SMO序列最小最优化算法
2014-05-25 19:55
162 查看
首先回顾一下SVM模型的数学表达,即svm的对偶问题:
mina12∑i=1N∑j=1NaiajyiyjK(xi,xj)−∑i=1Nais.t.∑i=1Naiyi=00≤ai≤C,i=1,2,⋅⋅⋅,N
选择一个 a∗ 的正分量 0<a∗j<C ,
计算(或者通过所有解求平均值):
b∗=yj−∑i=1Na∗iyiK(xi⋅xj)
决策函数为
f(x)=sign(∑i=1Na∗iyiK(xi,xj)+b∗)
svm的学习,就是通过训练数据计算出a∗和b∗,然后通过决策函数判定xj的分类。其中a∗是一个向量,长度与训练数据的样本数相同,如果训练数据很大,那么这个向量会很长,不过绝大部分的分量值都是0,只有支持向量的对应的分量值大于0
。
SMO是一种启发式算法,其基本思想是:如果所有变量的解都满足了此最优化问题的KKT条件,那么这个最优化问题的解就得到了。否则,选择两个变量,固定其它变量,针对这两个变量构建一个二次规划问题,然后关于这个二次规划的问题的解就更接近原始的二次归还问题的解,因为这个解使得需要优化的问题的函数值更小。
翻译一下:对于svm我们要求解a∗,如果 a∗ 的所有分量满足svm对偶问题的KKT条件,那么这个问题的解就求出来了,我们svm模型学习也就完成了。如果没有满足KKT,那么我们就在 a∗ 中找两个分量 ai 和 aj,其中 ai 是违反KKT条件最严重的分量,通过计算,使得 ai 和 aj 满足KKT条件,直到a∗ 的所有分量都满足KKT条件。而且这个计算过程是收敛的,因为每次计算出来的新的两个分量,使得对偶问题中要优化的目标函数(就是min对应的那个函数)值更小。至于为什么是收敛的,是因为,每次求解的那两个分量,是要优化问题在这两个分量上的极小值,所以每一次优化,都会使目标函数比上一次的优化结果的值变小。
我们来看看KKT条件。
上面的问题,是通过svm的原始问题,构造拉格朗日函数,并通过对偶换算得出的对偶问题。与对偶问题等价的是对偶问题的KKT条件,参考《统计学习方法》的附录C的定理C.3。换句话说,就是只要找到对应的a∗满足了下列KKT条件,那么原始问题和对偶问题就解决了。
SVM的对偶问题对应的KKT条件为:
ai=0⇔yig(xi)≥10<ai<C⇔yig(xi)=1ai=C⇔yig(xi)≤1
其中:
g(x)=∑i=1NaiyiK(xi,xj)+b
因为计算机在计算的时候是有精度范围的,所以我们引入一个计算精度值ε,
⎧⎩⎨⎪⎪ai=0⇔yig(xi)≥1−ε0<ai<C⇔1−ε≤yig(xi)≤1+εai=C⇔yig(xi)≤1+ε⎫⎭⎬⎪⎪⇒{ai<C⇔1−ε≤yig(xi)0<ai⇔yig(xi)≤1+ε}
同时由于yi=±1,所以yi∗yi=1,上面的公式可以换算为
ai<C⇔−ε≤yi(g(xi)−yi)0<ai⇔yi(g(xi)−yi)≤+ε
定义:
Ei=g(xi)−yi
其中,g(x)其实就是决策函数,所以Ei可以认为是对输入的xi的预测值与真实输出yi之差。
上面的公式就可以换算为,即KKT条件可以表示为:
ai<C⇔−ε≤yiEi0<ai⇔yiEi≤+ε
那么相应的违规KKT条件的分量应该满足下列不等式:
Against KKT:
ai<C⇔−ε>yiEi0<ai⇔yiEi>+ε
其实上面的推导过程不必关心,只需要应用违犯KKT条件的公式就可以了。
输入:训练数据集 T={(x_1,y_1),(x_2,y_2),⋅⋅⋅,(x_N,y_N)}
其中xi∈χ∈Rn,yi∈{−1,+1},i=1,2,⋅⋅⋅,N,精度ε。
输出:近似解a^
算法描述:
(1) 取初始值a(0)=0,令K=0
(2) 选取优化变量 a(k)1 , a(k)2 ,
针对优化问题,求得最优解 a(k+1)1 , a(k+1)2 更新 a(k) 为 a(k+1) 。
(3) 在精度条件范围内是否满足停机条件,即是否有变量违反KKT条件,如果违反了,则令k=k+1,跳转(2),否则(4)。
(4) 求得近似解a^=a(k+1)
上面算法的(1)、(3)、(4)步都不难理解,其中第(3)步中,是否违反KKT条件,对于a(k)的每个分量按照上一节的违反KKT条件的公式进行验算即可。难于理解的是第(2)步,下面就重点解释优化变量选取和如何更新选取变量。
