HMM学习最佳范例七:前向-后向算法5
2014-05-29 13:29
375 查看
七、前向-后向算法(Forward-backward algorithm)
上一节我们定义了两个变量及相应的期望值,本节我们利用这两个变量及其期望值来重新估计隐马尔科夫模型(HMM)的参数pi,A及B:

如果我们定义当前的HMM模型为
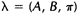
,那么可以利用该模型计算上面三个式子的右端;我们再定义重新估计的HMM模型为
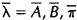
,那么上面三个式子的左端就是重估的HMM模型参数。Baum及他的同事在70年代证明了
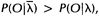
因此如果我们迭代地的计算上面三个式子,由此不断地重新估计HMM的参数,那么在多次迭代后可以得到的HMM模型的一个最大似然估计。不过需要注意的是,前向-后向算法所得的这个结果(最大似然估计)是一个局部最优解。
关于前向-后向算法和EM算法的具体关系的解释,大家可以参考HMM经典论文《A tutorial on Hidden Markov Models and selected applications in speech recognition》,这里就不详述了。下面我们给出UMDHMM中的前向-后向算法示例,这个算法比较复杂,这里只取主函数,其中所引用的函数大家如果感兴趣的话可以自行参考UMDHMM。
前向-后向算法程序示例如下(在baum.c中):
前向-后向算法就到此为止了。
未完待续:总结
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:http://www.52nlp.cn/hmm-learn-best-practices-seven-forward-backward-algorithm-5
上一节我们定义了两个变量及相应的期望值,本节我们利用这两个变量及其期望值来重新估计隐马尔科夫模型(HMM)的参数pi,A及B:
如果我们定义当前的HMM模型为
,那么可以利用该模型计算上面三个式子的右端;我们再定义重新估计的HMM模型为
,那么上面三个式子的左端就是重估的HMM模型参数。Baum及他的同事在70年代证明了
因此如果我们迭代地的计算上面三个式子,由此不断地重新估计HMM的参数,那么在多次迭代后可以得到的HMM模型的一个最大似然估计。不过需要注意的是,前向-后向算法所得的这个结果(最大似然估计)是一个局部最优解。
关于前向-后向算法和EM算法的具体关系的解释,大家可以参考HMM经典论文《A tutorial on Hidden Markov Models and selected applications in speech recognition》,这里就不详述了。下面我们给出UMDHMM中的前向-后向算法示例,这个算法比较复杂,这里只取主函数,其中所引用的函数大家如果感兴趣的话可以自行参考UMDHMM。
前向-后向算法程序示例如下(在baum.c中):
void BaumWelch(HMM *phmm, int T, int *O, double **alpha, double **beta, double **gamma, int *pniter, double *plogprobinit, double *plogprobfinal)
{
int i, j, k;
int t, l = 0;
double logprobf, logprobb, threshold;
double numeratorA, denominatorA;
double numeratorB, denominatorB;
double ***xi, *scale;
double delta, deltaprev, logprobprev;
deltaprev = 10e-70;
xi = AllocXi(T, phmm->N);
scale = dvector(1, T);
ForwardWithScale(phmm, T, O, alpha, scale, &logprobf);
*plogprobinit = logprobf; /* log P(O |intial model) */
BackwardWithScale(phmm, T, O, beta, scale, &logprobb);
ComputeGamma(phmm, T, alpha, beta, gamma);
ComputeXi(phmm, T, O, alpha, beta, xi);
logprobprev = logprobf;
do
{
/* reestimate frequency of state i in time t=1 */
for (i = 1; i <= phmm->N; i++)
phmm->pi[i] = .001 + .999*gamma[1][i];
/* reestimate transition matrix and symbol prob in
each state */
for (i = 1; i <= phmm->N; i++)
{
denominatorA = 0.0;
for (t = 1; t <= T - 1; t++)
denominatorA += gamma[t][i];
for (j = 1; j <= phmm->N; j++)
{
numeratorA = 0.0;
for (t = 1; t <= T - 1; t++)
numeratorA += xi[t][i][j];
phmm->A[i][j] = .001 +
.999*numeratorA/denominatorA;
}
denominatorB = denominatorA + gamma[T][i];
for (k = 1; k <= phmm->M; k++)
{
numeratorB = 0.0;
for (t = 1; t <= T; t++)
{
if (O[t] == k)
numeratorB += gamma[t][i];
}
phmm->B[i][k] = .001 +
.999*numeratorB/denominatorB;
}
}
ForwardWithScale(phmm, T, O, alpha, scale, &logprobf);
BackwardWithScale(phmm, T, O, beta, scale, &logprobb);
ComputeGamma(phmm, T, alpha, beta, gamma);
ComputeXi(phmm, T, O, alpha, beta, xi);
/* compute difference between log probability of
two iterations */
delta = logprobf - logprobprev;
logprobprev = logprobf;
l++;
}
while (delta > DELTA); /* if log probability does not
change much, exit */
*pniter = l;
*plogprobfinal = logprobf; /* log P(O|estimated model) */
FreeXi(xi, T, phmm->N);
free_dvector(scale, 1, T);
}前向-后向算法就到此为止了。
未完待续:总结
注:原创文章,转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:http://www.52nlp.cn/hmm-learn-best-practices-seven-forward-backward-algorithm-5

相关文章推荐
- HMM学习最佳范例五:前向算法2
- HMM学习最佳范例五:前向算法4
- HMM学习最佳范例五:前向算法5
- HMM学习最佳范例七:前向-后向算法2
- HMM学习最佳范例七:前向-后向算法
- HMM学习最佳范例五:前向算法2
- HMM学习最佳范例: 前向算法(Forward Algorithm)
- HMM学习最佳范例七:前向-后向算法
- HMM学习最佳范例七:前向-后向算法4
- HMM学习最佳范例五:前向算法3
- 【转】HMM学习最佳范例五:前向算法1 .
- HMM学习最佳范例七:前向-后向算法1
- HMM学习最佳范例五:前向算法4
- HMM学习最佳范例五:前向算法3
- HMM学习最佳范例:前向-后向算法(Forward-backward algorithm)
- HMM学习最佳范例七:前向-后向算法3
- HMM学习最佳范例五:前向算法
- HMM学习最佳范例五:前向算法1
- HMM学习最佳范例五:前向算法1
- HMM学习最佳范例六:维特比算法2