Lucene学习笔记
2014-04-10 20:55
459 查看
Lucene学习笔记
Lucene的概述:
1.1 什么是lucenehttp://cloudera.iteye.com/blog/656459
这是一篇很好的文章。下面便是取自这里。
Lucene是一个全文搜索框架,而不是应用产品。因此它并不像http://www.baidu.com/ 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
1.2 lucene能做什么
要回答这个问题,先要了解lucene的本质。实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了。你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;你也可以写个自己的搜索引擎……
1.3 你该不该选择lucene
下面给出一些测试数据,如果你觉得可以接受,那么可以选择。
测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms。
测试二:37000记录,索引数据库中的两个varchar字段,索引文件2.6M,800线程下平均处理时间1.5ms。
2 lucene的工作方式
lucene提供的服务实际包含两部分:一入一出。所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
2.1写入流程
源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword(可选)。
将源中需要的信息加入Document的各个Field中,并把需要索引的Field索引起来,把需要存储的Field存储起来。
将索引写入存储器,存储器可以是内存或磁盘。
2.2读出流程
用户提供搜索关键词,经过analyzer处理。
对处理后的关键词搜索索引找出对应的Document。
用户根据需要从找到的Document中提取需要的Field。
3 一些需要知道的概念
lucene用到一些概念,了解它们的含义,有利于下面的讲解。
3.1 analyzer
Analyzer 是分析器,它的作用是把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语,这里说的无效词语是指英文中的“of”、 “the”,中文中的 “的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。
分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。具体划分方法下面再详细介绍,这里只需了解分析器的概念即可。
3.2 document
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。
3.3 field
一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,下面举例说明:
还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为真,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为真,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为假,当需要时再直接读取文件;我们只是希望能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为真,索引属性设置为假。上面的三个域涵盖了两个属性的三种组合,还有一种全为假的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
3.4 term
term是搜索的最小单位,它表示文档的一个词语,term由两部分组成:它表示的词语和这个词语所出现的field。
3.5 tocken
tocken是term的一次出现,它包含trem文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个term表示,但是用不同的tocken,每个tocken标记该词语出现的地方。
3.6 segment
添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。
4 lucene的结构
lucene包括core和sandbox两部分,其中core是lucene稳定的核心部分,sandbox包含了一些附加功能,例如highlighter、各种分析器。 Lucene core有七个包:analysis,document,index,queryParser,search,store,util。对于4.5版本不是这7个包,而是如下:
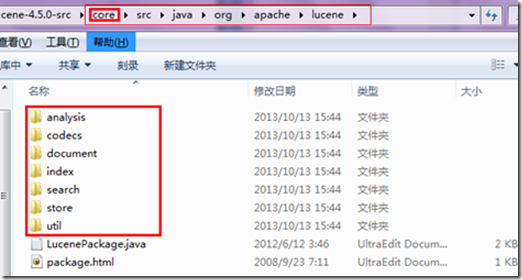
关于这些的详细介绍,后面再说。
环境的准备:
1. 先下载开发的jar包:http://lucene.apache.org/
http://apache.dataguru.cn/lucene/java/4.5.0/

我们把zip和src下载下来就可以了。
2. 对于开源的框架,一般使用都有2个步骤
a) 添加jar包
为了项目的可移植性,我们应该建立一个lib文件夹,专门放外部的jar包,然后把需要的jar包放入到这个目录,最后在链接进项目里面
b) 配置文件
3. 根据开发文档搭建环境
a) 先读readme文件,他会告诉你怎么用,告诉你这项目是什么
b) 再根据a)的指导,读取相应的文件,也就是docs/index.html
c) Index只指导我们看demon,于是只能网上搜索demo怎么用
下面是demon的使用方法:
http://blog.csdn.net/wyj0613/article/details/12318825
我们按照这个做法做就是了(预告:最后没有找到怎么搭建工程的方法)
i) 定义环境变量:CLASSPATH的值如下:
D:\soft_framework_utiles\lucene-4.5.0\lucene-4.5.0\core\lucene-core-4.5.0.jar;
D:\soft_framework_utiles\lucene-4.5.0\lucene-4.5.0\demo\lucene-demo-4.5.0.jar;D:\soft_framework_utiles\lucene-4.5.0\lucene-4.5.0\queryparser\lucene-queryparser-4.5.0.jar;
D:\soft_framework_utiles\lucene-4.5.0\lucene-4.5.0\analysis\common\lucene-analyzers-common-4.5.0.jar;
把这个4个jar放进去就是了。
j) 开始测试demonà建立索引
java org.apache.lucene.demo.IndexFiles -index [index folder] -docs[docs folder]
设置要生成的索引的文件夹和要解析的docs
我们的doc目录用:demo\lf_test_docs_dir
生成的index目录用:demo\lf_test_index_dir
下面就是执行过程:
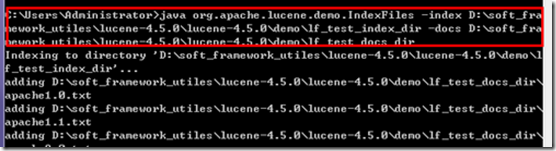
我们可以去看index目录的生成的文件:

k) 开始测试demonà执行查询
java org.apache.lucene.demo.SearchFiles
将会出现“Query:”提示符,在其后输入关键字,回车,即可得到查询结果

由于SearchFiles是查找当前目录下面的index目录作为索引文件目录,所以这
里报错了,我们可以用-index参数指定我们的index目录:
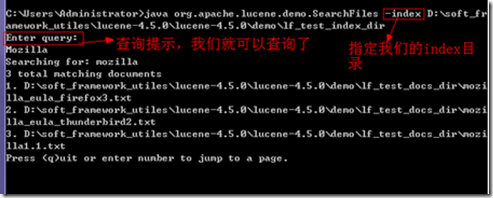
可以看到查询mozilla得到3个文档有这个关键字。
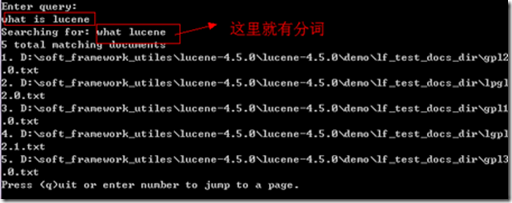
4. 到教学的东西,那么我们就查资料吧,下面是做法
需要的jar包是:
Ø lucene-core-4.5.0.jar 核心包
Ø lucene-analyzers-common-4.5.0.jar 分词器
Ø lucene-highlighter-4.5.0.jar 高亮器
添加到项目buildpath:

如下显示就对了:
5. 写我们自己的代码了
先生成索引:(代码插件挺好用啊)
Document document = LuceneUtiles.getDocument(filePath);
// 存放索引的目录
Directory indexDirectory = FSDirectory.open(new File(indexPath));
// 这里默认使用的模式是:openMode = OpenMode.CREATE_OR_APPEND;
// IndexWriterConfig的父类构造是初始化的
IndexWriterConfig indexWriterConfig = new
IndexWriterConfig(Version.LUCENE_45, analyzer);
//索引的维护是用IndexWriter来做的,把doc添加进去,更新,删除就行了
IndexWriter indexWriter = new
IndexWriter(indexDirectory,indexWriterConfig);
indexWriter.addDocument(document);
// 所有io操作的,最后都应该关闭,比如file,network,database等
indexWriter.close();
查询:
public void searchFromIndex() throws IOException
{
// 只能全小写才可以!因为我们term没有经过分词器处理!
