Lucene 源代码剖析-2 Lucene是什么
2014-04-01 22:58
447 查看
转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
1 Lucene是什么
Apache Lucene是一个高性能(high-performance)的全能的全文检索(full-featured
text search engine)的搜索引擎框架库,完全(entirely)使用Java开发。它是一种技术(technology),适合于(suitable
for)几乎(nearly)任何一种需要全文检索(full-text search)的应用,特别是跨平台(cross-platform)的应用。
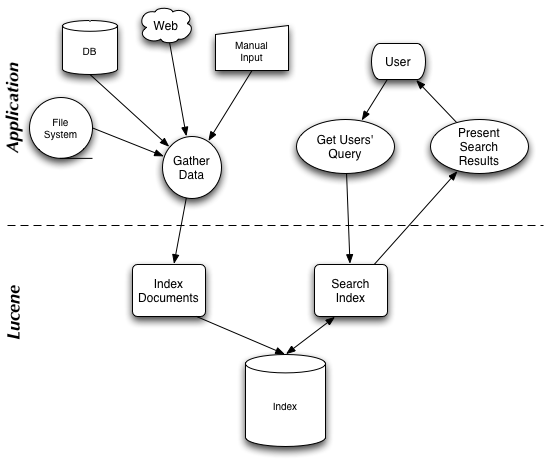
Lucene 通过一些简单的接口(simple
API)提供了强大的特征(powerful features):
可扩展的高性能的索引能力(Scalable, High-Performance Indexing)
超过20M/分钟的处理能力(Pentium
M 1.5GHz)
很少的RAM内存需求,只需要1MB
heap
增量索引(incremental indexing)的速度与批量索引(batch
indexing)的速度一样快
索引的大小粗略(roughly)为被索引的文本大小的20-30%
强大的精确的高效率的检索算法(< /strong>[b]Powerful, Accurate and Efficient Search Algorithms)[/b]
分级检索(ranked searching)能力,最好的结果优先推出在前面
很多强大的query种类:phrase
queries, wildcard queries, proximity queries, range queries等
支持域检索(fielded searching),如标题、作者、正文等
支持日期范围检索(date-range searching)
可以按任意域排序(sorting by any field)
支持多个索引的检索(multiple-index searching)并合并结果集(merged
results)
允许更新和检索(update and searching)并发进行(simultaneous)
[b]跨平台解决方案(Cross-Platform Solution)[/b]
以Open Source方式提供并遵循Apache
License,允许你可以在即包括商业应用也包括Open Source程序中使用Lucene
100%-pure Java(纯Java实现)
提供其他开发语言的实现版本并且它们的索引文件是兼容的
Lucene API被分成(divide
into)如下几种包(package)
[b]org.apache.lucene.analysis [/b]
定义了一个抽象的Analyser API,用于将text文本从一个java.io.Reader转换成一个TokenStream,即包括一些Tokens的枚举容器(enumeration)。一个TokenStream的组成(compose)是通过在一个Tokenizer的输出的结果上再应用TokenFilters生成的。一些少量的Analysers实现已经提供,包括StopAnalyzer和基于语法(gramar-based)分析的StandardAnalyzer。
[b]org.apache.lucene.document [/b]
提供一个简单的Document类,一个document只不过包括一系列的命名了(named)的Fields(域),它们的内容可以是文本(strings)也可以是一个java.io.Reader的实例。
[b]org.apache.lucene.index [/b]
提供两个主要类,一个是IndexWriter用于创建索引并添加文档(document),另一个是IndexReader用于访问索引中的数据。
[b]org.apache.lucene.search [/b]
提供数据结构(data structures)来呈现(represent)查询(queries):TermQuery用于单个的词(individual
words),PhraseQuery用于短语,BooleanQuery用于通过boolean关系组合(combinations)在一起的queries。而抽象的Searcher用于转变queries为命中的结果(hits)。IndexSearcher实现了在一个单独(single)的IndexReader上检索。
[b]org.apache.lucene.queryParser [/b]
使用JavaCC实现一个QueryParser。
[b]org.apache.lucene.store
[/b]
定义了一个抽象的类用于存储呈现的数据(storing persistent data),即Directory(目录),一个收集器(collection)包含了一些命名了的文件(named
files),它们通过一个IndexOutput来写入,以及一个IndexInput来读取。提供了两个实现,FSDirectory使用一个文件系统目录来存储文件,而另一个RAMDirectory则实现了将文件当作驻留内存的数据结构(memory-resident
data structures)。
[b]org.apache.lucene.util [/b]
包含了一小部分有用(handy)的数据结构,如BitVector和PriorityQueue等。
[b]2 Hello
World![/b]
下面是一段简单的代码展示如何使用Lucene来进行索引和检索(使用JUnit来检查结果是否是我们预期的):

