Cocos2d-x Auto-batching 浅浅的”深入分析”
2014-06-03 08:08
363 查看
Auto-batching是Cocos2d-x3.0新增的特性,目的是为了取代SpriteBatchNode,完成渲染的批处理,提高绘制效率。
至于它有什么特点,可以看看官方文档,这里主要想探讨Auto-batching一些条件限制,简单地从源码方面去分析。
主要想分析的问题就是:为什么不连续创建的精灵(相同纹理、相同混合函数、没有对shader做什么处理)不能满足Auto-batching的要求?
=========== 以下是回忆,是我对Auto-batching产生疑惑的过程,可以忽略不看=========这得从前几天说起(小若:我们不是来听故事的!),我在更改之前SpriteBatchNode的教程,由于Cocos2d-x3.0新增了Auto-batching,于是就不得不把它也加进去。这一加,不对劲,越写越发现自己对Auto-batching的理解有误,在我的脑海中,只要精灵是使用同一个纹理、没有更改blendFunc、没有更改shader,那么就满足Auto-batching,会自动将这些精灵加入到同一个渲染批次里,优化渲染速度。 可我才刚准备写一个例子,却发现,不对!没有自动批处理。我当时做了这样一个实验,代码如下:

GL calls(渲染批次)竟然是16425次?这和想象中的完全不一样,不是应该是个位数么?这颠覆了我对Auto-batching的理解,于是,我又做了一些实验,发现了一些谬论,但结果是好的,因为我知道,我对Auto-batching的理解一直都是错的。关于我做的那几个实现,大家可以看看这个帖子:Cocos2d-x3.0 Auto-batching 三个小实验 由于是使用Windows平台做测试的,然后我的电脑配置比较高(小若:这是在炫耀的意思么?敢亮出你的配置吗?),所以帧率不能作为参考。总之,那个帖子得出的疑问是:为什么不连续创建的精灵(相同纹理、相同混合函数、没有对shader做什么处理)不能满足Auto-batching的要求? 一定是我对Auto-batching产生了误解,它应该还有一些我不知道的限制。好,既然知道我对Auto-batching产生了误解了,我当然就要再一次去看官方文档了,首先是中文文档:https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md反复看了好几次,不行,完全找不到能对这个问题有帮助的内容,但是我找不到英文文档。终于还是找到了,它并不是真正的文档,只是一些计划路线,但是对这个问题也很有帮助,标题是《Cocos2d (v.3.0) rendering pipeline roadmap》:https://docs.google.com/document/d/17zjC55vbP_PYTftTZEuvqXuMb9PbYNxRFu0EGTULPK8/edit#heading=h.dii2kgdfqgcp 对着这份文档看,以及调试源码,总算弄明白这个问题了。简单地说,要绘制的精灵(应该说是Node)先存放到队列里,然后由专门的渲染逻辑来渲染。对于队列中的精灵,一个个取出来(其实存取的不是精灵,这里先简单这么理解),发现材质一样的话(相同纹理、相同混合函数、相同shader),就放到一个批次里,如果发现不同的材质,则开始绘制之前连续的那些精灵(都在一个批次里)。然后继续取,继续判断材质。如果相同材质的精灵,中间间隔了不同材质的精灵,那也没法在同一个批次里渲染。这就是那个问题的答案:为什么不连续创建的精灵(相同纹理、相同混合函数、相同shader)不能满足Auto-batching的要求,因为只要中间有不同材质的渲染对象,就会中断,会先把之前连续的相同材质的对象进行批渲染。======================== 以上是回忆,回忆结束======================== 好了,上面是回忆的过程,并且已经有了大致的结论,现在正式来用代码解释。
笨木头花心贡献,啥?花心?不呢,是用心~转载请注明,原文地址: http://www.benmutou.com/blog/archives/1006文章来源: href="http://www.benmutou.com/" target=_blank>笨木头与游戏开发
