boosting(AdaBoost)算法
2014-04-23 10:54
218 查看
本文只是对算法的步骤进行简单的介绍和解释,以求对算法步骤有个直观的了解,没有对算法进行性能分析。
1、bagging算法
bagging算法来源于boosttrsp aggregation(自助聚类),表示过程主要如下:从大到小为n的原始数据集D中,分别独立随机地抽取n‘个数据(n'<n)形成数据集,并且将这个过程独立许多次,直到产生很多个独立的数据集。然后,每个数据集都被独立地用于训练一个“分量分类器”。最终的分类判决将根据这些“分量分类器”各自的判决结果的投票决定。
2、boosting算法
boosting算法的目的是提高任何给定的学习算法的分类准确率。在boosting算法中,我们先根据已有的训练样本集设计一个分类器,要求这个分类器的准确率比平均性能要好。然后,依次顺序地加入多个分量分类器系统,最后形成一个总体分类器。最终的判决结果根据分类器的结果共同决定。
以一个两类问题创建三分量分类器为例:首先,从大小为n的原始样本集D中不放回地随机抽取n1个样本点,组成样本集D1,然后根据D1训练出第一个分类器C1(只要比瞎猜准确率高就好,当然这是最低要求)。然后选取C1中最富信息的样本点组成D2,D2中的一般样本应该能被C1正确分类,另外一半则被错分。具体为:可以采用抛硬币法,当为正面的时候,就从D中剩余样本中选取样本送入C1,如果分类正确,则被舍弃,继续选样本点,如果分类错误,把错误的样本送入D2,本次过程结束,继续抛硬币。如果为反面,就从C1正确分类的样本点中挑选一个送入D2。这样,D2中就有一半的样本是C1正确分类,一半的样本是C1错误分类的。继续构造D3,仍然是在D中剩余样本中选取样本点,分别送入C1和C2进行分类,如果分类一致就舍弃,如果判决不一致,,就送入D3。然后又用D3训练分类器C3。
下面就可以对新样本a进行分类了。如果C1和C2的判决结果相同,就把a判决为这个类别,如果判决结果不同,就采用C3判决的判决结果。
3、AdaBoost
基于boosting有许多变形,AdaBoost就是其中一种,该方法允许设计者不断加入新的弱分类器,直到达到某个预定的足够小的误差率。我们使用xi和yi表示原始样本集中D中样本点和他们的标记。用wk(i)表示第k次迭代的全体样本权重分布。算法流程如下:

下面我们举一个简单的例子来看看Adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。

第一步:


根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:


根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:


得到一个子分类器h3
整合所有子分类器:

