使用堆外内存
2014-04-02 18:29
225 查看
使用堆外内存
有时候对内存进行大对象的读写,会引起JVM长时间的停顿,有时候则是希望最大程度地提高JVM的效率,我们需要自己来管理内存(看起来很像是Java像C++祖宗的妥协吧)。据我所知,很多缓存框架都会使用它,比如我以前使用过的EhCache(给它包装了个酷一点的名字,叫BigMemory),以及现在项目中的Memcached。在nio以前,是没有光明正大的做法的,有一个work around的办法是直接访问Unsafe类。如果你使用Eclipse,默认是不允许访问sun.misc下面的类的,你需要稍微修改一下,给TypeAccess Rules里面添加一条所有类都可以访问的规则:
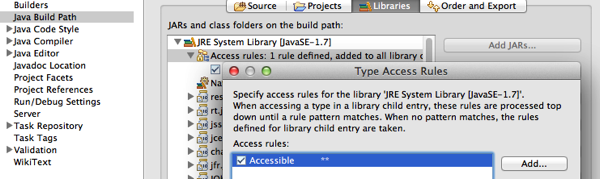
在使用Unsafe类的时候:
Although the class and all methods are public, use of this class is limited because only trusted code can obtain instances of it.
于是,只能无耻地使用反射来做这件事;
从nio时代开始,可以使用ByteBuffer等类来操纵堆外内存了:
对于heap的OOM我们可以通过执行jmap -heap来获取堆内内存情况,例如以下输出取自我上周定位的一个问题:
对于堆外内存的使用率,可以使用rednaxelafx做的一个工具来查看:链接。
BTW,如果在执行jmap命令时遇到:
Agent)的工具,比如jinfo/jstack/jmap都会存在这个问题,但是Oracle说了“won’t fix”……
Ubuntu 10.10 and newer has a new default security policy that affects Serviceability commands. This policy prevents a process from attaching to another process owned by the same UID if the target process is not a descendant of the attaching process.
不过它也是给了解决方案的,需要修改/etc/sysctl.d/10-ptrace.conf:
堆外内存泄露的问题定位通常比较麻烦,可以借助google-perftools这个工具,它可以输出不同方法申请堆外内存的数量。当然,如果你是64位系统,你需要先安装libunwind库。
最后,JDK存在一些direct buffer的bug(比如这个和这个),可能引发OOM,所以也不妨升级JDK的版本看能否解决问题。
转自:http://www.raychase.net/1526

相关文章推荐
- Python 点滴
- HMBASE的REGION分配
- SQL SERVER 2014 内存优化表迁移
- java中HashMap详解
- JasperReport报表设计总结(一)(已完毕)
- BZOJ 斜率优化dp 1010: [HNOI2008]玩具装箱toy
- 策略模式
- postgresql修改账户postgres密码
- POJ 1088 滑雪
- 很好的瀑布流效果,简单易用
- eclipse快捷键
- 教务管理系统,项目介绍
- 我們的時光
- c++ 详解链接过程
- Uva 673 Parentheses Balance
- 日立通过收购扩张其北美Dynamics CRM业务
- 使用ireport创建报表模板时,向subdataset中传参
- scut1040
- scut1107
- scut1024