(小若:够了!给我停!)(3)对每一个子节点调用draw函数(4)初始化QuadCommand对象,这就是渲染命令,会丢到渲染队列里(5)丢完QuadCommand就完事了,接着就交给渲染逻辑处理了。(7)是时候轮到渲染逻辑干活干活,遍历渲染命令队列,这时候会有一个变量,用来保存渲染命令里的材质ID,遍历过程中就拿当前渲染命令的材质ID和上一个的材质ID对比,如果发现是一样的,那就不进行渲染,保存一下所需的信息,继续下一个遍历。好,如果这时候发现当前材质ID和上一个材质ID不一样,那就开始渲染,这就算是一个渲染批次了。看官方的一张图就完全明白了:
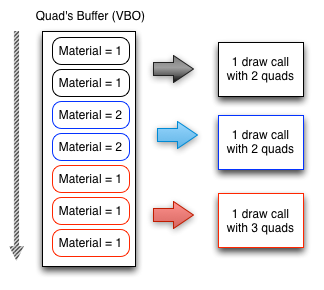
(8) 因此,如果我们创建了10个材质相同的对象,但是中间夹杂了一个不同材质的对象,假设它们的渲染命令在队列里的顺序是这样的:2个A,3个A,1个B,1个A,2个A,2个A。那么前面5个相同材质的对象A会进行一次渲染,中间的一个不同材质对象B进行一次渲染,后面的5个相同材质的对象A又进行一次渲染。一共会进行三次批渲染。(小若:突然发现,第6条哪去了啊?被你吃了吗) 这么一说,太含糊了,我们再来一次,用代码来罗列。

渲染批次是5,等等!为什么是5?为什么不是2?
PS(2014.06.18):今天偶然发现我这篇文章的部分内容被放到官方文档里了,有种受宠若惊的感觉~但很奇怪的是,文档里竟然没有注明出处,这个...就没关系了。为了避免以后大家反过来,以为我这篇文章是摘录了官方文档,特此说明。文档地址:https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md#rdhttp://cn.cocos2d-x.org/tutorial/show?id=784
至于它有什么特点,可以看看官方文档,这里主要想探讨Auto-batching一些条件限制,简单地从源码方面去分析。
主要想分析的问题就是:为什么不连续创建的精灵(相同纹理、相同混合函数、没有对shader做什么处理)不能满足Auto-batching的要求?
=========== 以下是回忆,是我对Auto-batching产生疑惑的过程,可以忽略不看=========这得从前几天说起(小若:我们不是来听故事的!),我在更改之前SpriteBatchNode的教程,由于Cocos2d-x3.0新增了Auto-batching,于是就不得不把它也加进去。这一加,不对劲,越写越发现自己对Auto-batching的理解有误,在我的脑海中,只要精灵是使用同一个纹理、没有更改blendFunc、没有更改shader,那么就满足Auto-batching,会自动将这些精灵加入到同一个渲染批次里,优化渲染速度。 可我才刚准备写一个例子,却发现,不对!没有自动批处理。我当时做了这样一个实验,代码如下:
/* 创建很多很多个精灵 */
for(inti = 0; i < 14100; i++)
{
Sprite* xiaoruo = Sprite::create("sprite0.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo);
xiaoruo = Sprite::create("sprite1.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo);
}我创建了两组精灵,分别使用sprite0.png和sprite1.png图片,每组14100个(小若:为什么非得是14100,为什么不能是14000?你让我们这些强迫症的人怎么办?!)。按照我对Auto-batching的误解,这两组精灵应该各自都能满足,都能分别作为一组批处理进行渲染。然而,运行结果如下:GL calls(渲染批次)竟然是16425次?这和想象中的完全不一样,不是应该是个位数么?这颠覆了我对Auto-batching的理解,于是,我又做了一些实验,发现了一些谬论,但结果是好的,因为我知道,我对Auto-batching的理解一直都是错的。关于我做的那几个实现,大家可以看看这个帖子:Cocos2d-x3.0 Auto-batching 三个小实验 由于是使用Windows平台做测试的,然后我的电脑配置比较高(小若:这是在炫耀的意思么?敢亮出你的配置吗?),所以帧率不能作为参考。总之,那个帖子得出的疑问是:为什么不连续创建的精灵(相同纹理、相同混合函数、没有对shader做什么处理)不能满足Auto-batching的要求? 一定是我对Auto-batching产生了误解,它应该还有一些我不知道的限制。好,既然知道我对Auto-batching产生了误解了,我当然就要再一次去看官方文档了,首先是中文文档:https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md反复看了好几次,不行,完全找不到能对这个问题有帮助的内容,但是我找不到英文文档。