基于conga实现RHCS简单部署
2014-05-07 12:51
260 查看
-----本文大纲
简介
术语
环境配置
实现过程
命令行管理工具
-------------
一、简介
RHCS即 RedHat Cluster Suite ,中文意思即红帽集群套件。红帽集群套件(RedHat Cluter Suite, RHCS)是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足你的对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。对于需要最大正常运行时间的应用来说,带有红帽集群套件(Red Hat Cluster Suite)的红帽企业 Linux 集群是最佳的选择。红帽集群套件专为红帽企业 Linux 量身设计,它提供有如下两种不同类型的集群: 1、应用/服务故障切换-通过创建n个节点的服务器集群来实现关键应用和服务的故障切换 2、IP 负载均衡-对一群服务器上收到的 IP 网络请求进行负载均衡利用红帽集群套件,可以以高可用性配置来部署应用,从而使其总是处于运行状态-这赋予了企业向外扩展(scale-out)Linux 部署的能力。对于网络文件系统(NFS)、Samba 和Apache 等大量应用的开源应用来说,红帽集群套件提供了一个随时可用的全面故障切换解决方案。
二、术语
分布式集群管理器(CMAN)
Cluster Manager,简称CMAN,是一个分布式集群管理工具,它运行在集群的各个节点上,为RHCS提供集群管理任务。
CMAN用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的关系,当集群中某个节点出现故障,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
锁管理(DLM)
Distributed Lock Manager,简称DLM,表示一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制,在RHCS集群系统中,DLM运行在集群的每个节点上,GFS通过锁管理器的锁机制来同步访问文件系统元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。
DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大的提高了处理性能。同时,DLM避免了当单个节点失败需要整体恢复的性能瓶颈,另外,DLM的请求都是本地的,不需要网络请求,因而请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
配置文件管理(CCS)
Cluster Configuration System,简称CCS,主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态,当这个文件发生任何变化时,都将此变化更新到集群中的每个节点,时刻保持每个节点的配置文件同步。例如,管理员在节点A上更新了集群配置文件,CCS发现A节点的配置文件发生变化后,马上将此变化传播到其它节点上去。
rhcs的配置文件是cluster.conf,它是一个xml文件,具体包含集群名称、集群节点信息、集群资源和服务信息、fence设备等,这个会在后面讲述。
栅设备(FENCE)
FENCE设备是RHCS集群中必不可少的一个组成部分,通过FENCE设备可以避免因出现不可预知的情况而造成的“脑裂”现象,FENCE设备的出现,就是为了解决类似这些问题,Fence设备主要就是通过服务器或存储本身的硬件管理接口,或者外部电源管理设备,来对服务器或存储直接发出硬件管理指令,将服务器重启或关机,或者与网络断开连接。
FENCE的工作原理是:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。
RHCS的FENCE设备可以分为两种:内部FENCE和外部FENCE,常用的内部FENCE有IBM RSAII卡,HP的iLO卡,还有IPMI的设备等,外部fence设备有UPS、SAN SWITCH、NETWORK SWITCH等
高可用服务管理器
高可用性服务管理主要用来监督、启动和停止集群的应用、服务和资源。它提供了一种对集群服务的管理能力,当一个节点的服务失败时,高可用性集群服务管理进程可以将服务从这个失败节点转移到其它健康节点上来,并且这种服务转移能力是自动、透明的。
RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
在一个RHCS集群中,高可用性服务包含集群服务和集群资源两个方面,集群服务其实就是应用服务,例如apache、mysql等,集群资源有很多种,例如一个IP地址、一个运行脚本、ext3/GFS文件系统等。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的,所谓失败转移域是一个运行特定服务的集群节点的集合。在失败转移域中,可以给每个节点设置相应的优先级,通过优先级的高低来决定节点失败时服务转移的先后顺序,如果没有给节点指定优先级,那么集群高可用服务将在任意节点间转移。因此,通过创建失败转移域不但可以设定服务在节点间转移的顺序,而且可以限制某个服务仅在失败转移域指定的节点内进行切换。