// 所以只能用直接跟索引库的关键字一一对应的值
// 以后讲解把索引字符串也处理的方法
String queryString = "binary";
// 1.收索字符串--->Query对象
Query query = null;
{
// 注意:
// 因为文件在建立索引的时候(分词器那里),就已经做了一次大小写转换了,
// 存的索引全是小写的
// 而我们这里搜索的时候没有通过分词器,所以我们的数据没有转化,
// 那么如果这里是大写类型就搜不到任何东西!!!
Term term = new Term("fileContent",queryString);
// 至于这里用什么Query,以后再说
query = new TermQuery(term);
}
// 2.进行查询
TopDocs topDocs = null;
IndexSearcher searcher = null;
IndexReader indexReader = null;
{
// 指定索引的文件位置
indexReader = DirectoryReader.open(FSDirectory.open(new
File(indexPath)));
searcher = new IndexSearcher(indexReader);
Filter filter = null;
// 搜索
// 过滤器,可以过滤一些文件,null就是不用过滤器
// 数字代表每次查询多少条,也就是一次数据的读取读多少条,
// 1000,10000等比较合适,默认是50
//
topDocs = searcher.search(query, filter, 1000);
}
// 3.打印结果
{
System.out.println(
"总共有【"+topDocs.totalHits+"】条匹配结果");
// 这是返回的数据
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
int docId = topDocs.scoreDocs[i].doc;
Document hittedDocument = searcher.doc(docId);
LuceneUtiles.print(hittedDocument);
}
}
indexReader.close();
}6. 讲解
点击类名,使用ctrl+T实现查询该类的子类,即继承关系!
下面是Lucene的大体结构图:
原理是先把文章根据需求用分词器拆分,然后建立好每一个关键词到文章的映射关系,这就是索引表,索引表存放的就是关键字到文章的映射,注意这里的映射不是直接就持有了对应的文章,而是持有的内部对文章编号的一个id。所以索引是关键字到文章Id的一个映射。
当用户查询时,也用之前的分词器,把查询分词,然后每一个词都挨着找索引,把匹配的返回出来就完毕了。

(别人的图片)
a) Analysis:分词器
Analysis包含一些内建的分析器,例如按空白字符分词的WhitespaceAnalyzer,添加了stopwrod过滤的StopAnalyzer,最常用的StandardAnalyzer。
b) Documet:文档
就是我们的源数据的封装结构,我们需要把源数据分成不同的域,放入到documet里面,到时搜索时也可以指定搜索哪些域(Field)了。
c) Directory : 目录,这是对目录的一个抽象,这个目录可以是文件系统上面的一个dir(FSDirectory),也可以是内存的一块(RAMDirectory),MmapDirectory为使用内存映射的索引。
放在内存的话就会避免IO的操作耗时了,根据需要选择就是了。
d) IndexWriter : 索引书写器,也就是维护器,对索引进行读取和删除操作的类
e) IndexReader : 索引读取器,用于读取指定目录的索引。
f) IndexSearcher : 索引的搜索器,就是把用户输入拿到索引列表中搜索的一个类
需要注意的是,这个搜索出来的就是(TopDocs)索引号,还不是真正的文章。
g) Query : 查询语句,我们需要把我们的查询String封装成Query才可以交给Searcher来搜索 ,查询的最小单元是Term,Lucene的Query有很多种,根据不同的需求选用不同的Query就是了.
i. TermQuery:
如果你想执行一个这样的查询:“在content域中包含‘lucene’的document”,那么你可以用TermQuery:
Term t = new Term("content", " lucene");
Query query = new TermQuery(t);ii. BooleanQuery:多个query的【与或】关系的查询
如果你想这么查询:“在content域中包含java或perl的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
TermQuery termQuery1 = new TermQuery(new Term("content", "java");
TermQuery termQuery 2 = new TermQuery(new Term("content", "perl");
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(termQuery1, BooleanClause.Occur.SHOULD);
booleanQuery.add(termQuery2, BooleanClause.Occur.SHOULD);iii. WildcardQuery : 通配符的查询
如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’use*’,你可能找到’useful’或者’useless’:
Query query = new WildcardQuery(new Term("content", "use*");
iv. PhraseQuery : 在指定的文字距离内出现的词的查询
你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,你可以:
PhraseQuery query = new PhraseQuery();
query.setSlop(5);
query.add(new Term("content ", “中”));
query.add(new Term(“content”, “日”));
那么它可能搜到“中日合作……”、“中方和日方……”,但是搜不到“中国某高层领导说日本欠扁”。
v. PrefixQuery : 查询词语是以某字符开头的
如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
PrefixQuery query = new PrefixQuery(new Term("content ", "中");
vi. FuzzyQuery : 相似的搜索
FuzzyQuery用来搜索相似的term,使用Levenshtein算法。假设你想搜索跟‘wuzza’相似的词语,你可以:
Query query = new FuzzyQuery(new Term("content", "wuzza");
你可能得到‘fuzzy’和‘wuzzy’。
vii. TermRangeQuery : 范围内搜索
你也许想搜索时间域从20060101到20060130之间的document,你可以用TermRangeQuery:
TermRangeQuery query2 = TermRangeQuery.newStringRange("time", "20060101", "20060130", true, true);
最后的true表示用闭合区间。
viii.
h) TopDocs :结果集,就是searcher搜索的结果,里面就是一些ScoreDoc,这个对象的doc成员就是这个Id了!
要想得到文章,那么就得需要用这个Id去取文章了,searcher提供了用id得到document的方法,于是就取到了数据了
i)
7.
使用多个Directory
因为我们知道了FSDirectory是从文件系统的目录中读取数据,我们总不可能每次查询都从文件中读取一次索引吧,所以我们的做法应该是程序启动时就把所以载入到内存,退出时再回写,如下面的示意图:
(也是别人的图片)
使用内存的目录:RAMDirectory
这样可以加快访问速度/**
* 测试使用RAMDirectroy,也就是把生成的索引写到内存而不是磁盘.
* 运行这个方法,不报错就代表成功了。
* 平时我们是把索引文件写道文件系统的,这里就是写道RAM中,以后读取也
* 可以在这个目录读取,快速!
* @throws IOException
*/
@Test
public void testWriteInToRam() throws IOException
{
Directory directory = new RAMDirectory();
IndexWriterConfig config =
new IndexWriterConfig(Version.LUCENE_45, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
indexWriter.addDocument(LuceneUtiles.getDocument(filePath));
indexWriter.close();
}
从文件系统的目录载入到ram中,然后进行操作,最后保存回去
下面是实例代码:/**
* 从磁盘的索引文件中读取放入到RAM目录,
* 然后进行一系列的其他操作。
* 退出时再把RAM的写回文件系统。
* @throws IOException
*/
@Test
public void testLoadIntoRamAndWriteBacktoFS() throws IOException
{
// 1.启动时载入
Directory fsDir = FSDirectory.open(new File(indexPath));
RAMDirectory ramDir = new RAMDirectory(fsDir,new IOContext());
// 中途操作内存中的数据
IndexWriterConfig ramIndexWriterConfig =
new IndexWriterConfig(Version.LUCENE_45, analyzer);
IndexWriter ramIndexWriter =
new IndexWriter(ramDir, ramIndexWriterConfig);
// 添加一个文件,这好像没有写进去!!!!!!!
