Pooling
2014-04-03 21:13
671 查看
Pooling
Pooling: Overview
After obtaining features using convolution, we would next like to use them for classification. In theory, one could use all the extracted features with a classifier such as a softmax classifier, but this can be computationally challenging. Consider for instanceimages of size 96x96 pixels, and suppose we have learned 400 features over 8x8 inputs. Each convolution results in an output of size
(96 − 8 + 1) * (96 − 8 + 1) = 7921, and since we have 400 features, this results in a vector of
892 * 400 = 3,168,400 features per example. Learning a classifier with inputs having 3+ million features can be unwieldy, and can also be prone to over-fitting.
To address this, first recall that we decided to obtain convolved features because images have the "stationarity" property, which implies that features that are useful in one region are also likely to be useful for other regions. Thus, to describe a large
image, one natural approach is to aggregate statistics of these features at various locations. For example, one could compute the mean (or max) value of a particular feature over a region of the image. These summary statistics are much lower in dimension (compared
to using all of the extracted features) and can also improve results (less over-fitting). We aggregation operation is called this operation
pooling, or sometimes mean pooling or max pooling (depending on the pooling operation applied).
The following image shows how pooling is done over 4 non-overlapping regions of the image.

Pooling for Invariance
If one chooses the pooling regions to be contiguous areas in the image and only pools features generated from the same (replicated) hidden units. Then, these pooling units will then betranslation invariant. This means that the same (pooled) feature will be active even when the image undergoes (small) translations. Translation-invariant features are often desirable; in many tasks (e.g., object detection, audio recognition),
the label of the example (image) is the same even when the image is translated. For example, if you were to take an MNIST digit and translate it left or right, you would want your classifier to still accurately classify it as the same digit regardless of its
final position.
Formal description
Formally, after obtaining our convolved features as described earlier, we decide the size of the region, say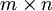
to pool our convolved features over. Then, we divide our convolved features into disjoint
regions, and take the mean (or maximum) feature activation over these regions to obtain the pooled convolved features. These pooled
features can then be used for classification.
from: http://ufldl.stanford.edu/wiki/index.php?title=Pooling&action=edit

相关文章推荐
- XML相关技术资料
- XML简易教程之三
- 基于XML的桌面应用
- XML指南――XML 语法
- XML指南——XML编码
- XHTML标准的版本
- XML指南――XML 属性
- XML指南――XML 确认
- XML简易教程之二
- AIX服务级别---你所需要了解的基本资料
- Machine Learning Foundation Lecture 02 Learning to Answer YesNo 学习笔记
- 从K-means到Sparse Coding
- Cost Function Intuition
- mathine learning,开始kaggle
- 跟着做openRISC1200和minSoC---从2013.11.12
- 机器学习之开源库大总结
- 机器学习中的数学(5)-强大的矩阵奇异值分解(SVD)及其应用
- 谱聚类(spectral clustering)
- 在Web服务器上禁止Socket Pooling
- MIMO系统ML检测(最大似然检测)