【哈希表(散列表)】
2014-04-25 17:48
274 查看
一、基本概念
若关键字为

,则其值存放在

的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系

为散列函数(Hash
function),按这个思想建立的表为散列表。
对不同的关键字可能得到同一散列地址,即
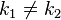
,而
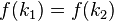
,这种现象称碰撞(Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数

和处理碰撞的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform
Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少碰撞。

二、哈希函数构造方法:
1、直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
但这种方法效率不高,时间复杂度是O(1),空间复杂度是O(n),n是关键字的个数

哈希表算法
2、数字分析法
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
三、平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得
(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:
(100,121,201,020,123)。
相应的散列函数用C实现很简单:
4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586-4,则:

哈希表算法
5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
三、处理冲突的方法:
1、开放定址法
Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中m为表长,di为增量序列
如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
例:在长度为11的哈希表中已填有关键字分别为17,60,29的记录,现有第四个记录,其关键字为38,由哈希函数得到地址为5,若用线性探测再散列,如下:

哈希表算法
2、再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
3、链地址法
将所有关键字为同义词的记录存储在同一线性链表中。

哈希表算法
4、建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
若关键字为
,则其值存放在
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
为散列函数(Hash
function),按这个思想建立的表为散列表。
对不同的关键字可能得到同一散列地址,即
,而
,这种现象称碰撞(Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数
和处理碰撞的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform
Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少碰撞。
二、哈希函数构造方法:
1、直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
但这种方法效率不高,时间复杂度是O(1),空间复杂度是O(n),n是关键字的个数
哈希表算法
2、数字分析法
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
三、平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得
(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:
(100,121,201,020,123)。
相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key*=key; key/=100; //先求平方值,后去掉末尾的两位数
return key%1000; //取中间三位数作为散列地址返回
}4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586-4,则:
哈希表算法
5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
三、处理冲突的方法:
1、开放定址法
Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中m为表长,di为增量序列
如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。
如果di取值可能为伪随机数列。称伪随机探测再散列。
例:在长度为11的哈希表中已填有关键字分别为17,60,29的记录,现有第四个记录,其关键字为38,由哈希函数得到地址为5,若用线性探测再散列,如下:
哈希表算法
2、再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
3、链地址法
将所有关键字为同义词的记录存储在同一线性链表中。
哈希表算法
4、建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。

相关文章推荐