// 不是没写进去,而是这个方法没有执行!因为test方法一定要加@Test注解!
ramIndexWriter.addDocument(
LuceneUtiles.getDocument(filePath));
ramIndexWriter.close();//要先关闭,因为还有缓存。
// 2.退出时保存写回,因为默认是CREATE_OR_APPEND
// 所以这里就会把AABBCC读出来之后,加上DD
// 那么写回去的数据时AABBCCDD,但是已经本地有存储了,
// 所以是append的方式,于是最后的结果是
// AABBCCAABBCCDD,就是重复的了。可以search同一个关键字,
// 看结果数量就知道了
// 会1条变3条,3条变7条,这种*2+1的形式
//
// 我们可以每次都重写,就能解决了
IndexWriterConfig fsIndexWriterConfig =
new IndexWriterConfig(Version.LUCENE_45, analyzer);
// 设置每次重写
fsIndexWriterConfig.setOpenMode(OpenMode.CREATE);
IndexWriter fsIndexWriter =
new IndexWriter(fsDir, fsIndexWriterConfig);
fsIndexWriter.addIndexes(ramDir);
fsIndexWriter.close();
}
合并索引
因为每添加一个文档的索引,都会建立多个小的文件存放索引,所以文档多了之后,IO操作就很费时间了,于是我们需要合并小文件,每一个小文件就是segment。合并代码如下,需要注意的是:a) 我们不能直接把索引库打开,用Creat_OR_Append的方式强制写回
他会出现叠加的问题
b) 要每次都用Create的方式写回
但是不能再写回自己的目录,因为同一个目录不支持又读又写,必须指定其他的目录
c) 指定其他目录存放Merge的索引,在写回之前,应该把之前的索引添加到IndexWriter中,这样才把会有数据
/**
* 索引库文件优化,貌似没有提供保存优化的接口
* 多半内部封装好的,外界不用管。只有一个强制合并的接口。
* 这就是用于合并。
* @throws IOException
*/
@Test
public void testYouHua() throws IOException
{
Directory fsDirectory_Merged =
FSDirectory.open(new File(indexPathMerged));
Directory fsDirectory = FSDirectory.open(new File(indexPath));
IndexWriterConfig indexWriterConfig =
new IndexWriterConfig(Version.LUCENE_45, analyzer);
indexWriterConfig.setOpenMode(OpenMode.CREATE);
IndexWriter indexWriter =
new IndexWriter(fsDirectory_Merged, indexWriterConfig);
// forceMerge(1)可以把所以的段合并成1个,但是每次都会增加一份,
// 就是像拷贝了一份加入一样
// 难道是该指定OpenMode.CREATE,如果指定了CREATE,
// 但是呢IndexWriter里面没有添加doc索引(即addDoc等方法),
// 所以写进去就编程空索引库了,于是需要先读出来再写回
// 于是还应该把索引加到writer里面
//
// 把自己加入进去,然后再用每次都create的办法保持不会新增
// 注意不能添加到自己,所以还得新建一个库才可以,这样就不会叠加了
indexWriter.addIndexes(fsDirectory);
indexWriter.commit();
indexWriter.forceMerge(1);
indexWriter.close();
}
分词器(Analyzer)
在前面的概念介绍中我们已经知道了分析器的作用,就是把句子按照语义切分成一个个词语。英文切分已经有了很成熟的分析器: StandardAnalyzer,很多情况下StandardAnalyzer是个不错的选择。甚至你会发现StandardAnalyzer也能对中文进行分词。但是我们的焦点是中文分词,StandardAnalyzer能支持中文分词吗?实践证明是可以的,但是效果并不好,搜索“如果” 会把“牛奶不如果汁好喝”也搜索出来,而且索引文件很大。那么我们手头上还有什么分析器可以使用呢?core里面没有,我们可以在sandbox里面找到两个: ChineseAnalyzer和CJKAnalyzer。但是它们同样都有分词不准的问题。相比之下用StandardAnalyzer和 ChineseAnalyzer建立索引时间差不多,索引文件大小也差不多,CJKAnalyzer表现会差些,索引文件大且耗时比较长。
要解决问题,首先分析一下这三个分析器的分词方式。StandardAnalyzer和ChineseAnalyzer都是把句子按单个字切分,也就是说 “牛奶不如果汁好喝”会被它们切分成“牛 奶 不 如 果 汁 好 喝”;而CJKAnalyzer则会切分成“牛奶 奶不 不如 如果 果汁 汁好好喝”。这也就解释了为什么搜索“果汁”都能匹配这个句子。
以上分词的缺点至少有两个:匹配不准确和索引文件大。我们的目标是将上面的句子分解成 “牛奶 不如 果汁好喝”。这里的关键就是语义识别,我们如何识别“牛奶”是一个词而“奶不”不是词语?我们很自然会想到基于词库的分词法,也就是我们先得到一个词库,里面列举了大部分词语,我们把句子按某种方式切分,当得到的词语与词库中的项匹配时,我们就认为这种切分是正确的。这样切词的过程就转变成匹配的过程,而匹配的方式最简单的有正向最大匹配和逆向最大匹配两种,说白了就是一个从句子开头向后进行匹配,一个从句子末尾向前进行匹配。基于词库的分词词库非常重要,词库的容量直接影响搜索结果,在相同词库的前提下,据说逆向最大匹配优于正向最大匹配。
当然还有别的分词方法,这本身就是一个学科,我这里也没有深入研究。回到具体应用,我们的目标是能找到成熟的、现成的分词工具,避免重新发明车轮。经过网上搜索,用的比较多的是中科院的 ICTCLAS和一个不开放源码但是免费的JE-Analysis。ICTCLAS有个问题是它是一个动态链接库, java调用需要本地方法调用,不方便也有安全隐患,而且口碑也确实不大好。JE-Analysis效果还不错,当然也会有分词不准的地方,相比比较方便放心。
下面就是分词器的例子:
/**
* <pre>
* 测试分词器的,分词器分出来的关键字我们叫做Token
* 分词器一般需要完成的工作是:
* 1.词组拆分
* 2.去掉停用词
* 3.大小写转换
* 4.词根还原
*
* 对于中文分词,通常有3种:单词分词,二分法,词典分词。
* 单词分词:就分成一个一个的单个字,比如{@link StandardAnalyzer},
* 如分成 我-们-是-中-国-人
* 二分法分词:按2个字分词,即 我们-们是-是中-中国-国人,实现是是
* {@link CJKAnalyzer}
* 词典分词:按照某种算法构造词,然后把词拿到词典里面找,如果是词,就算对了。
* 这是目前的好用的,可以分词成 我们-中国人,
* 好用的有【极易分词:MMAnalyzer】,还有就是【庖丁分词】目前没有找到适用于4.5的。
* 还有一个牛的,是中科院的。能分出帽子和服装。这些需要外界提供,需要下载jar包
* </pre>
*
* @author LiFeng
*
*/
public class AnalyzerTest {
String enString =
"it must be made available under this Agreement,”+
”for more information : infor.doc";
String zhString = "你好,我是中国人,我的名字是李锋。";
// 这个分词器用于英文的,没有形态还原
// 如果拿去分中文的话,每一个字都被拆开了,测试下就晓得了
Analyzer enAnalyzer = new StandardAnalyzer(Version.LUCENE_45);
// 可以按点分开,没有形态还原
// 对于中文的话,他也只按标点分:你好 我是中国人 我的名字是李锋这3个token
Analyzer simpleAnalyzer = new SimpleAnalyzer(Version.LUCENE_45);
// 分中文就是二分法
// 分英文就是:单词分开就完了
Analyzer cjkAnalyzer = new CJKAnalyzer(Version.LUCENE_45);
// lucene4.5使用je-analysis-1.5.3.jar会崩溃,因为好多都改了
Analyzer jeAnalyzer = new MMAnalyzer();// 词库分词,比如极易
String testString = enString;
Analyzer testAnalyzer = jeAnalyzer;
/**
* 得到分词器拆分出来的关键字(Token)
*
* @throws IOException
*/
@Test
public void testGetTokens() throws IOException {
// 得到分出来的词流
// fileName就是我们当时创建document时一样的意思
// 我们这里是要得到分出的词,跟他要归属哪个filed无关,所以不用管
// 查看enAnalyzer的tokenStream的帮助,他叫们参考:
// See the Analysis package documentation for some examples
// demonstrating this.
