朴素贝叶斯算法学习 (二)
2014-04-24 19:16
218 查看
第二、走进朴素贝叶斯算法
其实在很早前就听说过贝叶斯这个次,从概率论的贝叶斯公式,到贝叶斯神经网络,所以一直认为贝叶斯就是指的神经网络(太弱的想法了)。最近有一个项目需要用到朴素贝叶斯算法,说这个算法简单比较简单,容易解释,我才开始怀疑自己以前的理解。本读书笔记是通过阅读李航教授出的统计学习方法和网上牛人博客形成,若有理解不透彻、错误的地方希望大家留言指正谢谢。
先说说在阅读相关知识后,对朴素贝叶斯算法(Naive Bayes Algorithm)的总体理解。
即训练数据有
,\left( {{x_2},{y_2}} \right), \cdots ,\left( {{x_N},{y_N}} \right)} \right\}$$% MathType!End!2!1!)
N输入样本,其中

为训练样本的属性变量(即每个样本具有n个属性如:样本
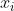
具有

个属性),

为标签变量(即一共有K个标签)。即最后训练的到的模型如下:(求在属性值为x的条件下,该样本属于

中那一类的后验概率最大,并取最大概率类别为样本类别)
 = \frac{{P\left( {X = x|Y = {c_k}} \right)P\left( {Y = {c_k}} \right)}}{{P\left( {X = x} \right)}} = \frac{{P\left( {X = x|Y = {c_k}} \right)P\left( {Y = {c_k}} \right)}}{{\sum\limits_i^k {P\left( {X = x|Y = {c_k}} \right)P\left( {Y = {c_k}} \right)} }})
等式一
通过训练数据很容易取出
})
的概率,而
 = {P\left( {{X^1} = {x^1},{X^2} = {x^2}, \cdots ,{X^n} = {x^n}|Y={c_k}} \right)} )
相对而言比较困难,但在朴素贝叶斯算法中对其条件概率分布作了条件独立性假设(即不同属性之间是相互独立的),朴素贝叶斯算法也是由这个较强的假设得名。由此假设以上公式可变形为:
 = \prod\limits_{j = 1}^n {P\left( {{X^j} = {x^j}|Y={c_k}} \right)})
最后化简等式一 得:
 = \frac{{\prod\limits_{j = 1}^n {P\left( {{X^j} = {x^j}|Y = {c_k}} \right)} P\left( {Y = {c_k}} \right)}}{{\sum\limits_i^k {\prod\limits_{j = 1}^n {P\left( {{X^j} = {x^j}|Y = {c_k}} \right)} P\left( {Y = {c_k}} \right)} }})
等式二
由等式二可知,对于同一测试样本其被分到不同类别的后验概率公式(即公式二)分母都是相同的,所以其后验概率的大小,取决于等式二的分子,即求解
})
,
})
,由于朴素贝叶斯算法作了条件独立性假设,通过训练样本数据,经过简单的统计就能求出。这样就能用来对测试样本就行分类了。
朴素贝叶斯算法(Naive Bayes Agorithm)
输入:训练数据
,\left(%20{{x_2},{y_2}}%20\right),%20\cdots%20,\left(%20{{x_N},{y_N}}%20\right)}%20\right\}$$%%20MathType!End!2!1!)
,其中
^T})
,

是第i个样本的第j个属性,

,

表示第
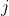
个属性可能去第
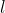
个值,

。测试数据

。
过程:
1、通过训练样本求解先验概率:
 = \frac{{\sum\limits_{i = 1}^N {I\left( {{y_i} = {c_k}} \right)} }}{N})
 = \frac{{\sum\limits_{i = 1}^N {I\left( {x_i^j = {a_{jl}},{y_i} = {c_k}} \right)} }}{{\sum\limits_{i = 1}^N {I\left( {{y_i} = {c_k}} \right)} }})
2、计算后验概率,并且取最大值:
\prod\limits_{j = 1}^n {P\left( {{X^j} = x_{test}^j|Y = {c_k}} \right)} )
输出:测试数据
属于哪一类。
第三、补充
1)、为什么要取后验概率最大化。
因为后验概率最大化能保证风险期望最小化。公式推导如下:
设0-1损失函数如下:

朴素贝叶斯算法的期望风险函数为:
 = E[L(Y,f(X))])
该期望是对联合分布
)
取的,由此去条件期望函数为:
 = {E_X}[L(Y,f(X))]P({c_k}|X))
为了使期望风险最小化,即以上等式等于:

即求期望风险最小化,就转化为求
)
最大化,即后验概率最大化。
所以在朴素贝叶斯算法求的是后验概率最大化的结果。
2)、如果
})
为0,即在

的条件下,

出现了0次,先验概率
)
将等于0。这将导致测试样本中只要存在属性值等于
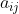
,这个测试样本的后验概率将为0,这将忽视别的属性对该样本的影响。公式解释:
\prod\limits_{j%20=%201}^n%20{P\left(%20{{X^j}%20=%20x_{test}^j|Y%20=%20{c_k}}%20\right)})
如果n的取值为3,上式等于:
\prod\limits_{j = 1}^n {P\left( {{X^j} = x_{test}^j|Y = {c_k}} \right)} = \arg \mathop {\max }\limits_{{c_k}} P\left( {Y = {c_k}} \right)P\left( {{X^1} = x_{test}^1|Y = {c_k}} \right)P\left( {{X^2} = x_{test}^2|Y = {c_k}} \right)P\left( {{X^3} = x_{test}^3|Y = {c_k}} \right))
只要
P\left( {{X^2} = x_{test}^2|Y = {c_k}} \right)P\left( {{X^3} = x_{test}^3|Y = {c_k}} \right))
三个概率任意一个概率为零,其余两个概率在整个公式中的作用也为零。
为了解决这个问题提出了贝叶斯估计。
贝叶斯估计: 即在求先验概率的时候引入了参数