终于还是找到了,它并不是真正的文档,只是一些计划路线,但是对这个问题也很有帮助,标题是《Cocos2d (v.3.0) rendering pipeline roadmap》:https://docs.google.com/document/d/17zjC55vbP_PYTftTZEuvqXuMb9PbYNxRFu0EGTULPK8/edit#heading=h.dii2kgdfqgcp 对着这份文档看,以及调试源码,总算弄明白这个问题了。简单地说,要绘制的精灵(应该说是Node)先存放到队列里,然后由专门的渲染逻辑来渲染。对于队列中的精灵,一个个取出来(其实存取的不是精灵,这里先简单这么理解),发现材质一样的话(相同纹理、相同混合函数、相同shader),就放到一个批次里,如果发现不同的材质,则开始绘制之前连续的那些精灵(都在一个批次里)。然后继续取,继续判断材质。如果相同材质的精灵,中间间隔了不同材质的精灵,那也没法在同一个批次里渲染。这就是那个问题的答案:为什么不连续创建的精灵(相同纹理、相同混合函数、相同shader)不能满足Auto-batching的要求,因为只要中间有不同材质的渲染对象,就会中断,会先把之前连续的相同材质的对象进行批渲染。======================== 以上是回忆,回忆结束======================== 好了,上面是回忆的过程,并且已经有了大致的结论,现在正式来用代码解释。
笨木头花心贡献,啥?花心?不呢,是用心~转载请注明,原文地址: http://www.benmutou.com/blog/archives/1006文章来源:
渲染流程
现在,一个渲染流程是这样的:(1)drawScene开始绘制场景(2)遍历场景的子节点,调用visit函数,递归遍历子节点的子节点,以及子节点的子节点的子节点,以及…(小若:够了!给我停!)(3)对每一个子节点调用draw函数(4)初始化QuadCommand对象,这就是渲染命令,会丢到渲染队列里(5)丢完QuadCommand就完事了,接着就交给渲染逻辑处理了。(7)是时候轮到渲染逻辑干活干活,遍历渲染命令队列,这时候会有一个变量,用来保存渲染命令里的材质ID,遍历过程中就拿当前渲染命令的材质ID和上一个的材质ID对比,如果发现是一样的,那就不进行渲染,保存一下所需的信息,继续下一个遍历。好,如果这时候发现当前材质ID和上一个材质ID不一样,那就开始渲染,这就算是一个渲染批次了。看官方的一张图就完全明白了:
(8) 因此,如果我们创建了10个材质相同的对象,但是中间夹杂了一个不同材质的对象,假设它们的渲染命令在队列里的顺序是这样的:2个A,3个A,1个B,1个A,2个A,2个A。那么前面5个相同材质的对象A会进行一次渲染,中间的一个不同材质对象B进行一次渲染,后面的5个相同材质的对象A又进行一次渲染。一共会进行三次批渲染。(小若:突然发现,第6条哪去了啊?被你吃了吗) 这么一说,太含糊了,我们再来一次,用代码来罗列。
1. drawScene开始绘制场景
首先是开始,简单点,看代码:void DisplayLinkDirector::mainLoop()
{
if (_purgeDirectorInNextLoop)
{
_purgeDirectorInNextLoop = false;
purgeDirector();
}
else if (! _invalid)
{
drawScene();
// release the objects
PoolManager::getInstance()->getCurrentPool()->clear();
}
}调用drawScene函数,开始绘制场景 2.遍历场景的子节点
接下来,drawScene函数里有一小段代码(我就不贴全部了,多吓人):if (_runningScene)
{
_runningScene->visit(_renderer, identity, false);
_eventDispatcher->dispatchEvent(_eventAfterVisit);
}没错,调用visit函数遍历场景的所有子节点(包括子节点的子节点,一直递归),然后做一些操作。 3.对每一个子节点调用draw函数
当然,我们最终关心的是,调用这些子节点的draw函数。void Sprite::draw(Renderer *renderer, const kmMat4 &transform, bool transformUpdated)
{