// 于是打开对于的文档如下:
// docs/core/org/apache/lucene/analysis/
// package-summary.html#package_description
// 这里面会有例子的!!!
// 下面是文档的例子
{// 分词器把文本分词token流
TokenStream tokenStream = testAnalyzer.tokenStream(
"myfield", new StringReader(testString));
OffsetAttribute offsetAtt =
tokenStream.addAttribute(OffsetAttribute.class);
try {
// Resets this stream to the beginning. (Required)
tokenStream.reset();
while (tokenStream.incrementToken()) {
// 这里传入true就可以看到更详细的信息,调试用很好
// 打印token的信息
System.out.println("token: " +
tokenStream.reflectAsString(false));
// 可以去除token存放的开始和结束
// System.out.println("token start offset: "
// + offsetAtt.startOffset());
// System.out.println(" token end offset: "
// + offsetAtt.endOffset());
}
tokenStream.end();
} finally {
// Release resources associated with this stream.
tokenStream.close();
}
}
}
}
高亮器highlighter
高亮器帮我们做两件事,第一件就是搜索结果的摘要,第二件事就是整体内容的关键字高亮。高亮的原理就是在关键字周围加上html标签就是了。
String indexPath = "D:\\WorkspacesForAll\\Lucene\\Lucene-00010-HelloWorld\\lf_index";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_45);
@Test
public void testHightlight() throws IOException,
InvalidTokenOffsetsException
{
// 查询fileContent字段的reproduce关键字
// 这里的filed指定就是用于找到符合的document
// 在高亮器初始化的时候Scorer类也用到了这个query
// 其实过程就是:
// 1.先把某个域出现关键字的doc全部找出来
// 2.再用高亮器,在找到的文章中,
// 把指定域的内容提取一部分有关键字的文本,加上高亮就完毕了
Query query = new TermQuery(
new Term("fileContent", "reproduce"));
// 高亮器的初始化准备
Highlighter highlighter = null;
{
Formatter formatter = new SimpleHTMLFormatter(
"<font color='red'>", "</font>");
Scorer fragmentScorer = new QueryScorer(query);
highlighter = new Highlighter(formatter, fragmentScorer);
// 摘要只取50个字符
Fragmenter fragmenter = new SimpleFragmenter(50);
highlighter.setTextFragmenter(fragmenter);
}
IndexReader indexReader = DirectoryReader.open(
FSDirectory.open(new File(indexPath)));
IndexSearcher searcher = new IndexSearcher(indexReader);
TopDocs topDocs = searcher.search(query, null, 1000);
System.out.println("找到【"+topDocs.totalHits+"】个:");
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
int docId = topDocs.scoreDocs[i].doc;
Document document = searcher.doc(docId);
// 用高亮器返回摘要
// 参数1就是用指定的分词器,
// 参数2目前不知道咋用
// 参数3就是我们需要处理哪一段文本的数据,把这段文件实现高亮并返回摘要
// 返回的就是高亮之后的摘要了,没有就是null
String ret = highlighter.getBestFragment(
analyzer, "anyString",document.get("fileContent") );
// String ret = highlighter.getBestFragment(
// analyzer, "anyString",document.get("noThisFiled") );
if (ret != null) {
System.out.println(ret);
}else {
String defaultString = document.get("fileContent");
System.out.println("不高亮:"+defaultString);
}
}
}
查询
查询有两种大类:第一种是使用查询字符串,有查询语法的。就像直接输入sql语句一样。
第二种就是查询对象,即用query类来组合成复杂查询。这个在概述的时候已经讲过了。
对象查询:
常用的有:TermQuery,BooleanQuery,WildcardQuery,PhraseQuery,PrefixQuery,TermRangeQuery等查询。对象查询对应的语法可以直接打印出来system.out.println(query);
TermQuery:
如果你想执行一个这样的查询:“在content域中包含‘lucene’的document”,那么你可以用TermQuery:Term t = new Term("content", " lucene"); Query query = new TermQuery(t);
BooleanQuery
多个query的【与或】关系的查询如果你想这么查询:“在content域中包含java或perl的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
TermQuery termQuery1 = new TermQuery(new Term("content", "java"); TermQuery termQuery 2 = new TermQuery(new Term("content", "perl"); BooleanQuery booleanQuery = new BooleanQuery(); booleanQuery.add(termQuery1, BooleanClause.Occur.SHOULD); booleanQuery.add(termQuery2, BooleanClause.Occur.SHOULD);

反正这个就是lucene的东西,记到就是了
WildcardQuery
通配符的查询如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’use*’,你可能找到’useful’或者’useless’:
Query query = new WildcardQuery(new Term("content", "use*");
PhraseQuery
在指定的文字距离内出现的词的查询你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,你可以:
PhraseQuery query = new PhraseQuery();
query.setSlop(5);
query.add(new Term("content ", “中”));
query.add(new Term(“content”, “日”));
那么它可能搜到“中日合作……”、“中方和日方……”,但是搜不到“中国某高层领导说日本欠扁”。
PrefixQuery
查询词语是以某字符开头的如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
PrefixQuery query = new PrefixQuery(new Term("content ", "中");
FuzzyQuery : 相似的搜索
FuzzyQuery用来搜索相似的term,使用Levenshtein算法。假设你想搜索跟‘wuzza’相似的词语,你可以:
Query query = new FuzzyQuery(new Term("content", "wuzza");
你可能得到‘fuzzy’和‘wuzzy’。
TermRangeQuery
范围查询:范围内搜索你也许想搜索时间域从20060101到20060130之间的document,你可以用TermRangeQuery:
TermRangeQuery query2 = TermRangeQuery.newStringRange("time", "20060101", "20060130", true, true);
最后的true表示用闭合区间。
查询语法
官方的文档里面有: lucene-4.5.0\docs\index.html里面就有如下的链接,可以查看。
我们直接调用query的toString就可以得到他们的查询语法。
查询某field的关键字,对应的对象就是TermQuery,我们大印就知道了,格式是:
[域名字]:[查找的关键字],比如fileContent:absc,就是查找fileContent域的关键字asbsc.
