计算机中结构体的内存对齐问题
2014-04-15 22:23
330 查看
#include<stdio.h>
//#pragma pack(4)
int main()
{
struct key
{
int a;//4 bytes
char b;//1 bytes
long double c;//8 bytes
char d;//1 bytes
}k0;
struct key1
{
int a;
char b;
int c;
}k1;
struct key2
{
char a;
char b;
char c;
}k2;
//printf("the size of certain type is: %d\n",sizeof(kk.a));
printf("%d\n",sizeof(struct key));
printf("%d\n",sizeof(struct key1));
printf("%d\n",sizeof(struct key2));
printf("%p %p %p %p\n",&k0.a, &k0.b, &k0.c, &k0.d);
printf("%p %p %p\n",&k1.a, &k1.b, &k1.c);
printf("%p %p %p\n",&k2.a, &k2.b, &k2.c);
//system("pause");
return 0;
}先看上面一段代码,猜想一下输出结果会是什么?(代码中注释给出了此种机器中各个类型的变量的大小)可能有人会写出下面的结果:
14
9
3
事实是不是这样呢?请看这段代码在VS2010上的运行结果:
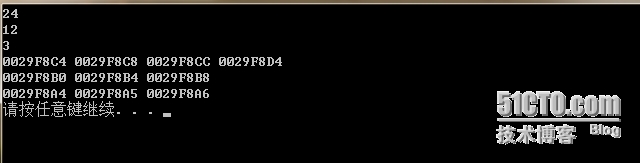
这究竟是为什么呢?这个问题也困扰了笔者很久,经过查资料后,终于明白这是一个内存对齐的问题。下面先简单介绍一下计算机为什么要进行内存对齐,然后再介绍怎么进行内存对齐。
1.平台原因:不是所有的硬件平台都能访问任意地址上的任意数据的,某些平台只能在某些地方读取某些数据,否则会抛出硬件异常。2.性能原因:经过内存对齐后,cpu访问内存的速度大大提高。对于第二个原因作出的解释是:一般人心中的内存印象是这样的:

一个字节一个字节组成的内存,但是cpu不这样认为,cpu“脑”中的内存是这样的:

cpu把内存看成是一块一块的,以2,4,8,16为单位进行读取的。下面简单举一个例子:假设cpu要读取一个4字节大小的数据到寄存器中,分两种情况进行讨论:1.数据从0字节开始 2.数据从1字节开始两种情况如图所示

当cpu从0字节开始读取的时候,只需要读取一次即可把这4字节的内容读取到寄存器中;当cpu从1字节开始读取数据的时候,显然问题开始变得复杂,因为此时数据不在内存读取边界上,这是一类内存未对齐的数据。此时内存先访问一次内存,读取0-3字节数据到寄存器,并且再次读取4-7字节数据到寄存器中,接着把0字节和6,7,8字节的内容删掉,然后合并1.2.3.4字节的数据进寄存器,如下图所示:
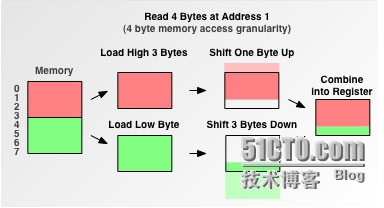
显然相比第一种情况而言,cpu进行了很多额外的操作,大大降低了cpu的性能。以上大概解释了计算机为什么要进行内存对齐,接下来介绍内存对齐的原理和实现。每个特定平台上的编译器都有自己默认的“对齐系数”(也叫对齐模数)。程序员可以通过预编译命令#pragma pack(n) n=1.2.4.8.16来改变这一系数,其中的n就是你要指定的“对齐系数”。数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中比较小的那个进行。结构体的整体对齐规则:数据成员完成对齐后,结构体本身也要进行整体对齐,对齐按照#pragma pack指定的数值和结构最大数据成员的长度中比较小的那个进行。下面我们开始分析此文开始时的代码:
在结构体k0中最大数据成员的长度是8字节,故以8为对齐系数,a占4字节,后面会有4字节的空间,b长度为1字节,所以b会填充到a后面,c占8字节,d占1字节,后面会有7字节的空间,编译器会将其填充成8字节,所以k0的大小就是3*8字节,即24;在结构体k1中最大数据成员的长度是4字节,故以4为对齐系数,a占4字节,b占1字节后面会有3字节的空间,编译器会将其填充到4字节,c占4字节,故结构体k1的大小3*4字节,即12;同理可得k2的大小3.分析上面结构体数据成员的地址,根据地址我们显然可以得出此结果完全符合上面的分析。

相关文章推荐
- C语言&nbsp;结构体的内存对齐问题与位域
- 关于VC下结构体内存对齐问题
- C语言&nbsp;结构体的内存对齐问题与位域
- 关于结构体内存对齐的问题
- 结构体的内存对齐问题与位域
- Arm结构体gcc内存边界对齐问题(zt)
- C++面试题之结构体内存对齐计算问题总结大全
- 结构体内存对齐问题
- 解析C语言结构体对齐(内存对齐问题)
- 结构体内存对齐问题
- C语言 结构体的内存对齐问题与位域
- 结构体中内存对齐问题
- 结构体内存对齐问题(附案例解析)c语言
- 计算机大端模式和小端模式 内存对齐问题(sizeof)
- [面试] 结构体占用空间的问题,内存对齐~! 真的懂了,cpu取加快速度,省空间来考虑。
- 结构体的内存对齐问题
- gcc 中结构体(struct)内存对齐问题分析
- [面试] 结构体占用空间的问题,内存对齐~! 真的懂了,cpu取加快速度,省空间来考虑。
- 32位和64位下结构体内存对齐问题
- 【C语言】结构体中的内存对齐问题