// Don't do calculate the culling if the transform was not updated
_insideBounds = transformUpdated ? isInsideBounds() : _insideBounds;
if(_insideBounds)
{
_quadCommand.init(_globalZOrder, _texture->getName(), _shaderProgram, _blendFunc, &_quad, 1, transform);
renderer->addCommand(&_quadCommand);
}
}我删掉了一些吓人的代码。 4.初始化QuadCommand对象,这就是渲染命令
上面的代码就是重点了,初始化_quadCommand对象,这就是QuadCommand,渲染命令。 其实渲染命令不仅仅只有QuadCommand,还有其他的,比如CustomCommand,自定义渲染命令,顾名思义,就是我们用户自己定制的命令,由于我没有使用过,就不介绍了。然后,接着就调用addCommand函数将渲染命令加入队列。 这里有一点,也很重要,由于渲染命令有好几种,所以addCommand的时候,其实是会根据不同的命令类型把渲染命令添加到不同的队列。本文只想针对QuadCommand,所以就忽略这一点,假设我们的所有命令都是QuadCommand。5.丢完QuadCommand就完事了
draw函数执行完,就轮到渲染逻辑干活了。6.开始渲染
轮到渲染逻辑干活了,之前介绍了,渲染命令有好几种,如果我没有理解错误的话,只有QuadCommand才能参与自动批处理,因此,这里会对渲染命令进行筛选,发现是QuadCommand类型的命令就保存到一个队列里。如代码:if(commandType == RenderCommand::Type::QUAD_COMMAND)
{
auto cmd = static_cast<QuadCommand*>(command);
_batchedQuadCommands.push_back(cmd);
}
else if(commandType == RenderCommand::Type::CUSTOM_COMMAND)
{}
else if(commandType == RenderCommand::Type::BATCH_COMMAND)
{}
else if(commandType == RenderCommand::Type::GROUP_COMMAND)
{}
else
{}为了避免大家睡着了,我把很多重要的代码删了,我们只要关注_batchedQuadCommands.push_back(cmd);。_batchedQuadCommands就是QuadCommand命令队列了。 接着,调用drawBatchedQuads函数遍历QuadCommand命令队列: for(const auto& cmd : _batchedQuadCommands)
{
if(_lastMaterialID != cmd->getMaterialID())
{
//Draw quads
if(quadsToDraw > 0)
{
glDrawElements(GL_TRIANGLES, (GLsizei) quadsToDraw*6, GL_UNSIGNED_SHORT, (GLvoid*) (startQuad*6*sizeof(_indices[0])) );
_drawnBatches++;
_drawnVertices += quadsToDraw*6;
startQuad += quadsToDraw;
quadsToDraw = 0;
}
//Use new material
cmd->useMaterial();
_lastMaterialID = cmd->getMaterialID();
}
quadsToDraw += cmd->getQuadCount();
}又为了避免大家睡着了,我删了很多重要的代码。(小若:我说,重要的代码随便删除真的好吗?)大家睁大耳朵鼻子什么的看看,_lastMaterialID是重点,当发现当前遍历的渲染命令的材质ID和_lastMaterialID不一样时,就会开始进行渲染,然后记录新的材质ID,继续遍历。这就是我们所说的,只有连续的相同材质ID的对象才会被放到同一个批次里进行渲染,如果不连续,那么材质ID再怎么相同也没有办法了。对了,_drawnBatches变量就是我们左下角经常看到的GL calls的数字了~ 7. 为什么必须要相同纹理、相同混合函数、相同shader?