集群配置管理工具
RHCS提供了多种集群配置和管理工具,常用的有基于GUI的system-config-cluster、Conga等,也提供了基于命令行的管理工具。
system-config-cluster是一个用于创建集群和配置集群节点的图形化管理工具,它有集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态。一般用在RHCS早期的版本中。
Conga是一种web集群配置工具,与system-config-cluster不同的是,Conga是通过web方式来配置和管理集群节点的。Conga有两部分组成,分别是luci和ricci,luci安装在一台独立的计算机上,用于配置和管理集群,ricci安装在每个集群节点上,Luci通过ricci和集群中的每个节点进行通信。
RHCS也提供了一些功能强大的集群命令行管理工具,常用的有clustat、cman_tool、ccs_tool、fence_tool、clusvcadm等。
Redhat GFS
GFS是RHCS为集群系统提供的一个存储解决方案,它允许集群多个节点在块级别上共享存储,每个节点通过共享一个存储空间,保证了访问数据的一致性,更切实的说,GFS是RHCS提供的一个集群文件系统,多个节点同时挂载一个文件系统分区,而文件系统数据不受破坏,这是单一的文件系统,例如EXT3、EXT2所不能做到的。
为了实现多个节点对于一个文件系统同时读写操作,GFS使用锁管理器来管理I/O操作,当一个写进程操作一个文件时,这个文件就被锁定,此时不允许其它进程进行读写操作,直到这个写进程正常完成才释放锁,只有当锁被释放后,其它读写进程才能对这个文件进行操作,另外,当一个节点在GFS文件系统上修改数据后,这种修改操作会通过RHCS底层通信机制立即在其它节点上可见。
在搭建RHCS集群时,GFS一般作为共享存储,运行在每个节点上,并且可以通过RHCS管理工具对GFS进行配置和管理。这些需要说明的是RHCS和GFS之间的关系,一般初学者很容易混淆这个概念:运行RHCS,GFS不是必须的,只有在需要共享存储时,才需要GFS支持,而搭建GFS集群文件系统,必须要有RHCS的底层支持,所以安装GFS文件系统的节点,必须安装RHCS组件
三、环境配置
四、实现过程前提
时间同步主机名解析ssh互信
注:如果yum源中有epel源要禁用,这是因为,此套件为redhat官方只认可自己发行的版本,如果不是认可的版本,可能将无法启动服务
管理集群节点端
打开web界面就可以配置了
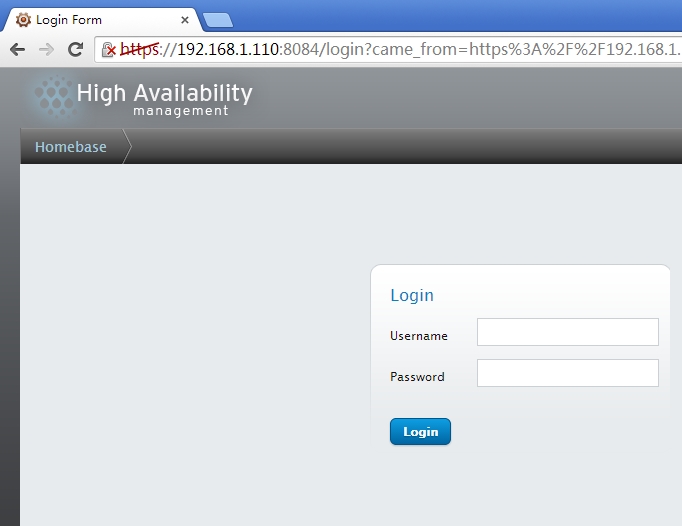
输入系统用户及密码就可以登录了,(注:一定要以https://协议开头)
输入正确的用户及密码就可登录了,如果是root登录会有警告提示信息

这时就可以使用Manager Clusters管理集群了

创建一个集群
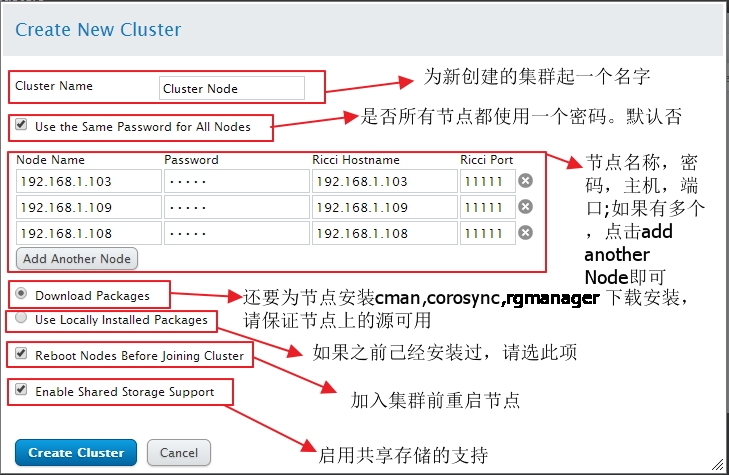
创建完成后
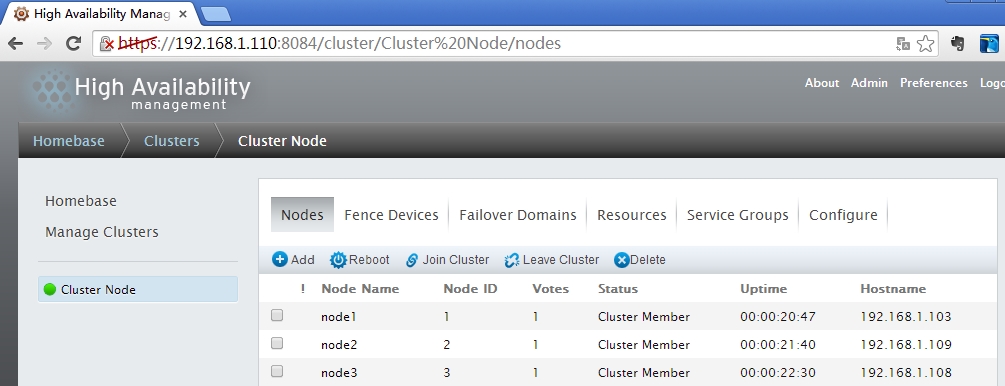
标签说明
Nodes :节点信息Fence Devices :隔离设备Failover Domins :故障转移域Resources :定义资源Service Groups :服务组Cinfigure :配置文件
定义故障转移域
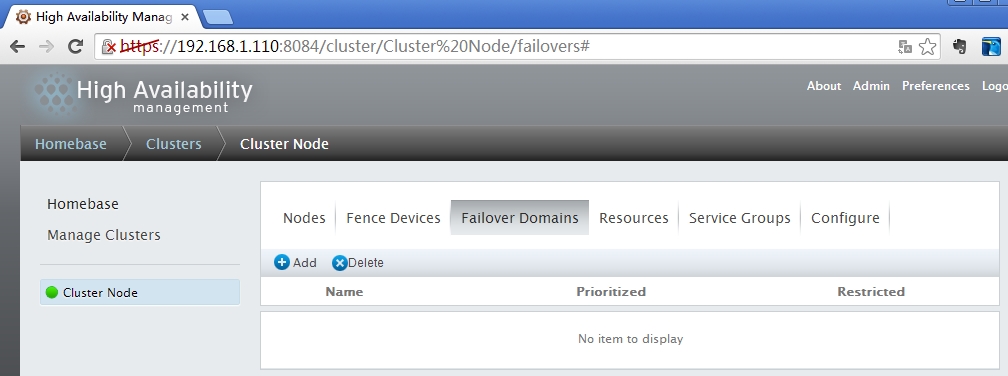
定义故障转移域的优先级,当节点重新上线后,资源是否切换

添加后的状态

可以选择的资源类型
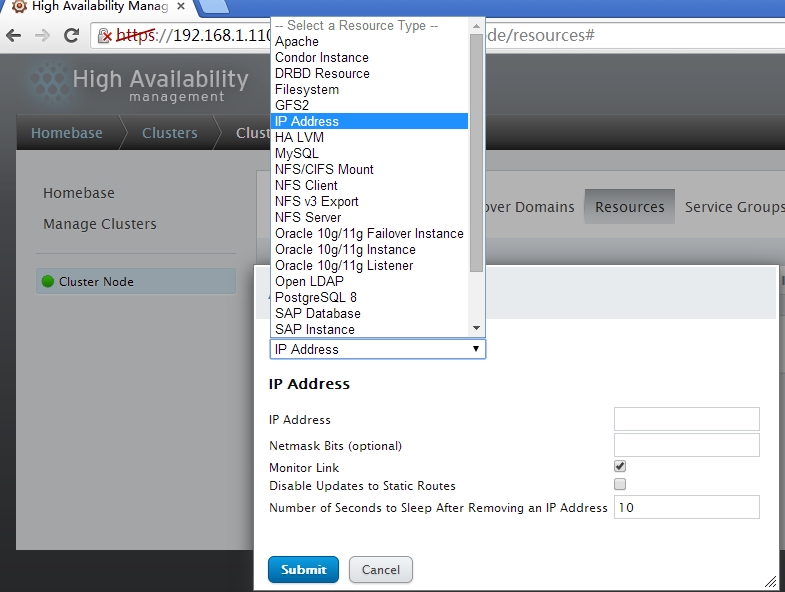
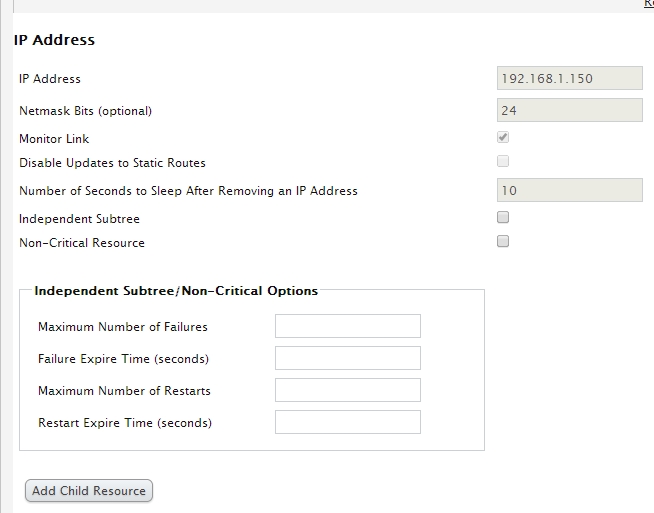
添加一个ip地址
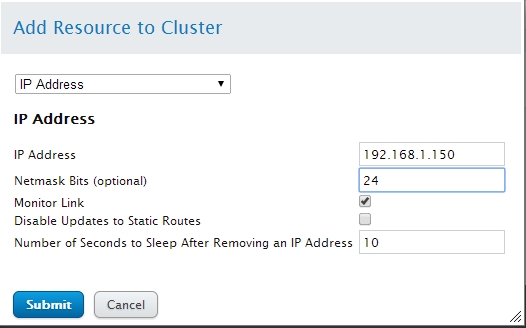
ip address :ip 地址Netmask Bits:掩码位数
Montor Link :是否监控此链接
Disable Updates to Static Route:是否更新静态路由
Number of Seconds to Sleep Removing an IP Address
多长时间无响应将转移此ip 地址
提交后生成的一条记录
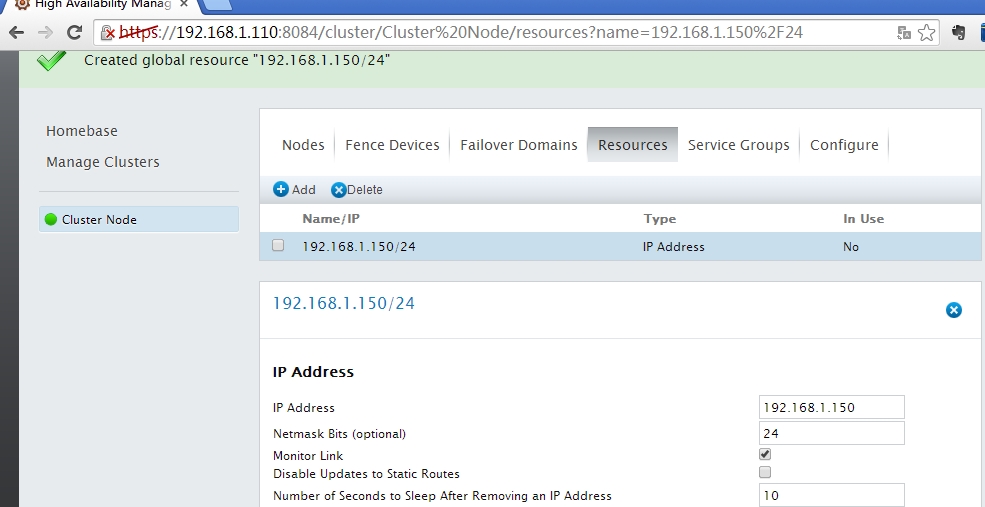
将此资源添加到组中(也可以在service group定义资源)

service name :服务的名字Automatically Start This Service: 是否自动运行此服务Failover Domain:故障转移区域Recovery Policy:故障处理规则Relocate :转移到其它节点 Restart :在当前节点上重启Restart-Disable :禁止重启,直接转移到其它节点上 Disable:禁用