下面是总结:
如果遇到类找不到,那么就多半是jar包有的没有导入,下面的代码就会说明这点
需要使用QueryParser需要的jar等下面都有说明:
lucene-queryparser-4.5.0.jar -à 用于QueryParser
lucene-queries-4.5.0.jar -à 有些查询会用到,比如通配符查询
lucene-memory-4.5.0.jar -à 有些查询会用到,所以都导入就是了
TermQuery可以用“field:key”方式,例如“content:lucene”。
BooleanQuery中‘与’用‘+’,‘或’用‘ ’,例如“content:java contenterl”。
WildcardQuery仍然用‘?’和‘*’,例如“content:use*”。
PhraseQuery用‘~’,例如“content:"中日"~5”。
PrefixQuery用‘*’,例如“中*”。
FuzzyQuery用‘~’,例如“content: wuzza ~”。
RangeQuery用‘[]’或‘{}’,前者表示闭区间,后者表示开区间,例如“time:[20060101 TO 20060130]”,注意TO区分大小写。
你可以任意组合query string,完成复杂操作,例如“标题或正文包括lucene,并且时间在20060101到20060130之间的文章”可以表示为:“+ (title:lucene content:lucene) +time:[20060101 TO 20060130]”。
下面是代码:
1 /**
2
3 * 学习查询语句的例子。
4
5 * 查询分两种:
6
7 * 一个是使用查询字符串。
8
9 * 另一个就是使用对象来查询,这个对象就是{@link Query}对象的子类来查询
10
11 *
12
13 * 对象查询的话有几个几个很重要:
14
15 * @author LiFeng
16
17 *
18
19 */
20
21 public class QueryTest {
22
23 String indexPath = “******Lucene-00010-HelloWorld\\lf_index";
24
25 Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_45);
26
27 /**
28
29 * 用查询字符串查询
30
31 * 如果qString中指定了查询的域"fileContent:abdc",
32
33 * 那么QueryParser构造时的指定的域就被覆盖。
34
35 * 如果qString中没有指定域"abdc",那么就用QueryParser构造时的指定的域。
36
37 * @param qString
38
39 * @throws ParseException
40
41 */
42
43 public void queryData(String qString) throws ParseException
44
45 {
46
47 // 如果qString没有指定域就会用这个域来查询
48
49 QueryParser parser =
50
51 new QueryParser(Version.LUCENE_45, "fileContent", analyzer);
52
53 queryData(parser.parse(qString));
54
55 }
56
57 /**
58
59 * 默认在fileContent域中查找高亮的数据
60
61 * @param query
62
63 */
64
65 public void queryData(Query query)
66
67 {
68
69 System.out.println("Query:"+query);
70
71 String fieldForHighLight = "fileContent";
72
73 // 高亮器的初始化准备
74
75 Highlighter highlighter = null;
76
77 {
78
79 Formatter formatter = new SimpleHTMLFormatter(
80
81 "<font color='red'>", "</font>");
82
83 Scorer fragmentScorer = new QueryScorer(query);
84
85 highlighter = new Highlighter(formatter, fragmentScorer);
86
87 // 摘要只取50个字符
88
89 Fragmenter fragmenter = new SimpleFragmenter(50); highlighter.setTextFragmenter(fragmenter);
90
91 }
92
93 IndexReader indexReader = null;
94
95 try {
96
97 indexReader = DirectoryReader.open(
98
99 FSDirectory.open(new File(indexPath)));
100
101 IndexSearcher searcher = new IndexSearcher(indexReader);
102
103 TopDocs topDocs = searcher.search(query, 1000);
104
105 // 打印结果
106
107 {
108
109 System.out.println("总共有【"+topDocs.totalHits+
110
111 "】条匹配结果");
112
113 // 这是返回的数据
114
115 for (int i = 0; i < topDocs.scoreDocs.length; i++) {
116
117 int docId = topDocs.scoreDocs[i].doc;
118
119 Document hittedDocument = searcher.doc(docId);
120
121 // 用高亮器返回摘要
122
123 // 参数1就是用指定的分词器,
124
125 // 参数2目前不知道咋用
126
127 // 参数3就是我们需要处理哪一段文本的数据,
128
129 // 把这段文件实现高亮并返回摘要
130
131 // 返回的就是高亮之后的摘要了,没有就是null
132
133 String ret = highlighter.getBestFragment(
134
135 analyzer,
136
137 "anyString",
138
139 hittedDocument.get(fieldForHighLight) );
140
141 if (ret != null) {
142
143 System.out.println(ret);
144
145 }else {// 没有找到就输出全文
146
147 String defaultString =
148
149 hittedDocument.get(fieldForHighLight);
150
151 System.out.println("不高亮:"+defaultString);
152
153 }
154
155 }
156
157 }
158
159 indexReader.close();
160
161 indexReader = null;
162
163 } catch (Exception e) {
164
165 e.printStackTrace();
166
167 }finally
168
169 {
170
171 if (indexReader != null) {
172
173 try {
174
175 indexReader.close();
176
177 } catch (IOException e) {
178
179 e.printStackTrace();
180
181 }
182
183 }
184
185 }
186
187 }
188
189 /**
190
191 * 要使用QueryParser,需要导入包:
192
193 * lucene-4.5.0\queryparser\lucene-queryparser-4.5.0.jar
194
195 *
196
197 * 发现于demon的SearchFiles.java,用的是:
198
199 * org.apache.lucene.queryparser.classic.QueryParser
200
201 * @throws ParseException
202
203 */
204
205 @Test
206
207 public void queryByQueryString() throws ParseException
208
209 {
210
211 // 查询字符串,这里关键字大写就可以了,因为经过了分词器
212
213 String qString = "fileContent:Reproduce";// 用指定的域
214
215 String qStringNoField = "Reproduce";// 用Parser默认的域
216
217 queryData(qStringNoField);
218
219 }
220
221 @Test
222
223 public void termQuery()
224
225 {
226
227 // 查询fileContent域的reproduce
228
229 // 注意term里面是没有经过分词器的,因为所有的索引是小写
230
231 // 所以这里需要用小写查询
232
233 Query query = new TermQuery(
234
235 new Term("fileContent", "reproduce"));
236
237 queryData(query);
238
239 }
240
241 /**
242
243 * 短语查询,注意这里有引号
244
245 *
246
247 * fileContent:"advertising features"~5
248
249 * fileContent:"advertising ? ? features"
250
251 */
252
253 @Test
254
255 public void phraseQuery()
256
257 {
258
259 // 比如查询advertising materials mentioning features
260
261 //
262
263 // 再比如想查询lucene *** *** 教程
264
265 // 那么我们可以查询关键词"lucene"和关键词"教程",
266
267 // 然后他们相距5个词之类就行了
268
269 //
270
271 // 查询语句是Query:fileContent:"advertising features"~5
272
273 PhraseQuery query = new PhraseQuery();
274
275 query.setSlop(5);// 最多间隔5个字
276
277 query.add(new Term("fileContent", "advertising"));
278
279 query.add(new Term("fileContent", "features"));
280
281 queryData(query);
282
283 // 也可以固定位置的指定,如下面0号位置就是advertising,
284
285 // 第3号位置是features。注意这个位置是相对起来的。中间隔2个.