要满足Auto-batching,就必须有这三个条件,这是为什么呢?我们回到之前的代码,在调用节点的draw函数时,调用了QuadCommand的init函数:_quadCommand.init(_globalZOrder, _texture->getName(), _shaderProgram, _blendFunc, &_quad, 1, transform);这个init函数就是关键:
void QuadCommand::init(float globalOrder, GLuint textureID, GLProgram* shader, BlendFunc blendType, V3F_C4B_T2F_Quad* quad, ssize_t quadCount, const kmMat4 &mv)
{
_globalOrder = globalOrder;
_textureID = textureID;
_blendType = blendType;
_shader = shader;
_quadsCount = quadCount;
_quads = quad;
_mv = mv;
_dirty = true;
generateMaterialID();
}init函数里最后调用了generateMaterialID函数,这个函数就是关键。(小若:够了你,什么都是关键,关键个毛线啊) void QuadCommand::generateMaterialID()
{
if (_dirty)
{
//Generate Material ID
//TODO fix blend id generation
int blendID = 0;
if(_blendType == BlendFunc::DISABLE)
{
blendID = 0;
}
else if(_blendType == BlendFunc::ALPHA_PREMULTIPLIED)
{
blendID = 1;
}
else if(_blendType == BlendFunc::ALPHA_NON_PREMULTIPLIED)
{
blendID = 2;
}
else if(_blendType == BlendFunc::ADDITIVE)
{
blendID = 3;
}
else
{
blendID = 4;
}
// convert program id, texture id and blend id into byte array
char byteArray[12];
convertIntToByteArray(_shader->getProgram(), byteArray);
convertIntToByteArray(blendID, byteArray + 4);
convertIntToByteArray(_textureID, byteArray + 8);
_materialID = XXH32(byteArray, 12, 0);
_dirty = false;
}
}看到没?~我们的材质ID(_materialID)最终是要由shader(_shader->getProgram())、混合函数ID(blendID)、纹理ID(_textureID)组成的啊喂!所以这三样东西如果有谁不一样的话,那就无法生成相同的材质ID,也就无法在同一个批次里进行渲染了。 _blendType就是我们的BlendFunc混合函数,注意一下,这里所说的相同的混合函数,并不是指要完全相同的值, 其实只是相同类型,看看if else的那几个判断就知道了,最后需要的只是blendID这个值。当然,至于为什么要这样生成材质ID,我就没有去深究了,我只是个写游戏的,引擎底层,还是交给Cocos2d-x团队的人吧(邪恶)。
8. 怎样才能让相同材质的对象的渲染命令连续排列?
不连续的渲染命令,即使材质ID相同也没有用,那,我们应该怎么让这些家伙连续起来呢? 这个问题好办,还记得场景绘制的时候会遍历所有子节点吧?在遍历子节点之前,其实还偷偷做了一件事情,那就是,调用sortAllChildren();函数对子节点进行排序,对比的规则是:bool nodeComparisonLess(Node* n1, Node* n2)
{
return( n1->getLocalZOrder() < n2->getLocalZOrder() ||
( n1->getLocalZOrder() == n2->getLocalZOrder() && n1->getOrderOfArrival() < n2->getOrderOfArrival() )
);好吧,我们不要管代码了(小若:那你还贴个毛线啊,很吓人的好不好)。总之,排序的规则是按照子节点的localZOrder和orderOfArrival进行的,orderOfArrival是用于localZOrder相同的情况下,进一步区分渲染顺序的(就是谁在上面谁在下面,额,请不要想歪)。那么,我们只要调整节点的zOrder就能改变节点的遍历顺序,于是,节点的QuadCommand添加顺序也就被改变了。 但是,注意,但是来了,除了场景子节点会进行排序之外,在渲染逻辑里,渲染命令队列也会进行一次排序: void Renderer::render()
{
if (_glViewAssigned)
{
//1. Sort render commands based on ID
for (auto &renderqueue : _renderGroups)
{
renderqueue.sort();
}
}当然,我删了很多重要的代码renderqueue是RenderQueue对象,就是用于保存渲染命令的队列,它的sort函数是这样的: void RenderQueue::sort()
{
// Don't sort _queue0, it already comes sorted
std::sort(std::begin(_queueNegZ), std::end(_queueNegZ), compareRenderCommand);
std::sort(std::begin(_queuePosZ), std::end(_queuePosZ), compareRenderCommand);
}
bool compareRenderCommand(RenderCommand* a, RenderCommand* b)
{
return a->getGlobalOrder() < b->getGlobalOrder();
}
没错,渲染队列会根据节点的globalOrder再一次进行排序,默认的globalOrder当然是0了,也就是排不排序结果都一样。
这涉及到localZOrder和globalOrder的概念,这就帮star特做个广告吧,看看他的帖子:
Cocos2dx 3.0 过渡篇(二十九)globalZOrder()与localZOrder() 总之,结论就是,如果没有对节点的globalOrder进行设置,那就只需要调整节点的localZOrder,便可以实现对渲染命令的排序顺序进行控制。来看下面的代码,一开始贴过的: /* 创建很多很多个精灵 */
for(inti = 0; i < 14100; i++)
{
Sprite* xiaoruo = Sprite::create("sprite0.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo);
xiaoruo = Sprite::create("sprite1.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo);
}这样创建的精灵肯定就没法连续了,因为sprite0.png的精灵和sprite1.png的精灵是不断间隔着创建的,没有连续。而且它们默认的localZOrder都是0,所以排序不起效。 那么,稍微改改就好了,如下: /* 创建很多很多个精灵 */
for(inti = 0; i < 14100; i++)
{
Sprite* xiaoruo = Sprite::create("sprite0.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo, 1);
xiaoruo = Sprite::create("sprite1.png");
xiaoruo->setPosition(Point(CCRANDOM_0_1() * 480, 120 + CCRANDOM_0_1() * 300));
this->addChild(xiaoruo, 2);
}只是给精灵分别指定了localZOrder值,这样在排序的时候sprite0.png的精灵就会在一起,同样,sprite1.png的精灵也会在一起。运行结果,来一个很壮观的截图:渲染批次是5,等等!为什么是5?为什么不是2?