还可以添加资源
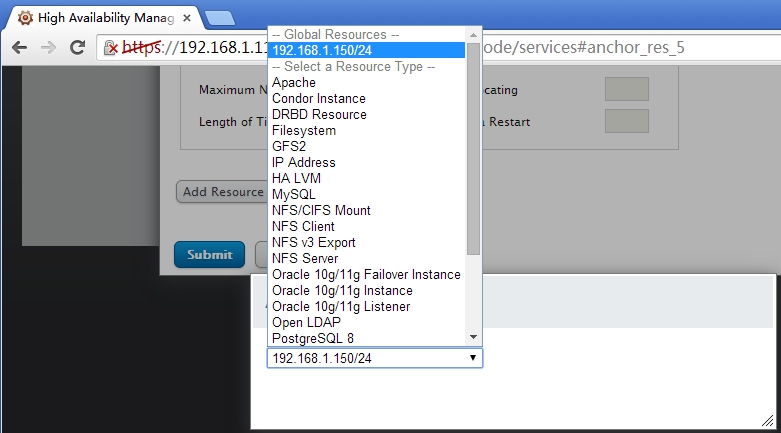
将己经定义的资源添加到组中(之前己经定义过的ip地址)
添加一个web服务
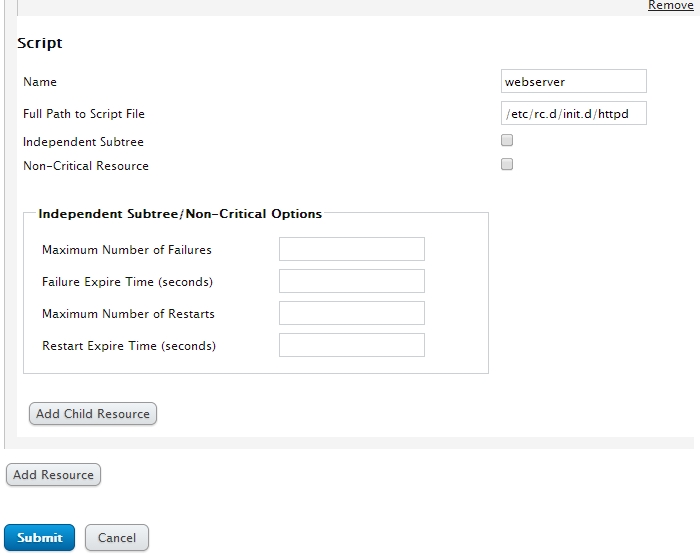
注:在默认类型中并没有 httpd服务,所以只能通过脚本来调用定义完成后就可以提交了,如果此资源想撤销,可以点击右上角remove即可
提交后的组资源

刚提交时,无法检测资源的状态,要重启一次重启组资源(Restart)
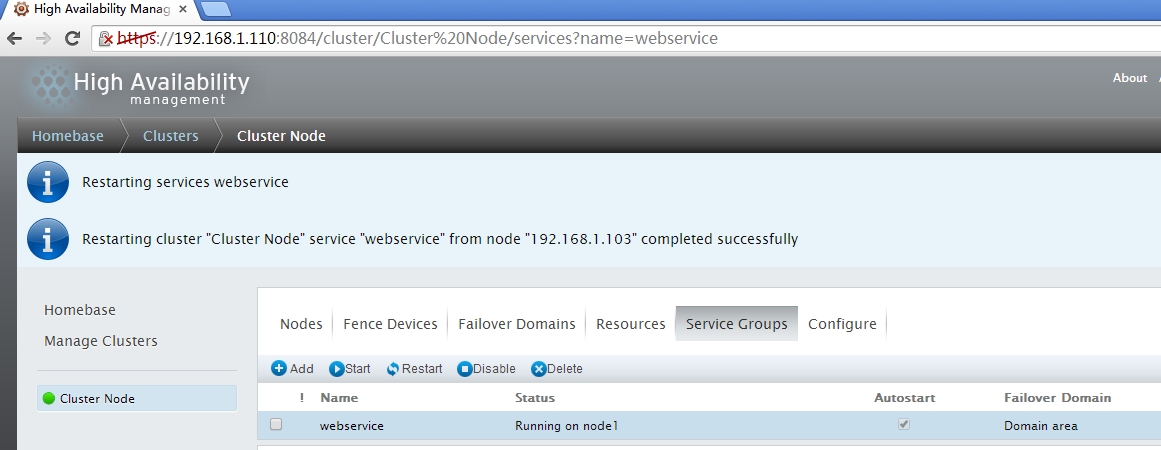
当前的状态己经显示运行于节点node1上
访问测试一下,己经运行于node1上

模拟故障转移
在节点中将node1离线
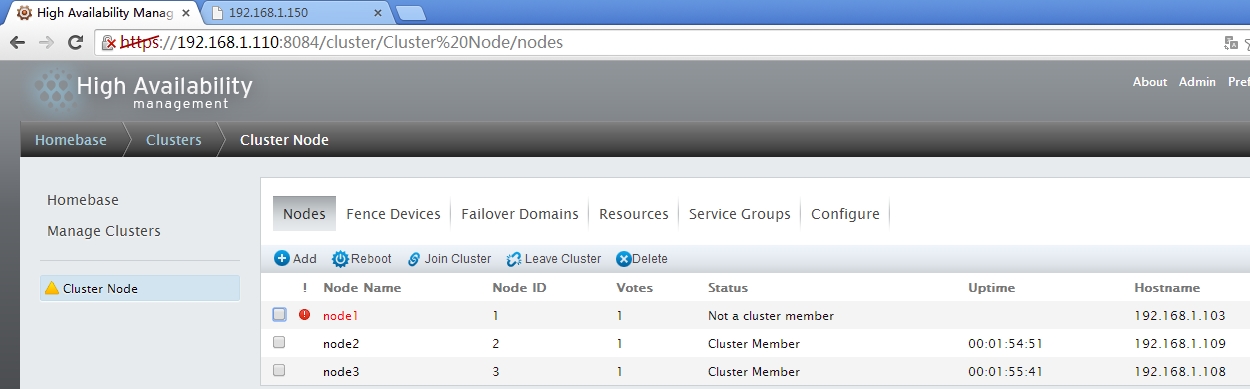
查看资源是否转移,可以查看service group,也可能通过网页测试
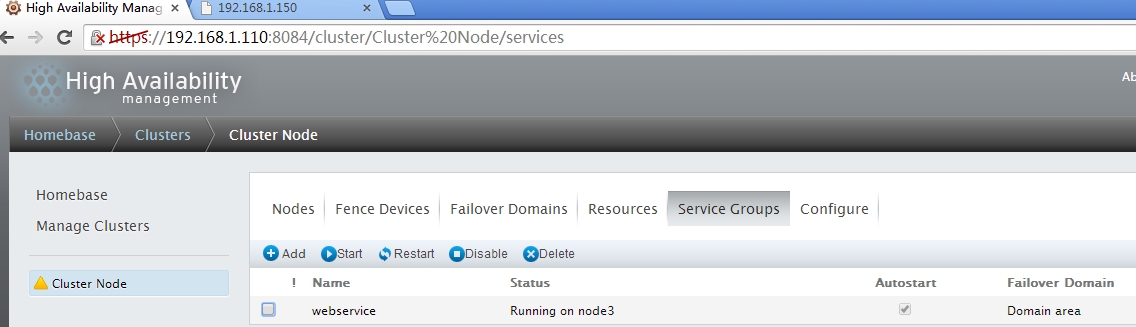
服务己经切换到node3上,访问一下网页看一下效果
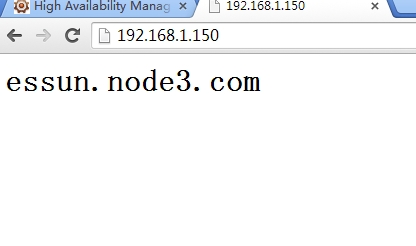
资源的确己经切换了,让node1重新上线后,资源是不会切换回到node1上的,因为在定义节时己经设置了no failback
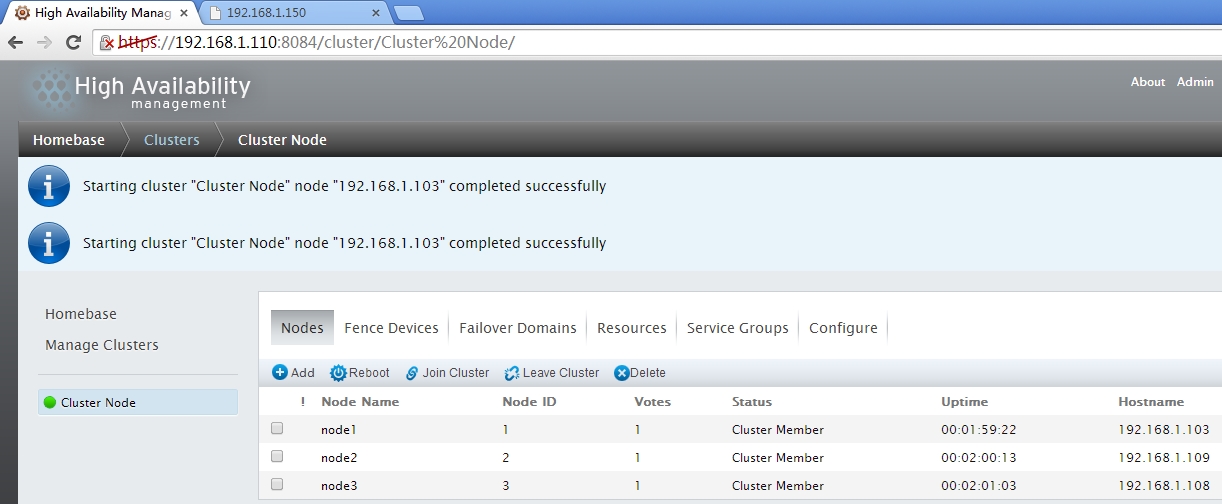
五、命令行管理工具
1、clustat
clustat 显示集群状态。它为您提供成员信息、仲裁查看、所有高可用性服务的状态,并给出运行 clustat 命令的节点(本地)
命令参数
您可以使用 clusvcadm 命令管理 HA 服务。使用它您可以执行以下操作:
启用并启动服务禁用服务停止服务冻结服务解冻服务迁移服务(只用于虚拟机服务)重新定位服务重启服务命令参数
命令参数
本文出自 “和风细雨” 博客,请务必保留此出处http://essun.blog.51cto.com/721033/1407638
简介
术语
环境配置
实现过程
命令行管理工具
-------------
一、简介
RHCS即 RedHat Cluster Suite ,中文意思即红帽集群套件。红帽集群套件(RedHat Cluter Suite, RHCS)是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足你的对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。对于需要最大正常运行时间的应用来说,带有红帽集群套件(Red Hat Cluster Suite)的红帽企业 Linux 集群是最佳的选择。红帽集群套件专为红帽企业 Linux 量身设计,它提供有如下两种不同类型的集群: 1、应用/服务故障切换-通过创建n个节点的服务器集群来实现关键应用和服务的故障切换 2、IP 负载均衡-对一群服务器上收到的 IP 网络请求进行负载均衡利用红帽集群套件,可以以高可用性配置来部署应用,从而使其总是处于运行状态-这赋予了企业向外扩展(scale-out)Linux 部署的能力。对于网络文件系统(NFS)、Samba 和Apache 等大量应用的开源应用来说,红帽集群套件提供了一个随时可用的全面故障切换解决方案。
二、术语
分布式集群管理器(CMAN)
Cluster Manager,简称CMAN,是一个分布式集群管理工具,它运行在集群的各个节点上,为RHCS提供集群管理任务。
CMAN用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的关系,当集群中某个节点出现故障,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
锁管理(DLM)
Distributed Lock Manager,简称DLM,表示一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制,在RHCS集群系统中,DLM运行在集群的每个节点上,GFS通过锁管理器的锁机制来同步访问文件系统元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。
DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大的提高了处理性能。同时,DLM避免了当单个节点失败需要整体恢复的性能瓶颈,另外,DLM的请求都是本地的,不需要网络请求,因而请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
配置文件管理(CCS)
Cluster Configuration System,简称CCS,主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态,当这个文件发生任何变化时,都将此变化更新到集群中的每个节点,时刻保持每个节点的配置文件同步。例如,管理员在节点A上更新了集群配置文件,CCS发现A节点的配置文件发生变化后,马上将此变化传播到其它节点上去。