286
287 // 我们通过打印出出来的语句就可以看出:
288
289 // fileContent:"advertising ? ? features",也就是指定了只隔2个
290
291 // 改成0,4就不行了。这要的是精确的配置关系
292
293 PhraseQuery query2 = new PhraseQuery();
294
295 query2.add(new Term("fileContent", "advertising"),0);
296
297 query2.add(new Term("fileContent", "features"),3);
298
299 // 就会找到reproduce关键字,也就是相当于把reproduce关键字的找出来
300
301 queryData(query2);
302
303 }
304
305 /**
306
307 * 关键字都是大写,这里的"TO"就是
308
309 * fileSize:[0 TO 3] 两边包含
310
311 * fileSize:{0 TO 3] 不包含左边,包含右边
312
313 */
314
315 @Test
316
317 public void rangeQuery()
318
319 {
320
321 // 我们文件的大小是2845,如果我们搜索0到100000是搜不到的,
322
323 // 因为做的是字符串的比较,也就是
324
325 // "0","100000","2845"比较,明显2845最大,不在这个区间了,
326
327 // 所以我们查不到
328
329 //
330
331 // 如果改成0,3之间就可以查到
332
333 TermRangeQuery query = TermRangeQuery.newStringRange(
334
335 "fileSize", "0", "3", true, true);
336
337 queryData(query);
338
339 TermRangeQuery query2 = TermRangeQuery.newStringRange(
340
341 "fileSize", "0", "3", false, true);
342
343 queryData(query2);
344
345 }
346
347 /**
348
349 * 数字范围的查询,没查到,到时再修改!!!!!!
350
351 *
352
353 * fileSize:[0 TO 30000]
354
355 */
356
357 @Test
358
359 public void rangeQuery2()
360
361 {
362
363 // 因为做的是字符串比较
364
365 // 所以对于数字应该保证字符宽度一样才对,但是数据一变,
366
367 // 我们就又要全体都改,于是有下面的办法,如下分析:
368
369 // 因为java的long就是最长的数据,他的十进制有19位,
370
371 // 所以我们把所有的数字扩展成19为的字符串就可以解决。
372
373 // 当然Lucene已经帮我们提供了。
374
375 //
376
377 // 对于数字的类型,lucene提供了一个工具类帮我们处理:
378
379 // 目前没有找到或者不会用
380
381 // precisionStep是精度,需要 >= 1
382
383 // 但是这个查不到.....????
384
385 Query query2 = NumericRangeQuery.newLongRange(
386
387 "fileSize",0L, 30000L, true, true);
388
389 queryData(query2);
390
391 }
392
393 /**
394
395 * 通配符查询,模糊匹配的一个关键字,
396
397 * 而:PhraseQuery短语查询是多个关键字的间隔。
398
399 *
400
401 * ? : 代表任意一个字符
402
403 * * : 代表0到n个任意字符
404
405 *
406
407 * fileContent:reprod*
408
409 * fileContent:repro??ce
410
411 * fileContent:repro???ce
412
413 * reproduce*:reprod*
414
415 *
416
417 * java.lang.NoClassDefFoundError:
418
419 * org/apache/lucene/queries/CommonTermsQuery
420
421 * 那么需要导入lucene-4.5.0\queries\lucene-queries-4.5.0.jar
422
423 *
424
425 * java.lang.NoClassDefFoundError:
426
427 * org/apache/lucene/index/memory/MemoryIndex
428
429 * 那么需要导入lucene-4.5.0\memory\lucene-memory-4.5.0.jar
430
431 *
432
433 * 所以对于那些NoClassDefFoundError一定是jar没有导全,导入即可解决。
434
435 *
436
437 * 这里就是查询reprod开头的关键字
438
439 */
440
441 @Test
442
443 public void wildcardQuery()
444
445 {
446
447 // 这个跟前缀查询一样..
448
449 WildcardQuery query = new WildcardQuery(
450
451 new Term("fileContent", "reprod*"));
452
453 queryData(query);
454
455 WildcardQuery query2 = new WildcardQuery(
456
457 new Term("fileContent", "repro??ce"));
458
459 queryData(query2);
460
461 // 这个就查不到了
462
463 WildcardQuery query3 = new WildcardQuery(
464
465 new Term("fileContent", "repro???ce"));
466
467 queryData(query3);
468
469 WildcardQuery query4 = new WildcardQuery(
470
471 new Term("reproduce*", "reprod*"));
472
473 queryData(query4);
474
475 }
476
477 /**
478
479 * 多个查询的boolean控制
480
481 * +fileContent:reprod* fileSize:[0 TO 3]
482
483 * -fileContent:"advertising features"~5
484
485 *
486
487 * + : 就是Must 也可以写成AND
488
489 * - : 就是Must_Not 也可以写成NOT
490
491 * 空格 : 就是Should 也可以写成OR
492
493 *
494
495 * MUST : 必须满足条件
496
497 * MUST_NOT : 一定不满足
498
499 * SHOULD : 就是或的意思
500
501 * @throws ParseException
502
503 */
504
505 @Test
506
507 public void booleanQuery() throws ParseException
508
509 {
510
511 BooleanQuery query = new BooleanQuery();
512
513 // 一定有reprod*
514
515 WildcardQuery must = new WildcardQuery(
516
517 new Term("fileContent", "reprod*"));
518
519 // 文件大小一定在0,3的字符串之间
520
521 TermRangeQuery must_size = TermRangeQuery.newStringRange(
522
523 "fileSize", "0", "3", true, true);
524
525 // 有这个条就查不到了嘛
526
527 PhraseQuery not = new PhraseQuery();
528
529 not.setSlop(5);// 最多间隔5个字
530
531 not.add(new Term("fileContent", "advertising"));
532
533 not.add(new Term("fileContent", "features"));
534
535 query.add(new BooleanClause(must, Occur.MUST));
536
537 query.add(new BooleanClause(must_size, Occur.SHOULD));
538
539 query.add(new BooleanClause(not, Occur.MUST_NOT));
540
541 queryData(query);
542
543 System.out.println("下面是使用AND,NOT,OR执行");
544
545 // 两条件相与
546
547 queryData("fileContent:reprod* AND fileSize:[0 TO 3]");
548
549 System.out.println(
550
551 "------------------李锋------分界线-----------");
552
553 // 两条件相或
554
555 queryData("fileContent:reprod* OR fileSize:[0 TO 3]");
556
557 System.out.println(
558
559 "------------------李锋------分界线-----------");
560
561 // A !B
562
563 queryData("fileContent:reprod* NOT fileSize:[0 TO 3]");
564
565 System.out.println(
566
567 "------------------李锋------分界线-----------");
568
569 // !A B
570
571 queryData("NOT fileContent:reprod* AND fileSize:[0 TO 3]");
572
573 // 下面使用括号来用改变优先级
574
575 System.out.println("\n使用括号");
576
577 queryData("fileContent:reprod* AND”+
578
579 ” (fileSize:[0 TO 3] OR fileContent:reprod?)");
580
581 }
582
