jieba分词之——1、initialize & load_userdictr
2014-04-03 14:10
239 查看
"结巴"中文分词是Python中文分词组件,作者从三个方面描述jieba中文分词的算法
1. 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
2. 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
3. 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
我从源代码的角度分为三部分对jieba中文分词进行分析,
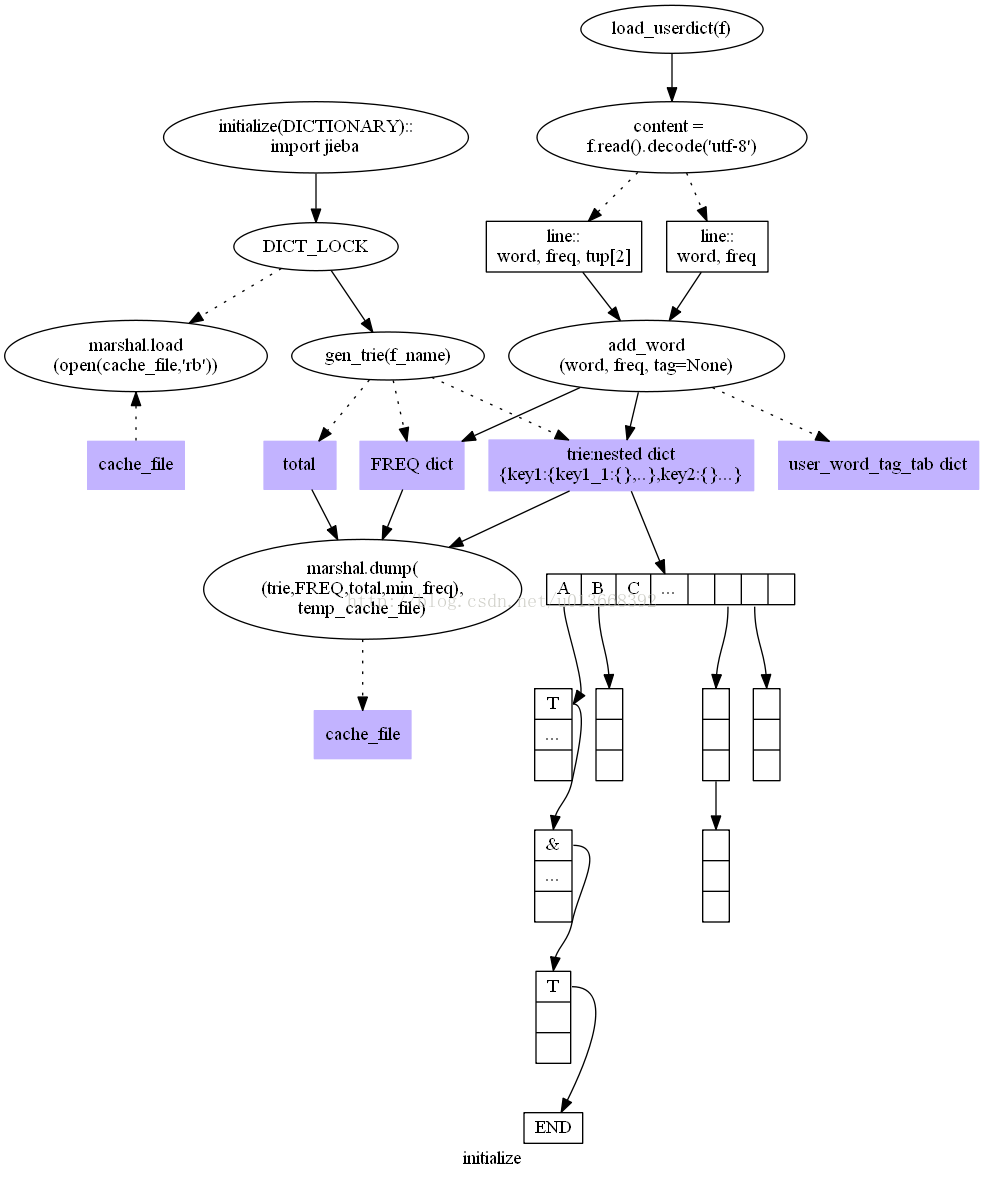
第一部分Jieba分词的初始化,包括核心词典和用户词典的加载,这一部分涉及最基础的数据结构,有:
trie又称前缀树或字典树,jieba中的具体实现是一个嵌套的dict,它用于存储词典;
l FREQ在jieba中的具体实现是一个dict,它存储词和词频的对应关系;
l min_freq存储最小的词频;
l total存储所有词的词频的总和。
第二部分作者描述中第1、2部分DAG和动态规划算法
第三部分介绍jieba中文分词组件中的HMM模型和Viterbi算法应用
1. 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
2. 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
3. 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
我从源代码的角度分为三部分对jieba中文分词进行分析,
第一部分Jieba分词的初始化,包括核心词典和用户词典的加载,这一部分涉及最基础的数据结构,有:
trie又称前缀树或字典树,jieba中的具体实现是一个嵌套的dict,它用于存储词典;
l FREQ在jieba中的具体实现是一个dict,它存储词和词频的对应关系;
l min_freq存储最小的词频;
l total存储所有词的词频的总和。
第二部分作者描述中第1、2部分DAG和动态规划算法
第三部分介绍jieba中文分词组件中的HMM模型和Viterbi算法应用

相关文章推荐
- OC中initialize&& load && init方法
- load&initialize&单例模式
- [RuntimeInitializeOnLoadMethod] 非场景非脚本初始化脚本(转自雨松mo'mo)
- 编译SDL( solution:SDL_image.h:undefined reference to `IMG_Load' )
- 关于反射Assembly.Load("程序集").CreateInstance("命名空间.类")
- R语言文本挖掘之jieba分词与wordcloud展现
- "Could not find or load main class" in Hadoop or Java using Maven
- Objective C类方法load和initialize的区别
- Objective-C 中 +load 与 +initialize
- 86,类的启动过程——load,initialize
- Python中文分词--jieba的基本使用
- 关于QT5 Failed to find or load platform plugin "windows" 问题
- Error occurred: install_driver(mysql) failed: Can't load '/usr/lib/perl5/site_perl/5.8.8/i386-linux-
- python 结巴分词(jieba)学习
- Qt程序部署时遇到的坑:could not find or load the Qt platform plugin "windows"
- python 结巴分词(jieba)学习
- NSObject的load和initialize方法
- Cannot load supported formats: Cannot run program "svn": CreateProcess error=2
- NsObject的load和initialize方法
- 黑马day18 jquery高级特性&Ajax的load方法