java htmlparser 简单使用入门
2014-06-04 23:03
591 查看
下面对htmlparser 简单介绍下,信息来自百度

htmlparser[1]是一个纯的java写的html(标准通用标记语言下的一个应用)解析的库,它不依赖于其它的java库文件,主要用于改造或
提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.0。
毫不夸张地说,htmlparser就是目前最好的html解析和分析的工具。
无论你是想抓取网页数据还是改造html的内容,用了htmlparser绝对会忍不住称赞。
基本功能
1、信息提取
文本信息抽取,例如对HTML进行有效信息搜索;
链接提取,用于自动给页面的链接文本加上链接的标签;
资源提取,例如对一些图片、声音的资源的处理;
链接检查,用于检查HTML中的链接是否有效;
页面内容的监控。
2、信息转换
链接重写,用于修改页面中的所有超链接;
网页内容拷贝,用于将网页内容保存到本地;
内容检验,可以用来过滤网页上一些令人不愉快的字词;
HTML信息清洗,把本来乱七八糟的HTML信息格式化;
转成XML格式数据。
找了点资料学习了下,将笔记记录下来 官网:http://htmlparser.codeplex.com/
下面使用一个小程序演示下,演示抓取美团上面的文字

发现这些文本都在ul上且ul的样式为filter-strip__list
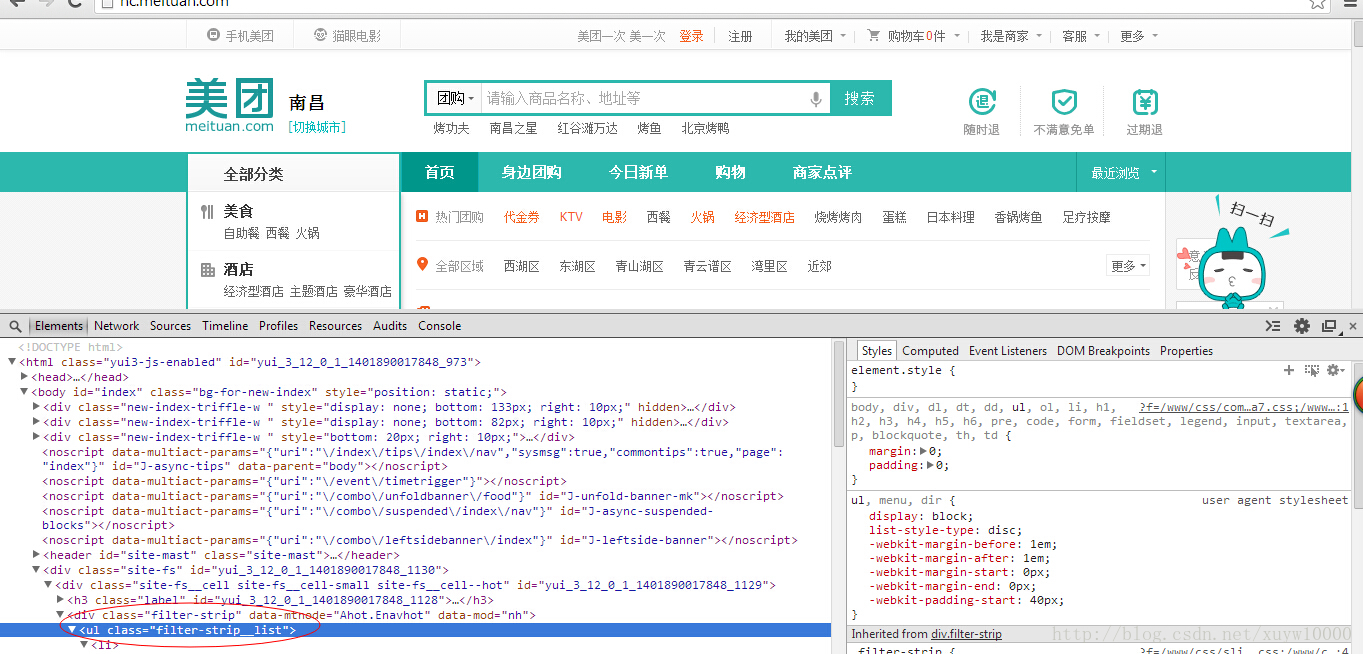
可以通过Ul找到子元素
附上代码
下面简单介绍其他方法
htmlparser[1]是一个纯的java写的html(标准通用标记语言下的一个应用)解析的库,它不依赖于其它的java库文件,主要用于改造或
提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.0。
毫不夸张地说,htmlparser就是目前最好的html解析和分析的工具。
无论你是想抓取网页数据还是改造html的内容,用了htmlparser绝对会忍不住称赞。
基本功能
1、信息提取
文本信息抽取,例如对HTML进行有效信息搜索;
链接提取,用于自动给页面的链接文本加上链接的标签;
资源提取,例如对一些图片、声音的资源的处理;
链接检查,用于检查HTML中的链接是否有效;
页面内容的监控。
2、信息转换
链接重写,用于修改页面中的所有超链接;
网页内容拷贝,用于将网页内容保存到本地;
内容检验,可以用来过滤网页上一些令人不愉快的字词;
HTML信息清洗,把本来乱七八糟的HTML信息格式化;
转成XML格式数据。
找了点资料学习了下,将笔记记录下来 官网:http://htmlparser.codeplex.com/
下面使用一个小程序演示下,演示抓取美团上面的文字
发现这些文本都在ul上且ul的样式为filter-strip__list
可以通过Ul找到子元素
附上代码
package com.test;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.HasAttributeFilter;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
/**
* 获取网页内容
*
* @author xuyw
* @email xyw10000@163.com
* @date 2013-06-04
*/
public class Test3 {
public static void main(String[] args) {
try {
Parser parser = new Parser((HttpURLConnection) (new URL(
"http://nc.meituan.com/")).openConnection());
// TextExtractingVisitor visitor = new TextExtractingVisitor();
// parser.visitAllNodesWith(visitor);
// String textInPage = visitor.getExtractedText();
// System.out.println(textInPage);
//查找含有filter-strip__list样式的元素
NodeFilter filter = new HasAttributeFilter("class",
"filter-strip__list");
NodeList nodes = parser.extractAllNodesThatMatch(filter);