// Store the index in memory:
Directory directory = new RAMDirectory();
// To store an index on disk, use this instead:
//Directory directory = FSDirectory.getDirectory(”/tmp/testindex”);
IndexWriter iwriter = new IndexWriter(directory, analyzer, true);
iwriter.setMaxFieldLength(25000);
Document doc = new Document();
String text = “This is the text to be indexed.“;
doc.add(new Field(“fieldname“, text, Field.Store.YES,
Field.Index.TOKENIZED));
iwriter.addDocument(doc);
iwriter.optimize();
iwriter.close();
// Now search the index:
IndexSearcher isearcher = new IndexSearcher(directory);
// Parse a simple query that searches for ”text”:
QueryParser parser = new QueryParser(“fieldname“, analyzer);
Query query = parser.parse(“text“);
Hits hits = isearcher.search(query);
assertEquals(1, hits.length());
// Iterate through the results:

for (int i = 0; i < hits.length(); i++) {

Document hitDoc = hits.doc(i);
assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“));

}
isearcher.close();
directory.close();
为了使用Lucene,一个应用程序需要做如下几件事:
1.通过添加一系列Fields来创建一批Documents对象。
2.创建一个IndexWriter对象,并且调用它的AddDocument()方法来添加进Documents。
3.调用QueryParser.parse()处理一段文本(string)来建造一个查询(query)对象。
4.创建一个IndexReader对象并将查询对象传入到它的search()方法中。
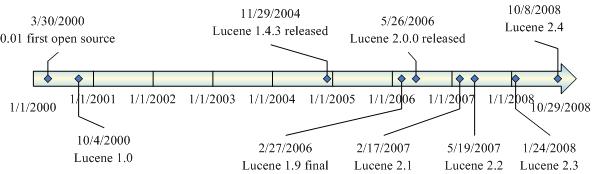
[b]3 Lucene Roadmap[/b]
[b]