9. 渲染队列存储上限
继续回答刚刚的问题,图中的渲染批次是5,为什么是5?为什么不是2?首先,即使我一个精灵也不创建,渲染批次也至少是1。那么,我创建了两组材质ID相同的精灵,理论上GL calls应该是3,为什么是5? 这个也很简单,因为渲染队列最大只存放10922个渲染命令,注意,是“只存放”而不是“只能存放”,这个只是在代码里做的限制。当渲染队列(指的是Render类的成员变量:std::vector<QuadCommand*> _batchedQuadCommands; ,之前有讲到)存放的渲染命令大于10922时,就会自动进行一次渲染操作,把队列里的渲染命令处理掉。 因此,我创建了2组精灵,每组14100个,已经超过了10922的范围,所以,即使这2组精灵各自都是相同的材质,但也不得不被分成2次进行渲染,于是,这2组精灵共进行了4次渲染操作。再加上GL calls默认就有1(为什么默认会有一次,我就没有去研究了),那么,就是5次了。 话又说回来了,谁家的游戏那么夸张,要创建28200个精灵啊!这样那些跑分8000左右的手机怎么办啊,我在自己手机里试过了,帧率是60!没错,是60,已经太慢了无法正确计算了。因为每一帧的渲染消耗的时间是2秒多!一帧就消耗2秒多,太刺激了。嗯,跑题了。 结束语好了,关于Auto-batching的探索之旅总算是结束了。我对OpenGL的东西还真不太懂,所以,有可能在研究代码的时候有一些东西被我忽略了,或者误解了,如果文章有错误的地方,那…你来打我啊(别,开玩笑的)。PS(2014.06.18):今天偶然发现我这篇文章的部分内容被放到官方文档里了,有种受宠若惊的感觉~但很奇怪的是,文档里竟然没有注明出处,这个...就没关系了。为了避免以后大家反过来,以为我这篇文章是摘录了官方文档,特此说明。文档地址:https://github.com/chukong/cocos-docs/blob/master/manual/framework/native/v3/auto-batching/zh.md#rdhttp://cn.cocos2d-x.org/tutorial/show?id=784

相关文章推荐
- Cocos2d-x Auto-batching 浅浅的”深入分析”
- Cocos2d-x Auto-batching 浅浅的”深入分析”
- cocos2d-x Auto-batching 浅浅的”深入分析”
- Cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x 的CCObject与autorelease 之深入分析(转载)
- 转载自笨木头的Cocos2d-x Auto-batching分析
- cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x 的CCObject与autorelease 之深入分析
- Cocos2d-x2.0 进度动画 深入分析
- [ IOS-Cocos2d-x 游戏开发] - Lua 开发之一(“HelloLua” 深入分析)
- Cocos2d-x 的“HelloWorld” 深入分析
- Cocos2d-x中的CurlTest深入分析
- Cocos2d-x 2.0 按键加速处理深入分析
- Cocos2d-x2.0 粒子系统深入分析三部曲(一)
- Cocos2d-x之LUA脚本引擎深入分析
- Cocos2d-x 2.0 拖尾效果深入分析
- Cocos2d-x 2.0 粒子系统深入分析三部曲(三)