hdu 1213 How Many Tables(并查集学习)
2014-05-18 22:11
597 查看
题目:
链接:点击打开链接
题意:
有n个朋友,编号为1......n。知道其中一些人相互认识,求最少需要多少桌子。
算法:
并查集算法的模板题。
(来源:LCY-teacher课件)
>>在某个城市里住着n个人,现在给定关于 n个人的m条信息(即某2个人认识)假设所有认识的人一定属于同一个单位,请计算该城市最多有多少单位?
>>如何实现?
>>什么是并查集?
>>英文:Disjoint Set,即“不相交集合”将编号分别为1…N的N个对象划分为不相交集合,在每个集合中,选择其中某个元素代表所在集合。常见两种操作:I.合并两个集合.II.查找某元素属于哪个集合
>>实现方法1:。用编号最小的元素标记所在集合;。定义一个数组set[1..n]
,其中set[i] 表示元素i 所在的集合。
对于合并我们必须搜索全部元素,效率太低。
>>考虑用树结构?
>>
n每个集合用一棵“有根树”表示
n定义数组 set[1..n]
nset[i] = i , 则i表示本集合,并是集合对应树的根
nset[i] = j, j<>i, 则 j 是 i 的父节点.
>>代码:
最坏情况Θ(N)
>>避免最坏情况:
n方法:将深度小的树合并到深度大的树
n实现:假设两棵树的深度分别为h1和h2, 则合并后的树的高度h是:
nmax(h1,h2), if h1<>h2.
nh1+1, if h1=h2.
n效果:任意顺序的合并操作以后,包含k个节点的树的最大高度不超过
路径压缩:
n思想:每次查找的时候,如果路径较长,则修改信息,以便下次查找的时候速度更快
n步骤:
n第一步,找到根结点
n第二步,修改查找路径上的所有节点,将它们都指向根结点
-------------------------------------------------------------------------------------------------
摘抄牛人博客:
链接:点击打开链接
内容:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
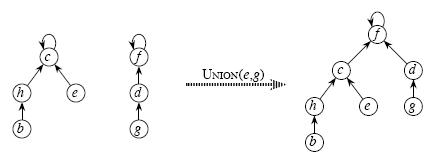
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图
l 并查集的优化
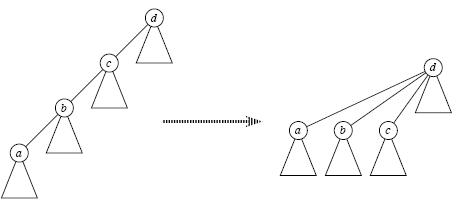
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
---------------------------------------------------------------------------
模板:
思路:
代码:
链接:点击打开链接
题意:
有n个朋友,编号为1......n。知道其中一些人相互认识,求最少需要多少桌子。
算法:
并查集算法的模板题。
(来源:LCY-teacher课件)
>>在某个城市里住着n个人,现在给定关于 n个人的m条信息(即某2个人认识)假设所有认识的人一定属于同一个单位,请计算该城市最多有多少单位?
>>如何实现?
>>什么是并查集?
>>英文:Disjoint Set,即“不相交集合”将编号分别为1…N的N个对象划分为不相交集合,在每个集合中,选择其中某个元素代表所在集合。常见两种操作:I.合并两个集合.II.查找某元素属于哪个集合
>>实现方法1:。用编号最小的元素标记所在集合;。定义一个数组set[1..n]
,其中set[i] 表示元素i 所在的集合。
<span style="font-size:14px;">find1(x)
{
return set[x];
}
</span><span style="font-size:14px;">Merge1(a,b)
{ i = min(a,b);
j = max(a,b);
for (k=1; k<=N; k++) {
if (set[k] == j)
set[k] = i;
}
}
</span>对于合并我们必须搜索全部元素,效率太低。
>>考虑用树结构?
>>
n每个集合用一棵“有根树”表示
n定义数组 set[1..n]
nset[i] = i , 则i表示本集合,并是集合对应树的根
nset[i] = j, j<>i, 则 j 是 i 的父节点.