因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果。

1、bagging算法
bagging算法来源于boosttrsp aggregation(自助聚类),表示过程主要如下:从大到小为n的原始数据集D中,分别独立随机地抽取n‘个数据(n'<n)形成数据集,并且将这个过程独立许多次,直到产生很多个独立的数据集。然后,每个数据集都被独立地用于训练一个“分量分类器”。最终的分类判决将根据这些“分量分类器”各自的判决结果的投票决定。
2、boosting算法
boosting算法的目的是提高任何给定的学习算法的分类准确率。在boosting算法中,我们先根据已有的训练样本集设计一个分类器,要求这个分类器的准确率比平均性能要好。然后,依次顺序地加入多个分量分类器系统,最后形成一个总体分类器。最终的判决结果根据分类器的结果共同决定。
以一个两类问题创建三分量分类器为例:首先,从大小为n的原始样本集D中不放回地随机抽取n1个样本点,组成样本集D1,然后根据D1训练出第一个分类器C1(只要比瞎猜准确率高就好,当然这是最低要求)。然后选取C1中最富信息的样本点组成D2,D2中的一般样本应该能被C1正确分类,另外一半则被错分。具体为:可以采用抛硬币法,当为正面的时候,就从D中剩余样本中选取样本送入C1,如果分类正确,则被舍弃,继续选样本点,如果分类错误,把错误的样本送入D2,本次过程结束,继续抛硬币。如果为反面,就从C1正确分类的样本点中挑选一个送入D2。这样,D2中就有一半的样本是C1正确分类,一半的样本是C1错误分类的。继续构造D3,仍然是在D中剩余样本中选取样本点,分别送入C1和C2进行分类,如果分类一致就舍弃,如果判决不一致,,就送入D3。然后又用D3训练分类器C3。
下面就可以对新样本a进行分类了。如果C1和C2的判决结果相同,就把a判决为这个类别,如果判决结果不同,就采用C3判决的判决结果。
3、AdaBoost
基于boosting有许多变形,AdaBoost就是其中一种,该方法允许设计者不断加入新的弱分类器,直到达到某个预定的足够小的误差率。我们使用xi和yi表示原始样本集中D中样本点和他们的标记。用wk(i)表示第k次迭代的全体样本权重分布。算法流程如下:
下面我们举一个简单的例子来看看Adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
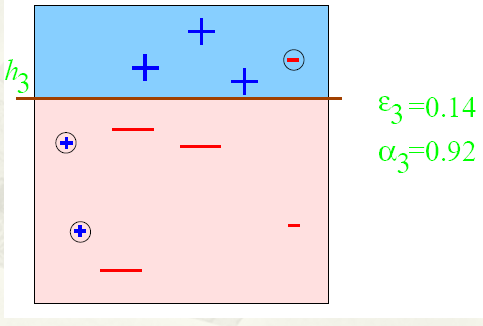
得到一个子分类器h3
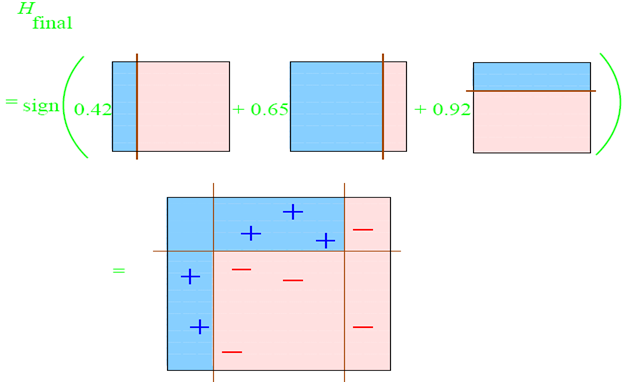
整合所有子分类器:
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果。

相关文章推荐
- AdaBoost(Adaptive Boosting 自适应提升)算法
- Adaboost 算法的原理与推导(简单易懂)
- Adaboost 算法的原理与推导
- 通过源码学算法--AdaBoost (CART): RealAdaBoost.m + tree_node_w.m
- 集成学习算法总结----Boosting和Bagging(转)
- AdaBoost中利用Haar特征进行人脸识别算法分析与总结2——级联分类器与检测过程
- GBDT(Gradient Boosting Decision Tree)算法&协同过滤算法
- Adaboost 算法的原理与推导(读书笔记)
- 【算法】bootstrap, boosting, bagging 几种方法的联系
- Adaboost 算法的原理与推导
- 基础算法之模型组合(Model Combining)之Boosting与Gradient Boosting
- PRML读书会第十四章 Combining Models(committees,Boosting,AdaBoost,决策树,条件混合模型)
- aggregation(2):adaptive Boosting (AdaBoost)
- 机器学习技法总结(五)Adaptive Boosting, AdaBoost-Stump,决策树
- boosting-adaboost、GBDT、xgboost、lightGBM
- Adaboost(自适应提升树)算法原理
- 浅谈 Adaboost 算法
- 机器学习经典算法详解及Python实现--元算法、AdaBoost
- 转载——Adaboost 算法 人脸检测原理
- 机器学习:集成算法(随机森林,Adaboost)