Pig系统分析(3)-从Pig Latin到Logical plan
2014-04-23 15:30
204 查看
Pig基于Antlr进行语法解析,生成逻辑执行计划。逻辑执行计划基本上与Pig Latin中的操作步骤一一对应,以DAG形式排列。
以下面代码(参考Pig
Latin paper at SIGMOD 2008)为例进行分析,包含了load、filter、join、group、foreach、count函数和stroe等常用操作。
生成的逻辑执行计划如下


Pig不仅仅使用 Anltr生成的词法分析器和语法分析器,校验用户输入合法性(AstValidator)。还同时做了两件事情(antlr具体细节不在此展开)
1) 在语法文件中嵌入动作,加入Java代码,对表达式做进一步处理。
2) 使用了Antlr 的抽象语法树语法,在语法分析的同时将用户输入转换成抽象语法树,如
下图是JOIN语句语法规则的可视化表示

Parse时序图如下(省略了宏展开,用户REGISTER语句替换等细节,其中QueryLexer,QueryParser和AstValidator都是antlr生成的类):
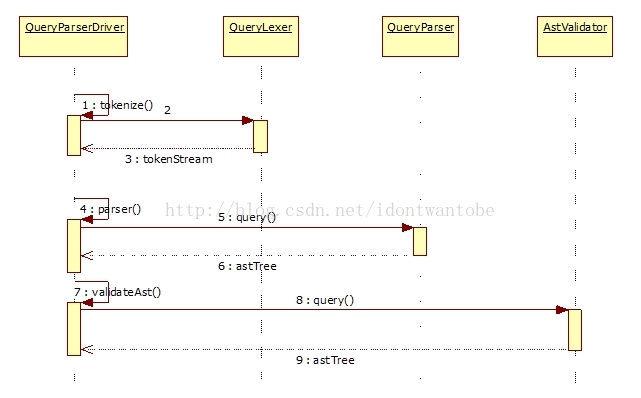
在本节开始图4中的运行Pig Latin程序中,每次调用pigServer.registerQuery方法,注册一个查询语句,Pig都会启动解析、验证步骤,然后调用LogicalPlanGenerator.query()方法,生成该条语句对应的逻辑执行子计划。直到调用pigServer.store方法,才会生成一个完整的逻辑执行计划,触发下一阶段操作。
以上过程信息,包括最后完成的逻辑执行计划都存储在PigServer的private GraphcurrDAG成员变量中,如果在更复杂的批量执行模式下,比如脚本里边调用其他脚本,需要队列来进行存储。
其中currDAG中存储的具体信息如下:lp代表完整的逻辑执行计划,operator可以理解为计划中的特定步骤,它们的关系和内部结构将在下一节介绍。

LogicalPlan继承自BaseOperatorPlan,如下面代码片段所示,LogicalPlan由一系列Operator组成,fromEdges和toEdges代表有向图的出边和入边,PlanEdge内部实际是一个MultiMap<Operator, Operator>数据结构。