变量选取分为两步,第一步是选取违反KKT条件最严重的ai,第二步是根据已经选取的第一个变量,选择优化程度最大的第二个变量。
违反KKT条件最严重的变量可以按照这样的规则选取,首先看0<ai<C的那些分量中,是否有违反KKT条件的,如果有,则选取yig(xi)最小的那个做为a1。如果没有则遍历所有的样本点,在违反KKT条件的分量中选取yig(xi)最小的做为a1。
当选择了a1后,如果a1对应的E1为正,选择Ei最小的那个分量最为a2,如果E1为负,选择Ei最大的那个分量最为a2,这是因为anew2依赖于|E1−E2|(后面的公式会讲到)。
如果选择的a2,不能满足下降的最小步长,那么就遍历所有的支持向量点做为a2进行试用,如果仍然都不能满足下降的最小步长,那么就遍历所有的样本点做为a2试用。如果还算是不能满足下降的最小步长,那么就重新选择a1。
首先计算出来的新值必须满足约束条件∑i=1Naiyi=0 ,那么求出来的anew2需要满足下列条件(具体推导见《统计学习方法》的7.4.1):
L≤anew2≤HL=max(0,aold2−aold1),H=min(C,C+aold2−aold1),y1≠y2L=max(0,aold2+aold1−C),H=min(C,aold2+aold1),y1=y2
未经过裁剪的a2的解为:
anew,unc2=aold2+y2(E1−E2)ηη=K11+K22−2K12
裁剪后的解为
anew2=⎧⎩⎨⎪⎪H,anew,unc2>Hanew,unc2,L≤anew,unc2≤HL,anew,unc2<L
第一个变量的解为
anew1=aold1+y1y2(aold2−anew2)
还需要更新b:
bnew1=−E1−y1K11(anew1−aold1)−y2K21(anew2−aold2)+boldbnew2=−E2−y1K12(anew1−aold1)−y2K22(anew2−aold2)+bold
在更新b时,如果有0<anew1<C,
则bnew=bnew1,如果有0<anew2<C,
则 bnew=bnew2,
否则bnew=bnew1+bnew22。
由于缓存了Ei,所以需要计算新的Ei:
Enewi=∑j=1NyjajK(xi,xj)+bnew−yi
我实现了一个简单的基于SMO的线性svm,是一个python脚本。实现的过程中,变量的选取并未严格按照算法讲的方法选取,选择了一个简单的选取方法。 一次迭代中,遍历所有的ai,如果ai违反了KKT条件,那么就将它做为第一个变量,然后再遍历所有的ai,依次做为第二个变量,如果第二个变量有足够的下降,那么就更新两个变量。如果没有,就不更新。
实现的python脚本如下:
使用python实现的基于SMO的SVM (smo.py)download
脚本使用的训练数据可以下载SMO实现的代码的svm.train文件,或者使用blog_linear.py,通过改变变量
这个smo.py脚本是一个线性的svm,替换掉脚本中
下面这两张图片是用训练数据训练的结果。这一张是样本能完全分离开的:
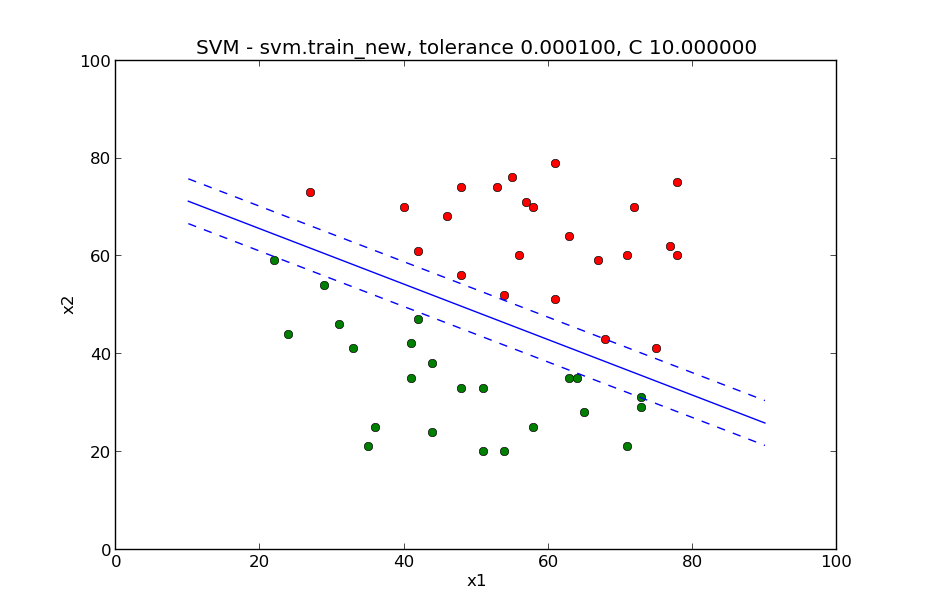
这一张是样本不能完全分离开的:
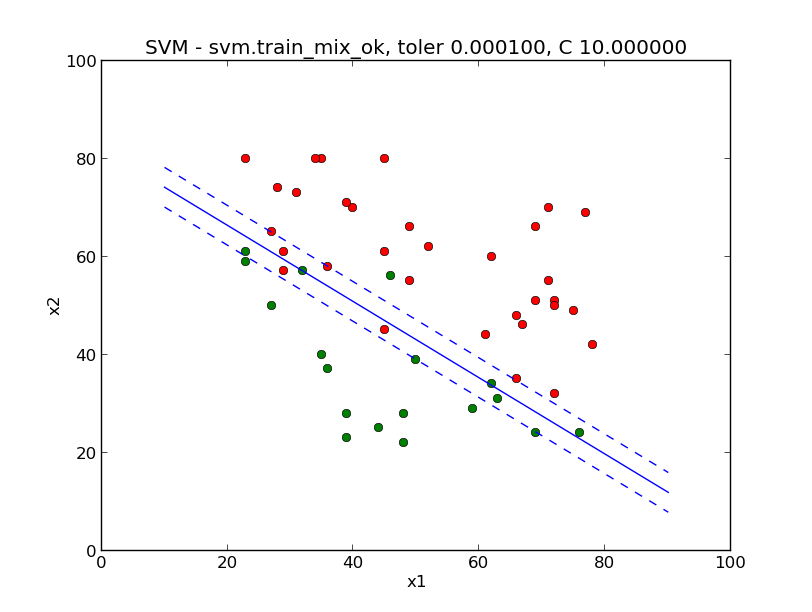
以上就是如何实现SMO的全部内容。之前的一个同事实现了一个简单的识别手写数字ocr,下一章,我们也来用svm实现一个简单的识别数字的ocr吧。
mina12∑i=1N∑j=1NaiajyiyjK(xi,xj)−∑i=1Nais.t.∑i=1Naiyi=00≤ai≤C,i=1,2,⋅⋅⋅,N
选择一个 a∗ 的正分量 0<a∗j<C ,
计算(或者通过所有解求平均值):
b∗=yj−∑i=1Na∗iyiK(xi⋅xj)
决策函数为
f(x)=sign(∑i=1Na∗iyiK(xi,xj)+b∗)
svm的学习,就是通过训练数据计算出a∗和b∗,然后通过决策函数判定xj的分类。其中a∗是一个向量,长度与训练数据的样本数相同,如果训练数据很大,那么这个向量会很长,不过绝大部分的分量值都是0,只有支持向量的对应的分量值大于0