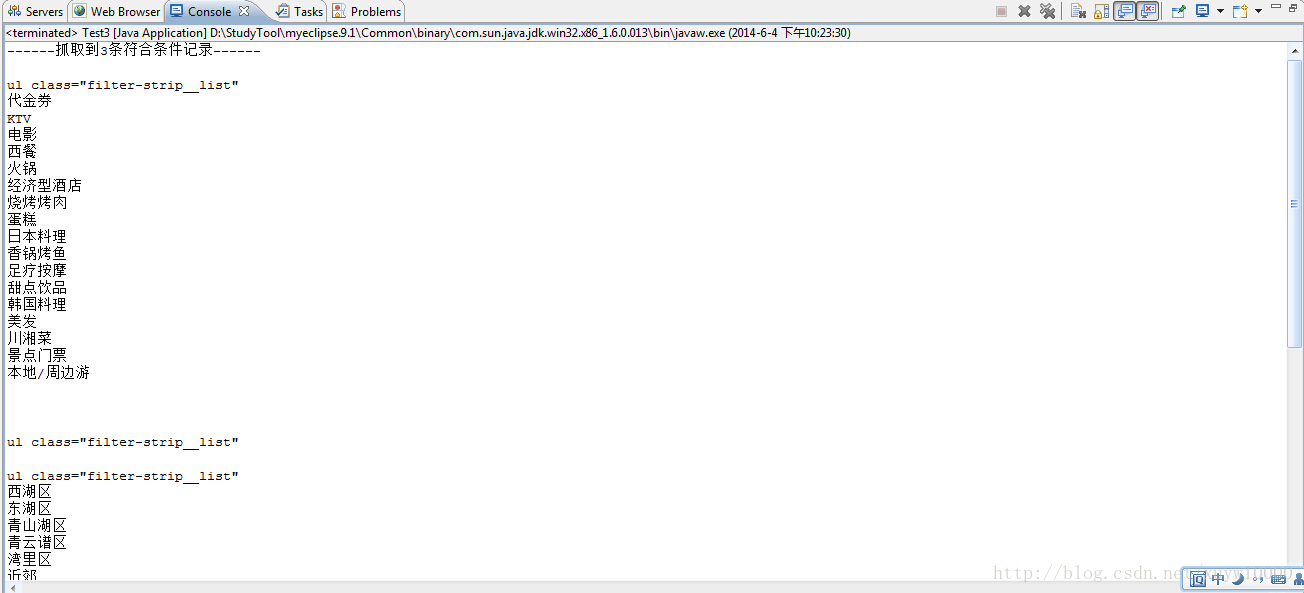
System.out.println("------抓取到" + nodes.size() + "条符合条件记录------");
for (int i = 0; i < nodes.size(); i++) {
Node node = nodes.elementAt(i);
System.out.println();
System.out.println(node.getText());
NodeList cnode = node.getChildren();
for (int j = 0; j < cnode.size(); j++) {
Node tnode = cnode.elementAt(j);
System.out.println(tnode.toPlainTextString());
}
System.out.println();
System.out.println(node.getText());
}
} catch (ParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}运行结果下面简单介绍其他方法
构造函数: public Parser (); public Parser (Lexer lexer, ParserFeedback fb); public Parser (URLConnection connection, ParserFeedback fb) throws ParserException; public Parser (String resource, ParserFeedback feedback) throws ParserException; public Parser (String resource) throws ParserException; public Parser (Lexer lexer); public Parser (URLConnection connection) throws ParserException; public static Parser createParser (String html, String charset);
HTMLParser将解析过的信息保存为一个树的结构。 Node是信息保存的数据类型基础。 Node中包含的方法有几类: Node getParent ()--取得父节点 NodeList getChildren ()--取得子节点的列表 Node getFirstChild ()--取得第一个子节点 Node getLastChild ()--取得最后一个子节点 Node getPreviousSibling ()--取得前一个兄弟 Node getNextSibling ()--取得下一个兄弟节点 取得Node内容的函数: String getText ()--取得文本 String toPlainTextString()--取得纯文本信息。 String toHtml () --取得HTML信息 String toHtml (boolean verbatim):取得HTML信息 String toString ()--取得字符串信息 Page getPage ():--取得这个Node对应的Page对象 int getStartPosition ()--取得这个Node在HTML页面中的起始位置 int getEndPosition ()--取得这个Node在HTML页面中的结束位置 用于Filter过滤的函数: void collectInto (NodeList list, NodeFilter filter):基于filter的条件对于这个节点进行过滤,符合条件的节点放到list中。 用于Visitor遍历的函数: void accept (NodeVisitor visitor):对这个Node应用visitor void setPage (Page page):设置这个Node对应的Page对象 void setText (String text):设置文本 void setChildren (NodeList children):设置子节点列表 其他函数: void doSemanticAction ():执行这个Node对应的操作(只有少数Tag有对应的操作)
Filter类
对结果进行过滤,取得需要的内容。HTMLParser在org.htmlparser.filters包之内一共定义了16个不同的Filter,也可以分为几类。
判断类Filter:
TagNameFilter --标签过滤