rhcs的配置文件是cluster.conf,它是一个xml文件,具体包含集群名称、集群节点信息、集群资源和服务信息、fence设备等,这个会在后面讲述。
栅设备(FENCE)
FENCE设备是RHCS集群中必不可少的一个组成部分,通过FENCE设备可以避免因出现不可预知的情况而造成的“脑裂”现象,FENCE设备的出现,就是为了解决类似这些问题,Fence设备主要就是通过服务器或存储本身的硬件管理接口,或者外部电源管理设备,来对服务器或存储直接发出硬件管理指令,将服务器重启或关机,或者与网络断开连接。
FENCE的工作原理是:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。
RHCS的FENCE设备可以分为两种:内部FENCE和外部FENCE,常用的内部FENCE有IBM RSAII卡,HP的iLO卡,还有IPMI的设备等,外部fence设备有UPS、SAN SWITCH、NETWORK SWITCH等
高可用服务管理器
高可用性服务管理主要用来监督、启动和停止集群的应用、服务和资源。它提供了一种对集群服务的管理能力,当一个节点的服务失败时,高可用性集群服务管理进程可以将服务从这个失败节点转移到其它健康节点上来,并且这种服务转移能力是自动、透明的。
RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
在一个RHCS集群中,高可用性服务包含集群服务和集群资源两个方面,集群服务其实就是应用服务,例如apache、mysql等,集群资源有很多种,例如一个IP地址、一个运行脚本、ext3/GFS文件系统等。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的,所谓失败转移域是一个运行特定服务的集群节点的集合。在失败转移域中,可以给每个节点设置相应的优先级,通过优先级的高低来决定节点失败时服务转移的先后顺序,如果没有给节点指定优先级,那么集群高可用服务将在任意节点间转移。因此,通过创建失败转移域不但可以设定服务在节点间转移的顺序,而且可以限制某个服务仅在失败转移域指定的节点内进行切换。
集群配置管理工具
RHCS提供了多种集群配置和管理工具,常用的有基于GUI的system-config-cluster、Conga等,也提供了基于命令行的管理工具。
system-config-cluster是一个用于创建集群和配置集群节点的图形化管理工具,它有集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态。一般用在RHCS早期的版本中。
Conga是一种web集群配置工具,与system-config-cluster不同的是,Conga是通过web方式来配置和管理集群节点的。Conga有两部分组成,分别是luci和ricci,luci安装在一台独立的计算机上,用于配置和管理集群,ricci安装在每个集群节点上,Luci通过ricci和集群中的每个节点进行通信。
RHCS也提供了一些功能强大的集群命令行管理工具,常用的有clustat、cman_tool、ccs_tool、fence_tool、clusvcadm等。
Redhat GFS
GFS是RHCS为集群系统提供的一个存储解决方案,它允许集群多个节点在块级别上共享存储,每个节点通过共享一个存储空间,保证了访问数据的一致性,更切实的说,GFS是RHCS提供的一个集群文件系统,多个节点同时挂载一个文件系统分区,而文件系统数据不受破坏,这是单一的文件系统,例如EXT3、EXT2所不能做到的。
为了实现多个节点对于一个文件系统同时读写操作,GFS使用锁管理器来管理I/O操作,当一个写进程操作一个文件时,这个文件就被锁定,此时不允许其它进程进行读写操作,直到这个写进程正常完成才释放锁,只有当锁被释放后,其它读写进程才能对这个文件进行操作,另外,当一个节点在GFS文件系统上修改数据后,这种修改操作会通过RHCS底层通信机制立即在其它节点上可见。
在搭建RHCS集群时,GFS一般作为共享存储,运行在每个节点上,并且可以通过RHCS管理工具对GFS进行配置和管理。这些需要说明的是RHCS和GFS之间的关系,一般初学者很容易混淆这个概念:运行RHCS,GFS不是必须的,只有在需要共享存储时,才需要GFS支持,而搭建GFS集群文件系统,必须要有RHCS的底层支持,所以安装GFS文件系统的节点,必须安装RHCS组件
三、环境配置
| 系统 | 角色 | ip地址 | 安装包 |
| Centos6.5 x86_64 | 管理集群节点端 | 192.168.1.110 | luci |
| Centos6.5 x86_64 | web节点端(node1) | 192.168.1.103 | ricci |
| Centos6.5 x86_64 | web节点端(node2) | 192.168.1.109 | ricci |
| Centos6.5 x86_64 | web节点端(node3) | 192.168.1.108 | ricci |