。
SMO是一种启发式算法,其基本思想是:如果所有变量的解都满足了此最优化问题的KKT条件,那么这个最优化问题的解就得到了。否则,选择两个变量,固定其它变量,针对这两个变量构建一个二次规划问题,然后关于这个二次规划的问题的解就更接近原始的二次归还问题的解,因为这个解使得需要优化的问题的函数值更小。
翻译一下:对于svm我们要求解a∗,如果 a∗ 的所有分量满足svm对偶问题的KKT条件,那么这个问题的解就求出来了,我们svm模型学习也就完成了。如果没有满足KKT,那么我们就在 a∗ 中找两个分量 ai 和 aj,其中 ai 是违反KKT条件最严重的分量,通过计算,使得 ai 和 aj 满足KKT条件,直到a∗ 的所有分量都满足KKT条件。而且这个计算过程是收敛的,因为每次计算出来的新的两个分量,使得对偶问题中要优化的目标函数(就是min对应的那个函数)值更小。至于为什么是收敛的,是因为,每次求解的那两个分量,是要优化问题在这两个分量上的极小值,所以每一次优化,都会使目标函数比上一次的优化结果的值变小。
我们来看看KKT条件。
KKT
上面的问题,是通过svm的原始问题,构造拉格朗日函数,并通过对偶换算得出的对偶问题。与对偶问题等价的是对偶问题的KKT条件,参考《统计学习方法》的附录C的定理C.3。换句话说,就是只要找到对应的a∗满足了下列KKT条件,那么原始问题和对偶问题就解决了。SVM的对偶问题对应的KKT条件为:
ai=0⇔yig(xi)≥10<ai<C⇔yig(xi)=1ai=C⇔yig(xi)≤1
其中:
g(x)=∑i=1NaiyiK(xi,xj)+b
因为计算机在计算的时候是有精度范围的,所以我们引入一个计算精度值ε,
⎧⎩⎨⎪⎪ai=0⇔yig(xi)≥1−ε0<ai<C⇔1−ε≤yig(xi)≤1+εai=C⇔yig(xi)≤1+ε⎫⎭⎬⎪⎪⇒{ai<C⇔1−ε≤yig(xi)0<ai⇔yig(xi)≤1+ε}
同时由于yi=±1,所以yi∗yi=1,上面的公式可以换算为
ai<C⇔−ε≤yi(g(xi)−yi)0<ai⇔yi(g(xi)−yi)≤+ε
定义:
Ei=g(xi)−yi
其中,g(x)其实就是决策函数,所以Ei可以认为是对输入的xi的预测值与真实输出yi之差。
上面的公式就可以换算为,即KKT条件可以表示为:
ai<C⇔−ε≤yiEi0<ai⇔yiEi≤+ε
那么相应的违规KKT条件的分量应该满足下列不等式:
Against KKT:
ai<C⇔−ε>yiEi0<ai⇔yiEi>+ε
其实上面的推导过程不必关心,只需要应用违犯KKT条件的公式就可以了。
SMO算法描述
输入:训练数据集 T={(x_1,y_1),(x_2,y_2),⋅⋅⋅,(x_N,y_N)}其中xi∈χ∈Rn,yi∈{−1,+1},i=1,2,⋅⋅⋅,N,精度ε。
输出:近似解a^
算法描述:
(1) 取初始值a(0)=0,令K=0
(2) 选取优化变量 a(k)1 , a(k)2 ,
针对优化问题,求得最优解 a(k+1)1 , a(k+1)2 更新 a(k) 为 a(k+1) 。
(3) 在精度条件范围内是否满足停机条件,即是否有变量违反KKT条件,如果违反了,则令k=k+1,跳转(2),否则(4)。
(4) 求得近似解a^=a(k+1)
上面算法的(1)、(3)、(4)步都不难理解,其中第(3)步中,是否违反KKT条件,对于a(k)的每个分量按照上一节的违反KKT条件的公式进行验算即可。难于理解的是第(2)步,下面就重点解释优化变量选取和如何更新选取变量。
变量选取
变量选取分为两步,第一步是选取违反KKT条件最严重的ai,第二步是根据已经选取的第一个变量,选择优化程度最大的第二个变量。违反KKT条件最严重的变量可以按照这样的规则选取,首先看0<ai<C的那些分量中,是否有违反KKT条件的,如果有,则选取yig(xi)最小的那个做为a1。如果没有则遍历所有的样本点,在违反KKT条件的分量中选取yig(xi)最小的做为a1。
当选择了a1后,如果a1对应的E1为正,选择Ei最小的那个分量最为a2,如果E1为负,选择Ei最大的那个分量最为a2,这是因为anew2依赖于|E1−E2|(后面的公式会讲到)。