>>代码:
merge2(a, b)
{
if (a<b)
set[b] = a;
else
set[a] = b;
}find2(x)
{
r = x;
while (set[r] != r)
r = set[r];
return r;
}最坏情况Θ(N)
>>避免最坏情况:
n方法:将深度小的树合并到深度大的树
n实现:假设两棵树的深度分别为h1和h2, 则合并后的树的高度h是:
nmax(h1,h2), if h1<>h2.
nh1+1, if h1=h2.
n效果:任意顺序的合并操作以后,包含k个节点的树的最大高度不超过
merge3(a,b)
{ if (height(a) == height(b)) {
height(a) = height(a) + 1;
set[b] = a;
} else if (height(a) < height(b))
set[a] = b;
else
set[b] = a;
}find2(x)
{
r = x;
while (set[r] != r)
r = set[r];
return r;
}路径压缩:
n思想:每次查找的时候,如果路径较长,则修改信息,以便下次查找的时候速度更快
n步骤:
n第一步,找到根结点
n第二步,修改查找路径上的所有节点,将它们都指向根结点
find3(x)
{
r = x;
while (set[r] <> r) //循环结束,则找到根节点
r = set[r];
i = x;
while (i <> r) //本循环修改查找路径中所有节点
{
j = set[i];
set[i] = r;
i = j;
}
}-------------------------------------------------------------------------------------------------
摘抄牛人博客:
链接:点击打开链接
内容:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图
l 并查集的优化
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。
---------------------------------------------------------------------------
模板:
int root[MAXN];//root[x]表示x的父节点
void init()//初始化
{
for(int i=0; i<MAXN; i++)
{
root[i] = i;
}
}
int findset(int x)//不带路径
{
int r = x;
while(r != root[r])
r = root[r];
return r;
}
void mergeset(int x,int y)//集合合并
{
int fx = findset(x);
int fy = findset(y);
if(fx != fy)
{
root[fx] = fy;
}
}//路径压缩findset
int findset(int x)
{
int t,r = x;
while(x != root[x])
x = root[x];
while(r != root[r])
{
t = root[r];
root[r] = x;
r = t;
}
}思路:
代码:
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int n,m,a,b,cnt;
int father[1010];
int getfather(int n)
{
while(n != father
)
n = father
;
return n;
}
void Union(int x,int y)
{
int rootx = getfather(x);
int rooty = getfather(y);
if(rootx != rooty)
father[rooty] = rootx;
}
int main()
{
//freopen("input.txt","r",stdin);
int t;
cin>>t;
while(t--)
{
getchar();
cnt = 0;
scanf("%d%d",&n,&m);
for(int i=1; i<=n; i++)
father[i] = i;
for(int i=1; i<=m; i++)
{
scanf("%d%d",&a,&b);
Union(a,b);
}
for(int i=1; i<=n; i++)
{
if(father[i] == i)
cnt++;
}
printf("%d\n",cnt);
}
return 0;
}

相关文章推荐
- [ACM] hdu 1213 How Many Tables(并查集)
- 杭电 hdu 1213 How Many Tables (并查集,简单题)
- HDU 1213 How Many Tables 并查集
- hdu 1213 How Many Tables(并查集~~)
- HDU 1213 How Many Tables 并查集 水~
- HDU 1213 How Many Tables 并查集
- HDU 1213 How Many Tables 并查集入门
- HDU-畅通工程-1232(并查集)How Many Tables(1213)
- Hdu1213 - How Many Tables - 并查集
- [ACM] hdu 1213 How Many Tables(并查集)
- hdu 1213 How Many Tables(并查集练习)
- HDU--1213--How Many Tables--并查集
- HDU 1213 How Many Tables(并查集)
- HDU 1213 How Many Tables(并查集)
- HDU 1213 How Many Tables,并查集
- hdu 1213 How Many Tables(并查集练习)
- hdu 1213 How Many Tables(并查集,简单题)
- HDU 1213 How Many Tables(并查集)
- hdu 1213 How Many Tables(并查集)
- HDU-#1213 How Many Tables (并查集)