[ASP.NET]强大的网页处理类NSoup
2014-04-04 14:40
316 查看
我们如果在项目中碰到要处理HTML,如果是.NET程序员的话,强烈推荐使用NSoup,不然的话截取字符串是在是太痛苦了。NSoup是一个开源框架,是JSoup的.NET移植版本,使用方法基本一致!NSoup点击下载


<span style="font-family: Arial, Helvetica, sans-serif;">NSoup.Nodes.Document doc = NSoup.NSoupClient.Connect("http://blog.csdn.net/dingxiaowie2013").Get();</span>
或者是自定义html,生成html页面[csharp]view plaincopyprint?
NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(HtmlString);
但是很遗憾NSoup默认的是UTF-8,处理中文会有乱码(对于编码是UTF-8自然会正常,但是有些是GB2312的就可能有乱码)
[csharp]view plaincopyprint?
//下载网页源代码
WebClient webClient = new WebClient();
string htmlString = Encoding.GetEncoding("utf-8").GetString(webClient.DownloadData("http://www.baidu.com"));
NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(htmlString);
2.获得网页的流
[csharp]view plaincopyprint?
//获得网页流
WebRequest webRequest = WebRequest.Create("http://blog.csdn.net/dingxiaowei2013");
NSoup.Nodes.Document doc1 = NSoup.NSoupClient.Parse(webRequest.GetResponse().GetResponseStream(), "utf-8");
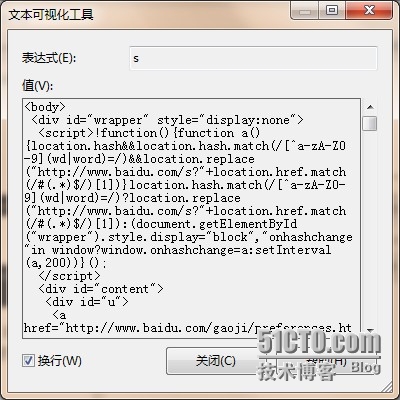
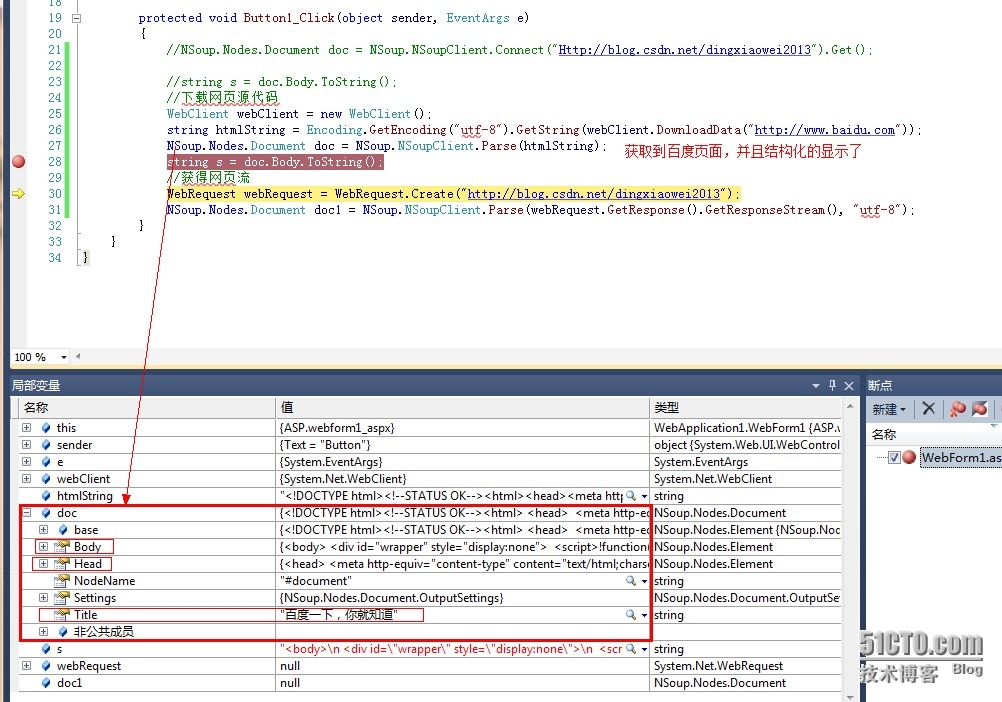
会发现跟百度的源码是一样的
获取网页的html代码
处理网页html[csharp]view plaincopyprint?<span style="font-family: Arial, Helvetica, sans-serif;">NSoup.Nodes.Document doc = NSoup.NSoupClient.Connect("http://blog.csdn.net/dingxiaowie2013").Get();</span>
或者是自定义html,生成html页面[csharp]view plaincopyprint?
NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(HtmlString);
但是很遗憾NSoup默认的是UTF-8,处理中文会有乱码(对于编码是UTF-8自然会正常,但是有些是GB2312的就可能有乱码)
解决NSoup解析HTML乱码的办法
1.下载网页源代码再处理[csharp]view plaincopyprint?
//下载网页源代码
WebClient webClient = new WebClient();
string htmlString = Encoding.GetEncoding("utf-8").GetString(webClient.DownloadData("http://www.baidu.com"));
NSoup.Nodes.Document doc = NSoup.NSoupClient.Parse(htmlString);
2.获得网页的流
[csharp]view plaincopyprint?
//获得网页流
WebRequest webRequest = WebRequest.Create("http://blog.csdn.net/dingxiaowei2013");
NSoup.Nodes.Document doc1 = NSoup.NSoupClient.Parse(webRequest.GetResponse().GetResponseStream(), "utf-8");
效果图
会发现跟百度的源码是一样的

相关文章推荐
- [ASP.NET]强大的网页处理类NSoup
- (摘录)26个ASP.NET常用性能优化方法
- (摘录)ASP.NET提供文件下载函数(支持大文件、续传、速度限制、资源占用小)
- Asp.net EasyUI中的combogrid实现分页功能
- asp.net mvc 应用程序错误“/”
- asp.net mvc 503 错误
- asp.net 使用js分页,异步加载数据
- Asp.net页面生存周期【转】
- ASP.NET MVC加载用户控件后并获取其内控件值或赋值
- Asp.net的IP地址屏蔽功能设计
- asp.net下载文件
- ubuntu下使用VNC连接树莓派raspberry
- asp.net 使用js分页实现异步加载数据
- CKEditor和CKFinder在ASP.NET项目中安装,配置和使用详解
- ASP.NET MVC显示WebForm网页或UserControl控件
- ASP.NET Identity登录原理 - Claims-based认证和OWIN
- asp.net中打印指定控件内容
- 使用Spring中的aspect或advisor实现方法拦截,模拟缓存实现
- HTML控件ID和NAME属性的区别,以及如何在asp.net页面的.CS文件中获得.ASPX页面中HTML控件的值
- HTML控件ID和NAME属性的区别,以及如何在asp.net页面的.CS文件中获得.ASPX页面中HTML控件的值