,对其公式进行了如下修改
 = \frac{{\sum\limits_{i = 1}^N {I\left( {X_i^j = {a_{jl}},{y_i} = {c_k}} \right) + \lambda } }}{{\sum\limits_{i = 1}^N {I\left( {{y_i} = {c_k}} \right) + {S_j}\lambda } }})
一、如果
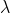
=0,就是一般的极大似然估计
二、如果
=1,成为拉普拉斯平滑
其实在很早前就听说过贝叶斯这个次,从概率论的贝叶斯公式,到贝叶斯神经网络,所以一直认为贝叶斯就是指的神经网络(太弱的想法了)。最近有一个项目需要用到朴素贝叶斯算法,说这个算法简单比较简单,容易解释,我才开始怀疑自己以前的理解。本读书笔记是通过阅读李航教授出的统计学习方法和网上牛人博客形成,若有理解不透彻、错误的地方希望大家留言指正谢谢。
先说说在阅读相关知识后,对朴素贝叶斯算法(Naive Bayes Algorithm)的总体理解。
即训练数据有
N输入样本,其中
为训练样本的属性变量(即每个样本具有n个属性如:样本
具有
个属性),
为标签变量(即一共有K个标签)。即最后训练的到的模型如下:(求在属性值为x的条件下,该样本属于
中那一类的后验概率最大,并取最大概率类别为样本类别)
等式一
通过训练数据很容易取出
的概率,而
相对而言比较困难,但在朴素贝叶斯算法中对其条件概率分布作了条件独立性假设(即不同属性之间是相互独立的),朴素贝叶斯算法也是由这个较强的假设得名。由此假设以上公式可变形为:
最后化简等式一 得:
等式二
由等式二可知,对于同一测试样本其被分到不同类别的后验概率公式(即公式二)分母都是相同的,所以其后验概率的大小,取决于等式二的分子,即求解
,
,由于朴素贝叶斯算法作了条件独立性假设,通过训练样本数据,经过简单的统计就能求出。这样就能用来对测试样本就行分类了。
朴素贝叶斯算法(Naive Bayes Agorithm)
输入:训练数据
,其中
,
是第i个样本的第j个属性,
,
表示第
个属性可能去第
个值,
。测试数据
。
过程:
1、通过训练样本求解先验概率:
2、计算后验概率,并且取最大值:
输出:测试数据
属于哪一类。
第三、补充
1)、为什么要取后验概率最大化。
因为后验概率最大化能保证风险期望最小化。公式推导如下:
设0-1损失函数如下:
朴素贝叶斯算法的期望风险函数为:
该期望是对联合分布
取的,由此去条件期望函数为:
为了使期望风险最小化,即以上等式等于:
即求期望风险最小化,就转化为求
最大化,即后验概率最大化。
所以在朴素贝叶斯算法求的是后验概率最大化的结果。
2)、如果
为0,即在
的条件下,
出现了0次,先验概率
将等于0。这将导致测试样本中只要存在属性值等于
,这个测试样本的后验概率将为0,这将忽视别的属性对该样本的影响。公式解释:
如果n的取值为3,上式等于:
只要
三个概率任意一个概率为零,其余两个概率在整个公式中的作用也为零。
为了解决这个问题提出了贝叶斯估计。
贝叶斯估计: 即在求先验概率的时候引入了参数
,对其公式进行了如下修改
一、如果
=0,就是一般的极大似然估计
二、如果
=1,成为拉普拉斯平滑

相关文章推荐
- 【学习笔记】斯坦福大学公开课(机器学习) 之生成学习算法:朴素贝叶斯
- 朴素贝叶斯算法学习 (一)
- 朴素贝叶斯算法学习应用
- 【分类】朴素贝叶斯算法学习
- 贝叶斯算法学习
- 机器学习3朴素贝叶斯
- 【机器学习-斯坦福】学习笔记6 - 朴素贝叶斯
- 《机器学习实战》代码片段学习3 朴素贝叶斯
- 挖掘算法(1)朴素贝叶斯算法
- 朴素贝叶斯算法详解
- 机器学习实战学习笔记(三):朴素贝叶斯
- 数据挖掘经典算法复现:朴素贝叶斯
- 《机器学习实战》学习笔记--朴素贝叶斯
- 机器学习实战 朴素贝叶斯
- 分类算法:朴素贝叶斯
- 机器学习实战笔记(Python实现)-03-朴素贝叶斯
- 机器学习-斯坦福:学习笔记6-朴素贝叶斯
- 朴素贝叶斯算法与贝叶斯估计
- 文本分类算法--朴素贝叶斯
- 朴素贝叶斯算法