如果选择的a2,不能满足下降的最小步长,那么就遍历所有的支持向量点做为a2进行试用,如果仍然都不能满足下降的最小步长,那么就遍历所有的样本点做为a2试用。如果还算是不能满足下降的最小步长,那么就重新选择a1。
计算选取变量的新值
首先计算出来的新值必须满足约束条件∑i=1Naiyi=0 ,那么求出来的anew2需要满足下列条件(具体推导见《统计学习方法》的7.4.1):L≤anew2≤HL=max(0,aold2−aold1),H=min(C,C+aold2−aold1),y1≠y2L=max(0,aold2+aold1−C),H=min(C,aold2+aold1),y1=y2
未经过裁剪的a2的解为:
anew,unc2=aold2+y2(E1−E2)ηη=K11+K22−2K12
裁剪后的解为
anew2=⎧⎩⎨⎪⎪H,anew,unc2>Hanew,unc2,L≤anew,unc2≤HL,anew,unc2<L
第一个变量的解为
anew1=aold1+y1y2(aold2−anew2)
还需要更新b:
bnew1=−E1−y1K11(anew1−aold1)−y2K21(anew2−aold2)+boldbnew2=−E2−y1K12(anew1−aold1)−y2K22(anew2−aold2)+bold
在更新b时,如果有0<anew1<C,
则bnew=bnew1,如果有0<anew2<C,
则 bnew=bnew2,
否则bnew=bnew1+bnew22。
由于缓存了Ei,所以需要计算新的Ei:
Enewi=∑j=1NyjajK(xi,xj)+bnew−yi
SMO的一个实现例子
我实现了一个简单的基于SMO的线性svm,是一个python脚本。实现的过程中,变量的选取并未严格按照算法讲的方法选取,选择了一个简单的选取方法。 一次迭代中,遍历所有的ai,如果ai违反了KKT条件,那么就将它做为第一个变量,然后再遍历所有的ai,依次做为第二个变量,如果第二个变量有足够的下降,那么就更新两个变量。如果没有,就不更新。实现的python脚本如下:
使用python实现的基于SMO的SVM (smo.py)download
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# SMO的一个简单实现
# implement SMO
import sys
import math
import matplotlib.pyplot as plt
samples = []
labels = []
class svm_params:
def __init__(self):
self.a = []
self.b = 0
params = svm_params()
e_dict = []
#train_data = "svm.train_mix_ok"
train_data = "svm.train"
def loaddata():
fn = open(train_data,"r")
for line in fn:
line = line[:-1]
vlist = line.split("\t")
samples.append((int(vlist[0]), int(vlist[1])))
labels.append(int(vlist[2]))
params.a.append(0.0)
fn.close()
# linear
def kernel(j, i):
ret = 0.0
for idx in range(len(samples[j])):
ret += samples[j][idx] * samples[i][idx]
return ret
def predict_real_diff(i):
diff = 0.0
for j in range(len(samples)):
diff += params.a[j] * labels[j] * kernel(j,i)
diff = diff + params.b - labels[i]
return diff
def init_e_dict():
for i in range(len(params.a)):
e_dict.append(predict_real_diff(i))
def update_e_dict():