[/b]
源地址下是 Word 文档,这里转换成HTML 格式
1 Lucene是什么
Apache Lucene是一个高性能(high-performance)的全能的全文检索(full-featured
text search engine)的搜索引擎框架库,完全(entirely)使用Java开发。它是一种技术(technology),适合于(suitable
for)几乎(nearly)任何一种需要全文检索(full-text search)的应用,特别是跨平台(cross-platform)的应用。
Lucene 通过一些简单的接口(simple
API)提供了强大的特征(powerful features):
可扩展的高性能的索引能力(Scalable, High-Performance Indexing)
超过20M/分钟的处理能力(Pentium
M 1.5GHz)
很少的RAM内存需求,只需要1MB
heap
增量索引(incremental indexing)的速度与批量索引(batch
indexing)的速度一样快
索引的大小粗略(roughly)为被索引的文本大小的20-30%
强大的精确的高效率的检索算法(< /strong>[b]Powerful, Accurate and Efficient Search Algorithms)[/b]
分级检索(ranked searching)能力,最好的结果优先推出在前面
很多强大的query种类:phrase
queries, wildcard queries, proximity queries, range queries等
支持域检索(fielded searching),如标题、作者、正文等
支持日期范围检索(date-range searching)
可以按任意域排序(sorting by any field)
支持多个索引的检索(multiple-index searching)并合并结果集(merged
results)
允许更新和检索(update and searching)并发进行(simultaneous)
[b]跨平台解决方案(Cross-Platform Solution)[/b]
以Open Source方式提供并遵循Apache
License,允许你可以在即包括商业应用也包括Open Source程序中使用Lucene
100%-pure Java(纯Java实现)
提供其他开发语言的实现版本并且它们的索引文件是兼容的
Lucene API被分成(divide
into)如下几种包(package)
[b]org.apache.lucene.analysis [/b]
定义了一个抽象的Analyser API,用于将text文本从一个java.io.Reader转换成一个TokenStream,即包括一些Tokens的枚举容器(enumeration)。一个TokenStream的组成(compose)是通过在一个Tokenizer的输出的结果上再应用TokenFilters生成的。一些少量的Analysers实现已经提供,包括StopAnalyzer和基于语法(gramar-based)分析的StandardAnalyzer。
[b]org.apache.lucene.document [/b]
提供一个简单的Document类,一个document只不过包括一系列的命名了(named)的Fields(域),它们的内容可以是文本(strings)也可以是一个java.io.Reader的实例。
[b]org.apache.lucene.index [/b]
提供两个主要类,一个是IndexWriter用于创建索引并添加文档(document),另一个是IndexReader用于访问索引中的数据。
[b]org.apache.lucene.search [/b]
提供数据结构(data structures)来呈现(represent)查询(queries):TermQuery用于单个的词(individual
words),PhraseQuery用于短语,BooleanQuery用于通过boolean关系组合(combinations)在一起的queries。而抽象的Searcher用于转变queries为命中的结果(hits)。IndexSearcher实现了在一个单独(single)的IndexReader上检索。
[b]org.apache.lucene.queryParser [/b]
使用JavaCC实现一个QueryParser。
[b]org.apache.lucene.store
[/b]
定义了一个抽象的类用于存储呈现的数据(storing persistent data),即Directory(目录),一个收集器(collection)包含了一些命名了的文件(named
files),它们通过一个IndexOutput来写入,以及一个IndexInput来读取。提供了两个实现,FSDirectory使用一个文件系统目录来存储文件,而另一个RAMDirectory则实现了将文件当作驻留内存的数据结构(memory-resident
data structures)。
[b]org.apache.lucene.util [/b]
包含了一小部分有用(handy)的数据结构,如BitVector和PriorityQueue等。
[b]2 Hello
World![/b]
下面是一段简单的代码展示如何使用Lucene来进行索引和检索(使用JUnit来检查结果是否是我们预期的):
// Store the index in memory:
Directory directory = new RAMDirectory();
// To store an index on disk, use this instead:
//Directory directory = FSDirectory.getDirectory(”/tmp/testindex”);
IndexWriter iwriter = new IndexWriter(directory, analyzer, true);
iwriter.setMaxFieldLength(25000);
Document doc = new Document();
String text = “This is the text to be indexed.“;
doc.add(new Field(“fieldname“, text, Field.Store.YES,
Field.Index.TOKENIZED));
iwriter.addDocument(doc);
iwriter.optimize();
iwriter.close();
// Now search the index:
IndexSearcher isearcher = new IndexSearcher(directory);
// Parse a simple query that searches for ”text”:
QueryParser parser = new QueryParser(“fieldname“, analyzer);
Query query = parser.parse(“text“);
Hits hits = isearcher.search(query);
assertEquals(1, hits.length());
// Iterate through the results:
for (int i = 0; i < hits.length(); i++) {
Document hitDoc = hits.doc(i);
assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“));
}
isearcher.close();
directory.close();
为了使用Lucene,一个应用程序需要做如下几件事:
1.通过添加一系列Fields来创建一批Documents对象。
2.创建一个IndexWriter对象,并且调用它的AddDocument()方法来添加进Documents。
3.调用QueryParser.parse()处理一段文本(string)来建造一个查询(query)对象。
4.创建一个IndexReader对象并将查询对象传入到它的search()方法中。
[b]3 Lucene Roadmap[/b]
[b]
[/b]

相关文章推荐
- Lucene 源代码剖析-2 Lucene是什么
- Lucene 源代码剖析-6 索引文件结构(3)
- Lucene 源代码剖析-11 文档内容是如何分析的
- Lucene 源代码剖析-12 如何给文档评分
- Lucene 源代码剖析-7 索引文件结构(4)
- Lucene 源代码剖析-8 索引是如何创建的
- Lucene 源代码剖析-3 索引文件概述
- Lucene 源代码剖析-9 索引创建过程
- Lucene 源代码剖析-4 索引文件结构(1)
- Lucene 源代码剖析-10 索引是如何存储的
- Lucene 源代码剖析-5 索引文件结构(2)
- 从源代码剖析Mahout推荐引擎
- 加多芬科技深度剖析--“什么是移动支付服务商“
- STL 之 queue、priority_queue 源代码剖析
- Joomla源代码解析(十七) JModel是什么
- STL 源代码剖析 算法 stl_algo.h -- partial_sort / partial_sort_copy
- redis系统命令源代码剖析笔记(3)
- Lucene4源代码分析之一:源代码导入Eclipse
- 从源代码剖析Mahout推荐引擎
- lucene源代码分析(index部分)