在Parse过程中,LogicalPlanBuilder负责构建Operator。Operator中包含名称、Schema、包装成LogicalExpressionPlan的运行参数等信息(以及requestedParallelism、mCustomPartitioner等用户自定义的Hadoop MapReduce运行配置信息)。
以下面代码(参考Pig
Latin paper at SIGMOD 2008)为例进行分析,包含了load、filter、join、group、foreach、count函数和stroe等常用操作。
PigServer pigServer = new PigServer(ExecType.LOCAL);
pigServer.registerQuery("A = load 'file1' as (x,y,z);");
pigServer.registerQuery("B = load 'file2' as (t,u,v);");
pigServer.registerQuery("C = filter A by y>0;");
pigServer.registerQuery("D = join C by x,B by u;");
pigServer.registerQuery("E = group D by z;");
pigServer.registerQuery("F = foreach E generate group,COUNT(D);");
pigServer.explain("F", "dot", true, false, System.out, System.out,
System.out);
pigServer.store("F", "output");生成的逻辑执行计划如下
Parse过程
QueryLexer.g和QueryParser.g分别是Pig Latin使用的词法文件和语法文件。Pig不仅仅使用 Anltr生成的词法分析器和语法分析器,校验用户输入合法性(AstValidator)。还同时做了两件事情(antlr具体细节不在此展开)
1) 在语法文件中嵌入动作,加入Java代码,对表达式做进一步处理。
2) 使用了Antlr 的抽象语法树语法,在语法分析的同时将用户输入转换成抽象语法树,如
foreach_plan_complex : LEFT_CURLY nested_blk RIGHT_CURLY-> ^( FOREACH_PLAN_COMPLEX nested_blk )
下图是JOIN语句语法规则的可视化表示
Parse时序图如下(省略了宏展开,用户REGISTER语句替换等细节,其中QueryLexer,QueryParser和AstValidator都是antlr生成的类):
Logical Plan生成过程
LogicalPlanGenerator.g是一个树分析器文件,antlr生成LogicalPlanGenerator.java文件,实现org.antlr.runtime.tree.TreeParser接口,会对QueryParser.g对应的抽象语法树进行语义处理,用来生成逻辑执行计划(antlr具体细节不在此展开)。在本节开始图4中的运行Pig Latin程序中,每次调用pigServer.registerQuery方法,注册一个查询语句,Pig都会启动解析、验证步骤,然后调用LogicalPlanGenerator.query()方法,生成该条语句对应的逻辑执行子计划。直到调用pigServer.store方法,才会生成一个完整的逻辑执行计划,触发下一阶段操作。
以上过程信息,包括最后完成的逻辑执行计划都存储在PigServer的private GraphcurrDAG成员变量中,如果在更复杂的批量执行模式下,比如脚本里边调用其他脚本,需要队列来进行存储。
/* * The data structure to support gruntshell operations. * The grunt shell can only work on onegraph at a time. * If a script is contained inside anotherscript, the grunt * shell first saves the current graph onthe stack and works * ona new graph. After the nested script is done, the grunt * shell pops up the saved graph andcontinues working on it. */ protected finalDeque<Graph> graphs = new LinkedList<Graph>();
其中currDAG中存储的具体信息如下:lp代表完整的逻辑执行计划,operator可以理解为计划中的特定步骤,它们的关系和内部结构将在下一节介绍。
Logical Plan结构
下面是完整的逻辑执行计划,可以观察到自底而上,分别对应最初是的Load操作和最后的Store操作。#-----------------------------------------------
# New Logical Plan:
#-----------------------------------------------
F: (Name: LOStore Schema:group#38:bytearray,#47:long)
|
|---F: (Name: LOForEachSchema: group#38:bytearray,#47:long)
| |
| (Name: LOGenerate[false,false] Schema: group#38:bytearray,#47:long)
| | |
| | group:(Name: Project Type:bytearray Uid: 38 Input: 0 Column: (*))
| | |
| | (Name:UserFunc(org.apache.pig.builtin.COUNT) Type: long Uid: 47)
| | |
| | |---D:(Name: Project Type: bagUid: 44 Input: 1 Column: (*))
| |
| |---(Name: LOInnerLoad[0] Schema: group#38:bytearray)
| |
| |---D: (Name: LOInnerLoad[1] Schema:C::x#36:bytearray,C::y#37:bytearray,C::z#38:bytearray,B::t#41:bytearray,B::u#42:bytearray,B::v#43:bytearray)
|
|---E: (Name: LOCogroup Schema:group#38:bytearray,D#44:bag{#50:tuple(C::x#36:bytearray,C::y#37:bytearray,C::z#38:bytearray,B::t#41:bytearray,B::u#42:bytearray,B::v#43:bytearray)})
| |
| C::z:(Name: Project Type: bytearray Uid: 38 Input: 0 Column: 2)
|
|---D: (Name: LOJoin(HASH) Schema:C::x#36:bytearray,C::y#37:bytearray,C::z#38:bytearray,B::t#41:bytearray,B::u#42:bytearray,B::v#43:bytearray)
| |
| x:(Name: Project Type: bytearray Uid: 36 Input: 0 Column: 0)
| |
| u:(Name: Project Type: bytearray Uid: 42 Input: 1 Column: 1)
|
|---C: (Name: LOFilter Schema:x#36:bytearray,y#37:bytearray,z#38:bytearray)
| | |
| | (Name: GreaterThan Type:boolean Uid: 40)
| | |
| | |---(Name: Cast Type: int Uid:37)
| | | |
| | | |---y:(Name: Project Type: bytearray Uid: 37Input: 0 Column: 1)
| | |
| | |---(Name: Constant Type: intUid: 39)
| |
| |---A: (Name: LOLoad Schema:x#36:bytearray,y#37:bytearray,z#38:bytearray)RequiredFields:null
|
|---B: (Name: LOLoad Schema:t#41:bytearray,u#42:bytearray,v#43:bytearray)RequiredFields:nullLogicalPlan继承自BaseOperatorPlan,如下面代码片段所示,LogicalPlan由一系列Operator组成,fromEdges和toEdges代表有向图的出边和入边,PlanEdge内部实际是一个MultiMap<Operator, Operator>数据结构。
public abstract class BaseOperatorPlan implements OperatorPlan {
protected List<Operator> ops;
protected PlanEdge fromEdges;
protected PlanEdge toEdges;
……
}Operator对应逻辑执行计划中的具体操作步骤。Pig为每种操作都实现了相应的Operator。在Parse过程中,LogicalPlanBuilder负责构建Operator。Operator中包含名称、Schema、包装成LogicalExpressionPlan的运行参数等信息(以及requestedParallelism、mCustomPartitioner等用户自定义的Hadoop MapReduce运行配置信息)。

相关文章推荐
- Pig系统分析(7)-Pig实用工具类
- Bonfire: Pig Latin
- Pig系统分析(8)-Pig可扩展性
- piglatin.php源代码分析
- Pig Latin JOIN (inner) 与JOIN (outer)的区别
- UVa 492 - Pig-Latin
- uva 492 Pig_Latin 题目详解及面向过程,面向对象的编程思想的粗略讲解
- Pig Latin JOIN (inner) 与JOIN (outer)的区别
- pig latin 简介
- Pig系统分析(5)-从Logical Plan到Physical Plan
- Pig Latin数据类型
- 开始玩hadoop13--pig (latin)和Hive
- Pig系统分析(5)-从Logical Plan到Physical Plan
- java语言的科学与艺术-PigLatin.java
- Pig系统分析(7)-Pig有用工具类
- codewars-5kyu-Simple Pig Latin:正则表达式的使用
- Pig系统分析(7)-Pig有用工具类
- 和Pig一起学英语
- mysql处理Latin 中文繁体字乱码解决方案
- pig -x local