for i in range(len(params.a)):
e_dict[i] = predict_real_diff(i)
def train(tolerance, times, C):
time = 0
init_e_dict()
updated = True
while time < times and updated:
updated = False
time += 1
for i in range(len(params.a)):
ai = params.a[i]
Ei = e_dict[i]
# 违反KKT
# agaist the KKT
if (labels[i] * Ei < -tolerance and ai < C) or (labels[i] * Ei > tolerance and ai > 0):
for j in range(len(params.a)):
if j == i: continue
eta = kernel(i, i) + kernel(j, j) - 2 * kernel(i, j)
if eta <= 0:
continue
new_aj = params.a[j] + labels[j] * (e_dict[i] - e_dict[j]) / eta
L = 0.0
H = 0.0
if labels[i] == labels[j]:
L = max(0, params.a[j] + params.a[i] - C)
H = min(C, params.a[j] + params.a[i])
else:
L = max(0, params.a[j] - params.a[i])
H = min(C, C + params.a[j] - params.a[i])
if new_aj > H:
new_aj = H
if new_aj < L:
new_aj = L
# 《统计学习方法》公式7.109(下同)
# formula 7.109
new_ai = params.a[i] + labels[i] * labels[j] * (params.a[j] - new_aj)
# 第二个变量下降是否达到最小步长
# decline enough for new_aj
if abs(params.a[j] - new_aj) < 0.001:
print "j = %d, is not moving enough" % j
continue
# formula 7.115
new_b1 = params.b - e_dict[i] - labels[i]*kernel(i,i)*(new_ai-params.a[i]) - labels[j]*kernel(j,i)*(new_aj-params.a[j])
# formula 7.116
new_b2 = params.b - e_dict[j] - labels[i]*kernel(i,j)*(new_ai-params.a[i]) - labels[j]*kernel(j,j)*(new_aj-params.a[j])
if new_ai > 0 and new_ai < C: new_b = new_b1
elif new_aj > 0 and new_aj < C: new_b = new_b2
else: new_b = (new_b1 + new_b2) / 2.0
params.a[i] = new_ai
params.a[j] = new_aj
params.b = new_b
update_e_dict()
updated = True
print "iterate: %d, changepair: i: %d, j:%d" %(time, i, j)
def draw(tolerance, C):
plt.xlabel(u"x1")
plt.xlim(0, 100)
plt.ylabel(u"x2")
plt.ylim(0, 100)
plt.title("SVM - %s, tolerance %f, C %f" % (train_data, tolerance, C))
ftrain = open(train_data, "r")
