementType A[], int len)
{
for(int i=len/2-1; i>=0; --i) // 从i=n/2-1到0,反复调整堆
AdjustDown(A, i, len);
}三,堆排序
构造初始堆成功以后,堆排序的思路就很简单了:首先将存放在L
中的n个元素建成初始堆,由于堆本身的特点(以大根堆为例),堆顶元素就是最大值。输出堆顶元素后,通常将堆底元素送入堆顶,此时根结点已不满足大根堆的性质,堆被破坏。这时将堆顶元素向下调整使其继续保持大根堆的性质,再输出堆顶元素。如此重复,直到堆中仅剩下一个元素为止。算法实现如下:
void HeapSort(ElementType A[], int n)
{
BuildMaxHeap(A, n); // 初始建堆
for(int i=n-1; i>0; --i) // n-1趟的交换和建堆过程
{
// 输出最大的堆顶元素(和堆底元素交换)
A[0] = A[0]^A[i];
A[i] = A[0]^A[i];
A[0] = A[0]^A[i];
// 调整,把剩余的n-1个元素整理成堆
AdjustDown(A, 0, i);
}
}四,性能
时间复杂度:向下调整的时间与树高有关,为O(h)。可以证明在元素个数为n的序列上建堆,其时间复杂度为O(n)。之后还有n-1次向下调整操作,每次调整的时间为O(h),故在最好,最坏和平均情况下,堆排序的时间复杂度为O(nlogn)。
空间复杂度:仅使用了常数个辅助单元,空间复杂度为O(1)。
稳定性:不稳定。
个人博客:http://songlee24.github.com

相关文章推荐
- C# 实现堆排序的算法
- 堆排序(Heap Sort)算法的实现
- 堆排序的算法实现(C/C++)
- 堆排序的代码实现 - 数据结构和算法93
- 算法思路重新实现-堆排序 中的 C++ & Java
- C# 实现常用的算法-- 堆排序(转)
- python算法实现系列-堆排序
- 计算机算法--最大堆实现堆排序(从大到小输出)
- 算法导论之插入排序,选择排序,归并排序,冒泡排序,希尔排序,堆排序,快速排序的c语言实现
- c++堆排序实现(heapsort) (算法导论)
- 算法导论 习题6.2-5 用迭代法实现堆排序
- 基本算法-堆排序及其Java实现
- 堆排序(Heap Sort)算法的实现
- 二叉树-----数组存储结构及操作算法的实现------堆排序
- 算法珠玑--再看堆排序(Heap Sort)的实现
- 堆排序(Heap Sort) 算法实现 C语言版
- 【算法导论】c++实现堆排序
- 算法实现系列第二章.堆排序
- 算法数据结构C++实现8 堆排序 难点分析
- 数组实现堆排序(来源算法导论)