推荐系统方法之协同过滤
2014-04-03 20:17
169 查看
现如今,推荐系统的应用无处不在,亚马逊、当当、淘宝....都使用了推荐系统。
推荐系统算法主要有以下三种:
1.基于人口统计学的推荐
2.基于内容的推荐
3.协同过滤
在现今的推荐技术和算法中,最被大家广泛认可和采用的就是基于协同过滤的推荐方法。
什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
换句话说,就是借鉴和你相关人群的观点来进行推荐,很好理解。
协同过滤的实现
在协同过滤中,有两种主流方法:基于用户的协同过滤、基于物品的协同过滤
基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合;
(2)找到这个集合中的用户喜欢,且目标用户没有听说过的物品,并将此物品推荐该目标用户。
对于步骤(1),计算两个用户之间兴趣的相似度,给定用户A和用户B,他们的相似度可通过余弦相似度来计算:
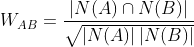
其中: N(A)为用户A喜欢的物品的集合,N(B)为用户B喜欢的物品的集合。
该公式分子的含义为:用户A和用户B共同喜欢的物品的个数
该公式分母的含义为:用户A喜欢的物品的个数乘以用户B喜欢的物品的个数,再开根号
比如,A喜欢{a,b,d},B喜欢{a,c},那么用户A和用户B的相似度为:

下图给出了一个例子,对于用户 A,根据用户的历史偏好,找到和用户A兴趣相似的用户-用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。

基于物品的协同过滤算法主要包括两个步骤:
(1)计算物品之间的相似度;
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
对于步骤(1),计算两个物品之间的相似度,给定物品i和物品j,它们的相似度可通过余弦相似度来计算:

其中: N(i)为喜欢物品i的用户的集合,N(j)为喜欢物品j的用户的集合;
该公式分子的含义为:既喜欢物品i又喜欢物品j的用户的个数;
该公式分母的含义为:喜欢物品i的用户的个数乘以喜欢物品j的用户的个数,再开根号。
下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户
C 可能也喜欢物品 C。
注意:两个物品产生相似度是因为它们共同被很多用户喜欢。

详细请参考:https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/
推荐系统算法主要有以下三种:
1.基于人口统计学的推荐
2.基于内容的推荐
3.协同过滤
在现今的推荐技术和算法中,最被大家广泛认可和采用的就是基于协同过滤的推荐方法。
什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
换句话说,就是借鉴和你相关人群的观点来进行推荐,很好理解。
协同过滤的实现
在协同过滤中,有两种主流方法:基于用户的协同过滤、基于物品的协同过滤
基于用户的协同过滤算法主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合;
(2)找到这个集合中的用户喜欢,且目标用户没有听说过的物品,并将此物品推荐该目标用户。
对于步骤(1),计算两个用户之间兴趣的相似度,给定用户A和用户B,他们的相似度可通过余弦相似度来计算:
其中: N(A)为用户A喜欢的物品的集合,N(B)为用户B喜欢的物品的集合。
该公式分子的含义为:用户A和用户B共同喜欢的物品的个数
该公式分母的含义为:用户A喜欢的物品的个数乘以用户B喜欢的物品的个数,再开根号
比如,A喜欢{a,b,d},B喜欢{a,c},那么用户A和用户B的相似度为:
下图给出了一个例子,对于用户 A,根据用户的历史偏好,找到和用户A兴趣相似的用户-用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
基于物品的协同过滤算法主要包括两个步骤:
(1)计算物品之间的相似度;
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
对于步骤(1),计算两个物品之间的相似度,给定物品i和物品j,它们的相似度可通过余弦相似度来计算:
其中: N(i)为喜欢物品i的用户的集合,N(j)为喜欢物品j的用户的集合;
该公式分子的含义为:既喜欢物品i又喜欢物品j的用户的个数;
该公式分母的含义为:喜欢物品i的用户的个数乘以喜欢物品j的用户的个数,再开根号。
下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户
C 可能也喜欢物品 C。
注意:两个物品产生相似度是因为它们共同被很多用户喜欢。
详细请参考:https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/

相关文章推荐
- 数据推荐系统系列 8种方法之一 User-CF 方式
- 推荐系统(recommender systems):预测电影评分--构造推荐系统的一种方法:基于内容的推荐
- 【转】 矩阵分解方法及 在推荐系统中的应用
- “基于机器学习算法的推荐系统” 在软件静态分析领域的应用方法
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 【推荐系统】协同过滤(CF)算法详解,item-base,user-based,SVD,SVD++
- 浅谈物理学方法在推荐系统中应用价值和意义
- 推荐系统中的相似度计算方法总结
- 推荐系统实验方法
- 基于模糊聚类和协同过滤的混合推荐系统
- 基于协同过滤的推荐系统
- 推荐系统: 相关推荐方法对比
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
- 基于用户的协同过滤(user-based CF)推荐系统【1】
- 推荐系统方法(利用用户行为数据)
- Spark MLlib系列(二):基于协同过滤的电影推荐系统
- 推荐系统入门:作为Rank系统的推荐系统(协同过滤)
- 推荐系统(recommender systems):预测电影评分--构造推荐系统的一种方法:协同过滤(collaborative filtering )
- 推荐系统评价:NDCG方法概述
- 第1章:阿里云机器学习实践之路 / 第3节:推荐系统--基于协同过滤的商品推荐