HasAttributeFilter --属性过滤
有3个构造函数:
public HasAttributeFilter ();
public HasAttributeFilter (String 属性);
public HasAttributeFilter (String 属性, String 值);
HasChildFilter --子元素过滤
HasParentFilter --父元过滤素
HasSiblingFilter --兄弟过滤
IsEqualFilter
逻辑运算Filter:
AndFilter
可以把两种Filter进行组合
NodeFilter filterID = new HasAttributeFilter( "id" );
NodeFilter filterChild = new HasChildFilter(filterA);
NodeFilter filter = new AndFilter(filterID, filterChild);
NotFilter【类似上面】
OrFilter【类似上面】
XorFilter
NodeFilter filterID = new HasAttributeFilter( "id" );
NodeFilter filterChild = new HasChildFilter(filterA);
NodeFilter filter = new XorFilter(filterID, filterChild);
其他Filter:
NodeClassFilter
NodeFilter filter = new NodeClassFilter(RemarkNode.class);
NodeList nodes = parser.extractAllNodesThatMatch(filter);
StringFilter
用于过滤显示字符串中包含制定内容的Tag。注意是可显示的字符串,不可显示的字符串中的内容(例如注释,链接等等)不会被显示。
NodeFilter filter = new StringFilter("www.baidu.com");
NodeList nodes = parser.extractAllNodesThatMatch(filter);
LinkStringFilter
用于判断链接中是否包含某个特定的字符串,可以用来过滤出指向某个特定网站的链接。
NodeFilter filter = new LinkStringFilter("www.baidu.com");
NodeList nodes = parser.extractAllNodesThatMatch(filter);
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
所有的Filter类都实现了org.htmlparser.NodeFilter接口。这个接口只有一个主要函数:
boolean accept (Node node);
各个子类分别实现这个函数,用于判断输入的Node是否符合这个Filter的过滤条件,如果符合,返回true,否则返回false。

相关文章推荐
- Java Json API:Gson使用简单入门
- java中CyclicBarrier简单入门使用
- Java -- POI -- 入门使用以及简单介绍
- Java Json API:Gson使用简单入门
- Java入门之使用记事本写Java程序及简单命令符
- java学习之旅27--键盘输入_Scanner类的使用_import简单入门
- JAVAWEB开发之Solr的入门——Solr的简介以及简单配置和使用、solrJ的使用、Solr数据同步插件
- Java枚举enum : 简单枚举与自定义枚举的入门使用
- MongoDB最简单的入门教程之三 使用Java代码往MongoDB里插入数据
- MySQL---数据库从入门走向大神系列(七)-Java访问数据库配置及简单使用方法execute
- Java 8 之 lambda 表达式简单使用入门实例代码
- Java 8 之 lambda 表达式简单使用入门实例代码。
- Java Json API:Gson使用简单入门
- java中CyclicBarrier简单入门使用
- [转]Java的开源项目:简单介绍Log4J的使用
- 使用 java 的反射 和 comparator 实现java bean 的简单排序
- javascript入门系列演示·函数的定义以及简单参数使用,调用函数
- NHibernate考察系列 02 使用入门 简单映射
- Java语言中包的简单使用
- Java Web Start简单入门步骤