时间同步主机名解析ssh互信
注:如果yum源中有epel源要禁用,这是因为,此套件为redhat官方只认可自己发行的版本,如果不是认可的版本,可能将无法启动服务
管理集群节点端
[root@essun ~]# yum install -y luci [root@essun ~]# service luci start Adding following auto-detected host IDs (IP addresses/domain names), corresponding to `essun.node4.com' address, to the configuration of self-managed certificate `/var/lib/luci/etc/cacert.config' (you can change them by editing `/var/lib/luci/etc/cacert.config', removing the generated certificate `/var/lib/luci/certs/host.pem' and restarting luci): (none suitable found, you can still do it manually as mentioned above) Generating a 2048 bit RSA private key writing new private key to '/var/lib/luci/certs/host.pem' Starting saslauthd: [ OK ] Start luci... [ OK ] Point your web browser to https://essun.node4.com:8084 (or equivalent) to access luci [root@essun ~]# ss -tnpl |grep 8084 LISTEN 0 5 *:8084 *:* users:(("python",2920,5)) [root@essun ~]#而节点间要安装ricci,并且要为各节点上的ricci用户创建一个密码,以便集群服务管理各节点,为每一个节点提供一个测试页面(此处以一个节点为例,其它两个节点安装方式一样)
[root@essun .ssh]# yum install ricci -y
[root@essun ~]# service ricci start
Starting oddjobd: [ OK ]
generating SSL certificates... done
Generating NSS database... done
Starting ricci: [ OK ]
[root@essun ~]# ss -tnlp |grep ricci
LISTEN 0 5 :::11111 :::* users:(("ricci",2241,3))
#ricci默认监听于11111端口
[root@essun .ssh]# echo "ricci" |passwd --stdin ricci
Changing password for user ricci.
passwd: all authentication tokens updated successfully.
#此处以ricci为密码
[root@essun html]# echo "<h1>`hostname`</h1>" >index.html
[root@essun html]# service httpd start
Starting httpd: [ OK ]打开web界面就可以配置了
输入系统用户及密码就可以登录了,(注:一定要以https://协议开头)
输入正确的用户及密码就可登录了,如果是root登录会有警告提示信息
这时就可以使用Manager Clusters管理集群了
创建一个集群
创建完成后
标签说明
Nodes :节点信息Fence Devices :隔离设备Failover Domins :故障转移域Resources :定义资源Service Groups :服务组Cinfigure :配置文件
定义故障转移域
定义故障转移域的优先级,当节点重新上线后,资源是否切换
添加后的状态
可以选择的资源类型
添加一个ip地址
ip address :ip 地址Netmask Bits:掩码位数
Montor Link :是否监控此链接
Disable Updates to Static Route:是否更新静态路由
Number of Seconds to Sleep Removing an IP Address
多长时间无响应将转移此ip 地址
提交后生成的一条记录
将此资源添加到组中(也可以在service group定义资源)
service name :服务的名字Automatically Start This Service: 是否自动运行此服务Failover Domain:故障转移区域Recovery Policy:故障处理规则Relocate :转移到其它节点 Restart :在当前节点上重启Restart-Disable :禁止重启,直接转移到其它节点上 Disable:禁用