for line in ftrain:
line = line[:-1]
sam = line.split("\t")
if int(sam[2]) > 0:
plt.plot(sam[0],sam[1], 'or')
else:
plt.plot(sam[0],sam[1], 'og')
w1 = 0.0
w2 = 0.0
for i in range(len(labels)):
w1 += params.a[i] * labels[i] * samples[i][0]
w2 += params.a[i] * labels[i] * samples[i][1]
w = - w1 / w2
b = - params.b / w2
r = 1 / w2
lp_x1 = [10, 90]
lp_x2 = []
lp_x2up = []
lp_x2down = []
for x1 in lp_x1:
lp_x2.append(w * x1 + b)
lp_x2up.append(w * x1 + b + r)
lp_x2down.append(w * x1 + b - r)
plt.plot(lp_x1, lp_x2, 'b')
plt.plot(lp_x1, lp_x2up, 'b--')
plt.plot(lp_x1, lp_x2down, 'b--')
plt.show()
if __name__ == "__main__":
loaddata()
print samples
print labels
# 惩罚系数
# penalty for mis classify
C = 10
# 计算精度
# computational accuracy
tolerance = 0.0001
train(tolerance, 100, C)
print "a = ", params.a
print "b = ", params.b
support = []
for i in range(len(params.a)):
if params.a[i] > 0 and params.a[i] < C:
support.append(samples[i])
print "support vector = ", support
draw(tolerance, C) |
separable可以生成能够完全划分开的样本和不能划分开的样本。
这个smo.py脚本是一个线性的svm,替换掉脚本中
kernel函数,就可以成为一个非线性的svm。
下面这两张图片是用训练数据训练的结果。这一张是样本能完全分离开的:
这一张是样本不能完全分离开的:
以上就是如何实现SMO的全部内容。之前的一个同事实现了一个简单的识别手写数字ocr,下一章,我们也来用svm实现一个简单的识别数字的ocr吧。

相关文章推荐
- 【机器学习】支持向量机(二)——序列最小最优化(SMO)算法
- 支持向量机之序列最小最优化算法
- 统计学习方法第七章的序列最小最优化算法SMO代码实践
- SVM——(七)SMO(序列最小最优算法)
- 支持向量机SVM----简化版序列最小优化SMO(Sequential Minimal Optimation)
- 序列最小优化算法(SMO)
- 机器学习-python通过序列最小优化算法(SMO)方法编写支持向量机(SVM)
- 序列最小最优化算法 SMO
- SVM-支持向量机学习(7):求解SVM算法-SMO-序列最小最优化
- 【机器学习】支持向量机(SVM)的优化算法——序列最小优化算法(SMO)概述
- 砥志研思SVM(四) 序列最小最优化算法(SMO)论文翻译
- SVM-7-SMO(序列最小优化算法)
- 支持向量机—SMO论文详解(序列最小最优化算法)
- 支持向量机SVM----完整版序列最小优化SMO(Sequential Minimal Optimation)
- SCUTCODE.124 笔芯子序列 【最大流最小割】
- sicily 1800 序列,求长度在L-U之间的区间的最小值
- Wiki 2746(末日传说-打表找字典序最小逆序对=m的序列)
- 动态规划 之 回文序列的最小划分
- 51Nod1574(新姿势:使序列有序的最小交换次数)