583 }
584
585
指定排序和相关度权重
排序分两种,一个是修改相关度的权重来影响排序,另一个是使用指定的域来排序。
相关度排序
Lucene 在返回查找结果的时候,会根据相关度进行打分,得分越高的就越在前面,这是默认的处理。相关度的算法很多,比如用n维空间的cos求夹角的方式。相关度又分两种,一种是域的相关度,另一种是doc的相关度。修改相关度的就是boost变量。
1. 域的相关度
a) 在创建查询语句的时候用Map<String, Float> boosts指定
b) 在创建索引的时候指定,这样就固化到了索引文件,需要重建索引才可以修改,或者查询时重新指定也行。((Field)field).setBoost(1.0f);
下面是第一种的代码,第二种的就是((Field)field).setBoost(1.0f);即可。
1 /**
2
3 * 设置域的权重,在查询时指定
4
5 * fileContent:abcdefg.txt filePath:abcdefg.txt^3.0
6
7 * 这就是设置权重的查询语句。
8
9 *
10
11 * 也可以在创建索引时,给field设置权重,那么就固化到索引文件了。
12
13 *
14
15 * @throws InvalidTokenOffsetsException
16
17 * @throws IOException
18
19 * @throws ParseException
20
21 */
22
23 @Test
24
25 public void fieldBoostTest() throws IOException,
26
27 InvalidTokenOffsetsException, ParseException
28
29 {
30
31 String[] fileds = new String[]{"fileContent","filePath"};
32
33 Map<String, Float> boosts = new HashMap<String, Float>();
34
35 // 设置filePath的权重高些,3.0f相当大的影响
36
37 boosts.put("fileContent", 1.0f);
38
39 boosts.put("filePath", 3.0f);
40
41 // 相当于(fileContent:****) (filePath:****)
42
43 // 也就是查询fileContent或者filePath
44
45 MultiFieldQueryParser parser = new MultiFieldQueryParser(
46
47 Version.LUCENE_45, fileds, analyzer,boosts);
48
49 query(parser.parse("abcdefg.txt"));
50
51 // // 上面的相当于下面的
52
53 // {
54
55 // query("fileContent:abcdefg.txt filePath:abcdefg.txt^3.0");
56
57 // query("fileContent:abcdefg.txt OR filePath:abcdefg.txt^3.0");
58
59 // }
60
61 }
62
632. Doc的相关度,我们可以指定某个doc的权重比其他的权重高,这样这篇文字的索引位置就比其他的相对靠前了。
实现方法:目前还没找到。
指定域排序Sort
我们可以指定某个域升降序排列,就像order by一样。1 // 排序
2
3 Sort sort = new Sort();
4
5 // 就是大小升序
6
7 //sort.setSort(new SortField("fileSize", Type.LONG,false));
8
9 // 就是大小降序
10
11 sort.setSort(new SortField("fileSize", Type.LONG,true));
12
13 TopDocs topDocs = searcher.search(query, 1000,sort);
14
15 //这个简单,直接指定传给IndexSeacher即可
16
17 //有时你想要一个排好序的结果集,就像SQL语句的“order by”,lucene能做到:通过Sort。
18
19 Sort sort = new Sort(“time”); //相当于SQL的“order by time”
20
21 Sort sort = new Sort(“time”, true); // 相当于SQL的“order by time desc”
22
23 //下面是一个完整的例子:
24
25 Directory dir = FSDirectory.getDirectory(PATH, false);
26
27 IndexSearcher is = new IndexSearcher(dir);
28
29 QueryParser parser = new QueryParser("content", new StandardAnalyzer());
30
31 Query query = parser.parse("title:lucene content:lucene");
32
33 RangeFilter filter = new RangeFilter("time", "20060101", "20060230", true, true);
34
35 Sort sort = new Sort(“time”);
36
37 Hits hits = is.search(query, filter, sort);
38
39 for (int i = 0; i < hits.length(); i++)
40
41 {
42
43 Document doc = hits.doc(i);
44
45 System.out.println(doc.get("title");
46
47 }
48
49 is.close();
50
51
过滤器Filter
就是过滤一些东西,我们在查询的时候可以指定:// 使用过滤器
Filter filter = NumericRangeFilter.newLongRange(
"fileSize", 111L, 800L, true, true);
TopDocs topDocs = searcher.search(query, filter,1000);
这个就过滤文件大小,但是测试结果是查不到,需要再想一下。
filter 的作用就是限制只查询索引的某个子集,它的作用有点像SQL语句里的where,但又有区别,它不是正规查询的一部分,只是对数据源进行预处理,然后交给查询语句。注意它执行的是预处理,而不是对查询结果进行过滤,所以使用filter的代价是很大的,它可能会使一次查询耗时提高一百倍。
最常用的filter是RangeFilter和QueryFilter。RangeFilter是设定只搜索指定范围内的索引;QueryFilter是在上次查询的结果中搜索。
Filter的使用非常简单,你只需创建一个filter实例,然后把它传给searcher。继续上面的例子,查询“时间在20060101到20060130之间的文章”除了将限制写在query string中,你还可以写在RangeFilter中:
Directory dir = FSDirectory.getDirectory(PATH, false);
IndexSearcher is = new IndexSearcher(dir);
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("title:lucene content:lucene";
RangeFilter filter = new RangeFilter("time", "20060101", "20060230", true, true);
Hits hits = is.search(query, filter);
for (int i = 0; i < hits.length(); i++)
{
Document doc = hits.doc(i);
System.out.println(doc.get("title");
}
is.close();
学习途径:
1. 看官方的例子程序,里面有生成索引,查询的方法,还有高级知识!里面讲了生成doc时不同的域可以用不用的子类域来封装,比如文StringField,LongField,TextField,等等很好!
2. 官方文档,里面查询API,当前链接了源码之后这个文档就没多大意义了
3. 看官方文档指定的wiki:
http://wiki.apache.org/lucene-java/FrontPage?action=show&redirect=FrontPageEN
4. 看Lucene 原理与代码分析完整版.pdf
性能优化
一直到这里,我们还是在讨论怎么样使lucene跑起来,完成指定任务。利用前面说的也确实能完成大部分功能。但是测试表明lucene的性能并不是很好,在大数据量大并发的条件下甚至会有半分钟返回的情况。另外大数据量的数据初始化建立索引也是一个十分耗时的过程。那么如何提高lucene的性能呢?下面从优化创建索引性能和优化搜索性能两方面介绍。
优化创建索引性能
这方面的优化途径比较有限,IndexWriter提供了一些接口可以控制建立索引的操作,另外我们可以先将索引写入RAMDirectory,再批量写入FSDirectory,不管怎样,目的都是尽量少的文件IO,因为创建索引的最大瓶颈在于磁盘IO。另外选择一个较好的分析器也能提高一些性能。
通过设置IndexWriter的参数优化索引建立
setMaxBufferedDocs(int maxBufferedDocs)控制写入一个新的segment前内存中保存的document的数目,设置较大的数目可以加快建索引速度,默认为10。
setMaxMergeDocs(int maxMergeDocs)
控制一个segment中可以保存的最大document数目,值较小有利于追加索引的速度,默认Integer.MAX_VALUE,无需修改。
setMergeFactor(int mergeFactor)
控制多个segment合并的频率,值较大时建立索引速度较快,默认是10,可以在建立索引时设置为100。
通过RAMDirectory缓写提高性能
我们可以先把索引写入RAMDirectory,达到一定数量时再批量写进FSDirectory,减少磁盘IO次数。FSDirectory fsDir = FSDirectory.getDirectory("/data/index", true);
RAMDirectory ramDir = new RAMDirectory();
IndexWriter fsWriter = new IndexWriter(fsDir, new StandardAnalyzer(), true);
IndexWriter ramWriter = new IndexWriter(ramDir, new StandardAnalyzer(), true);
while (there are documents to index)
{
... create Document ...