还可以添加资源
将己经定义的资源添加到组中(之前己经定义过的ip地址)
添加一个web服务
注:在默认类型中并没有 httpd服务,所以只能通过脚本来调用定义完成后就可以提交了,如果此资源想撤销,可以点击右上角remove即可
提交后的组资源
刚提交时,无法检测资源的状态,要重启一次重启组资源(Restart)
当前的状态己经显示运行于节点node1上
访问测试一下,己经运行于node1上
模拟故障转移
在节点中将node1离线
查看资源是否转移,可以查看service group,也可能通过网页测试
服务己经切换到node3上,访问一下网页看一下效果
资源的确己经切换了,让node1重新上线后,资源是不会切换回到node1上的,因为在定义节时己经设置了no failback
五、命令行管理工具
1、clustat
clustat 显示集群状态。它为您提供成员信息、仲裁查看、所有高可用性服务的状态,并给出运行 clustat 命令的节点(本地)
命令参数
[root@essun html]# clustat --help clustat: invalid option -- '-' usage: clustat <options> -i <interval> Refresh every <interval> seconds. May not be used with -x. -I Display local node ID and exit -m <member> Display status of <member> and exit -s <service> Display status of <service> and exit -v Display version and exit -x Dump information as XML -Q Return 0 if quorate, 1 if not (no output) -f Enable fast clustat reports -l Use long format for services #查看节点状态信息 [root@essun html]# clustat -l Cluster Status for Cluster Node @ Wed May 7 11:32:55 2014 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node1 1 Online, Local, rgmanager node2 2 Online node3 3 Online Service Information ------- ----------- Service Name : service:webservice Current State : started (112) Flags : none (0) Owner : node1 Last Owner : none Last Transition : Wed May 7 10:06:48 20142、clusvcadm
您可以使用 clusvcadm 命令管理 HA 服务。使用它您可以执行以下操作:
启用并启动服务禁用服务停止服务冻结服务解冻服务迁移服务(只用于虚拟机服务)重新定位服务重启服务命令参数
[root@essun html]# clusvcadm usage: clusvcadm [command] Resource Group Control Commands: -v Display version and exit -d <group> Disable <group>. This stops a group until an administrator enables it again, the cluster loses and regains quorum, or an administrator-defined event script explicitly enables it again. -e <group> Enable <group> -e <group> -F Enable <group> according to failover domain rules (deprecated; always the case when using central processing) -e <group> -m <member> Enable <group> on <member> -r <group> -m <member> Relocate <group> [to <member>] Stops a group and starts it on another cluster member. -M <group> -m <member> Migrate <group> to <member> (e.g. for live migration of VMs) -q Quiet operation -R <group> Restart a group in place. -s <group> Stop <group>. This temporarily stops a group. After the next group or or cluster member transition, the group will be restarted (if possible). -Z <group> Freeze resource group. This prevents transitions and status checks, and is useful if an administrator needs to administer part of a service without stopping the whole service. -U <group> Unfreeze (thaw) resource group. Restores a group to normal operation. -c <group> Convalesce (repair, fix) resource group. Attempts to start failed, non-critical resources within a resource group. Resource Group Locking (for cluster Shutdown / Debugging): -l Lock local resource group managers. This prevents resource groups from starting. -S Show lock state -u Unlock resource group managers. This allows resource groups to start. #资源迁移 [root@essun html]# clusvcadm -r webservice -m node1 Trying to relocate service:webservice to node1...Success service:webservice is now running on node1 [root@essun html]# curl http://192.168.1.150 <h1>essun.node1.com</h1>3、cman_toolcman_tool是一种用来管理CMAN集群管理子系统的工具集,cman_tool可以用来添加集群节点,杀死另一个集群节点或改变预期集群的选票的价值。注意:cman_tool发出的命令会影响你的集群中的所有节点。
命令参数
[root@essun html]# cman_tool -h Usage: cman_tool <join|leave|kill|expected|votes|version|wait|status|nodes|services|debug> [options] Options: -h Print this help, then exit -V Print program version information, then exit -d Enable debug output join Cluster & node information is taken from configuration modules. These switches are provided to allow those values to be overridden. Use them with extreme care. -m <addr> Multicast address to use -v <votes> Number of votes this node has -e <votes> Number of expected votes for the cluster -p <port> UDP port number for cman communications -n <nodename> The name of this node (defaults to hostname) -c <clustername> The name of the cluster to join -N <id> Node id -C <module> Config file reader (default: xmlconfig) -w Wait until node has joined a cluster -q Wait until the cluster is quorate -t Maximum time (in seconds) to wait -k <file> Private key file for Corosync communications -P Don't set corosync to realtime priority -X Use internal cman defaults for configuration -A Don't load openais services -D<fail|warn|none> What to do about the config. Default (without -D) is to validate the config. with -D no validation will be done. -Dwarn will print errors but allow the operation to continue. -z Disable stderr debugging output. wait Wait until the node is a member of a cluster -q Wait until the cluster is quorate -t Maximum time (in seconds) to wait leave -w If cluster is in transition, wait and keep trying -t Maximum time (in seconds) to wait remove Tell other nodes to ajust quorum downwards if necessary force Leave even if cluster subsystems are active kill -n <nodename> The name of the node to kill (can specify multiple times) expected -e <votes> New number of expected votes for the cluster votes -v <votes> New number of votes for this node status Show local record of cluster status nodes Show local record of cluster nodes -a Also show node address(es) -n <nodename> Only show information for specific node -F <format> Specify output format (see man page) services Show local record of cluster services version -r Reload cluster.conf and update config version. -D <fail,warn,none> What to do about the config. Default (without -D) is to validate the config. with -D no validation will be done. -Dwarn will print errors but allow the operation to continue -S Don't run ccs_sync to distribute cluster.conf (if appropriate) #查看节点属性 [root@essun html]# cman_tool status Version: 6.2.0 Config Version: 6 Cluster Name: Cluster Node Cluster Id: 26887 Cluster Member: Yes Cluster Generation: 36 Membership state: Cluster-Member Nodes: 3 Expected votes: 3 Total votes: 3 Node votes: 1 Quorum: 2 Active subsystems: 9 Flags: Ports Bound: 0 11 177 Node name: node1 Node ID: 1 Multicast addresses: 239.192.105.112 Node addresses: 192.168.1.103
本文出自 “和风细雨” 博客,请务必保留此出处http://essun.blog.51cto.com/721033/1407638

相关文章推荐
- uva 12002 Happy Birthday (dp)
- bfs与dfs
- 职责链模式
- linux设备驱动之——V4L2
- 解决职业危机的五个建议
- unity3d KeyCode各键值说明
- IOS 申请发布证书图文详解
- 【DOS】ECHO命令
- 【解决办法】outlook2003收发进度条卡住现象(exchange模式)
- 第五周作业
- 流量劫持是如何产生的之上古时代(1/3)
- 对于Java单例设计模式的总结和分析
- PL/SQL函数和过程
- Exchange Server 2010高可用设计
- 使用libcurl源码编译不过的问题
- 推荐一款针对于程序员开发的字体Source Code Pro
- LeetCode:Maximum Subarray
- WPF - MVVM - 如何将ComboBox的Selectchange事件binding到ViewModel
- 第四周作业
- 【python】中文乱码问题