ramWriter.addDocument(doc);
if (condition for flushing memory to disk has been met)
{
fsWriter.addIndexes(new Directory[] { ramDir });
ramWriter.close();
ramWriter = new IndexWriter(ramDir, new StandardAnalyzer(), true);
}
}
选择较好的分析器
这个优化主要是对磁盘空间的优化,可以将索引文件减小将近一半,相同测试数据下由600M减少到380M。但是对时间并没有什么帮助,甚至会需要更长时间,因为较好的分析器需要匹配词库,会消耗更多cpu,测试数据用StandardAnalyzer耗时133分钟;用MMAnalyzer耗时150分钟。
优化搜索性能
虽然建立索引的操作非常耗时,但是那毕竟只在最初创建时才需要,平时只是少量的维护操作,更何况这些可以放到一个后台进程处理,并不影响用户搜索。我们创建索引的目的就是给用户搜索,所以搜索的性能才是我们最关心的。下面就来探讨一下如何提高搜索性能。
将索引放入内存
这是一个最直观的想法,因为内存比磁盘快很多。Lucene提供了RAMDirectory可以在内存中容纳索引:Directory fsDir = FSDirectory.getDirectory(“/data/index/”, false);
Directory ramDir = new RAMDirectory(fsDir);
Searcher searcher = new IndexSearcher(ramDir);
但是实践证明RAMDirectory和FSDirectory速度差不多,当数据量很小时两者都非常快,当数据量较大时(索引文件400M)RAMDirectory甚至比FSDirectory还要慢一点,这确实让人出乎意料。
而且lucene的搜索非常耗内存,即使将400M的索引文件载入内存,在运行一段时间后都会out of memory,所以个人认为载入内存的作用并不大。
优化时间范围限制
既然载入内存并不能提高效率,一定有其它瓶颈,经过测试发现最大的瓶颈居然是时间范围限制,那么我们可以怎样使时间范围限制的代价最小呢?当需要搜索指定时间范围内的结果时,可以:
1、用RangeQuery,设置范围,但是RangeQuery的实现实际上是将时间范围内的时间点展开,组成一个个BooleanClause加入到 BooleanQuery中查询,因此时间范围不可能设置太大,经测试,范围超过一个月就会抛 BooleanQuery.TooManyClauses,可以通过设置 BooleanQuery.setMaxClauseCount (int maxClauseCount)扩大,但是扩大也是有限的,并且随着maxClauseCount扩大,占用内存也扩大
2、用 RangeFilter代替RangeQuery,经测试速度不会比RangeQuery慢,但是仍然有性能瓶颈,查询的90%以上时间耗费在 RangeFilter,研究其源码发现RangeFilter实际上是首先遍历所有索引,生成一个BitSet,标记每个document,在时间范围内的标记为true,不在的标记为false,然后将结果传递给Searcher查找,这是十分耗时的。
3、进一步提高性能,这个又有两个思路:
a、缓存Filter结果。既然RangeFilter的执行是在搜索之前,那么它的输入都是一定的,就是IndexReader,而 IndexReader是由Directory决定的,所以可以认为RangeFilter的结果是由范围的上下限决定的,也就是由具体的 RangeFilter对象决定,所以我们只要以RangeFilter对象为键,将filter结果BitSet缓存起来即可。lucene API 已经提供了一个CachingWrapperFilter类封装了Filter及其结果,所以具体实施起来我们可以
cache CachingWrapperFilter对象,需要注意的是,不要被CachingWrapperFilter的名字及其说明误导, CachingWrapperFilter看起来是有缓存功能,但的缓存是针对同一个filter的,也就是在你用同一个filter过滤不同 IndexReader时,它可以帮你缓存不同IndexReader的结果,而我们的需求恰恰相反,我们是用不同filter过滤同一个 IndexReader,所以只能把它作为一个封装类。
b、降低时间精度。研究Filter的工作原理可以看出,它每次工作都是遍历整个索引的,所以时间粒度越大,对比越快,搜索时间越短,在不影响功能的情况下,时间精度越低越好,有时甚至牺牲一点精度也值得,当然最好的情况是根本不作时间限制。
下面针对上面的两个思路演示一下优化结果(都采用800线程随机关键词随即时间范围):
第一组,时间精度为秒:
方式 直接用RangeFilter 使用cache 不用filter
平均每个线程耗时 10s 1s 300ms
第二组,时间精度为天
方式 直接用RangeFilter 使用cache 不用filter
平均每个线程耗时 900ms 360ms 300ms
由以上数据可以得出结论:
1、 尽量降低时间精度,将精度由秒换成天带来的性能提高甚至比使用cache还好,最好不使用filter。
2、 在不能降低时间精度的情况下,使用cache能带了10倍左右的性能提高。
使用更好的分析器
这个跟创建索引优化道理差不多,索引文件小了搜索自然会加快。当然这个提高也是有限的。较好的分析器相对于最差的分析器对性能的提升在20%以下。
一些经验
关键词区分大小写
OR AND TO等关键词是区分大小写的,lucene只认大写的,小写的当做普通单词。
读写互斥性
同一时刻只能有一个对索引的写操作,在写的同时可以进行搜索
文件锁
在写索引的过程中强行退出将在tmp目录留下一个lock文件,使以后的写操作无法进行,可以将其手工删除
时间格式
lucene只支持一种时间格式yyMMddHHmmss,所以你传一个yy-MM-dd HH:mm:ss的时间给lucene它是不会当作时间来处理的
设置boost
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章(没有使用排序的前题下)。使用方法:Field. setBoost(float boost);默认值是1.0,也就是说要增加权重的需要设置得比1大。
Compass框架
还没学

相关文章推荐
- 学习笔记14 Lucene.NET中Field.Index 和 Field.Store的几种属性的用法
- Lucene学习笔记(1)-索引创建和简单的查询
- 搜索-Lucene学习笔记
- lucene学习笔记
- Lucene学习笔记
- lucene.Net--学习笔记(3)---C#'网络爬虫' 源码详解
- Lucene学习笔记(3)(竹笋炒肉)
- Lucene学习笔记一
- Lucene学习笔记:一,全文检索的基本原理
- Lucene 学习笔记(3) :Hello Lucene(Lucene Index的创建和查找)
- Lucene 3.5.0学习笔记
- 学习Lucene笔记一:创建索引
- 学习Lucene笔记二:搜索初步
- lucene学习笔记2-查询索引
- lucene 学习笔记之飞龙在天
- Lucene 学习笔记
- Lucene学习笔记
- Lucene学习笔记:全文检索的基本原理
- Lucene学习笔记【2013-04-12更新】
- lucene学习笔记 1