MapReduce作业运行流程
2014-03-30 18:18
399 查看
一.MapReduce作业运行流程
根据源码分析作业的提交流程时序图如下
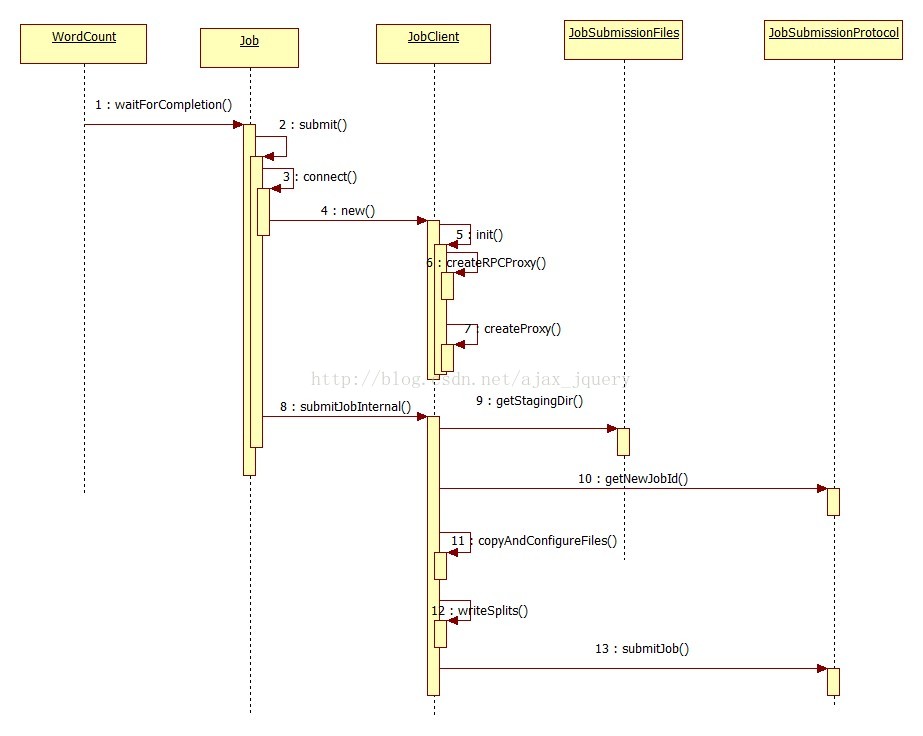
MR的作业流程图:
1.在客户端启动一个作业。
2.通过JobClient向JobTracker请求一个Job ID和资源文件存放路径。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息(通过阅读源码获得分片的计算公式为:splitSize = max(minsize,min(maxsize,blockSize)),minsize默认值是1L,maxsize默认值是2的63次方减1)。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job
ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制)。
4.开始提交任务(任务的描述信息,不是jar)。
5.JobTracker进程初始化任务,JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度。
6.读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask。
7.TaskTracker通过心跳机制向JobTracker汇报当前运行情况和资源使用情况,JobTracker根据TaskTracker的汇报情况分配不同的执行任务。
8.TaskTracker根据分配到的任务下载所需的jar,配置文件等。
9.TaskTracker启动一个java child进程,用来执行具体的任务(MapperTask或ReducerTask)。
10.将结果写入到HDFS当中
到此MR的作业运行流程介绍完毕。
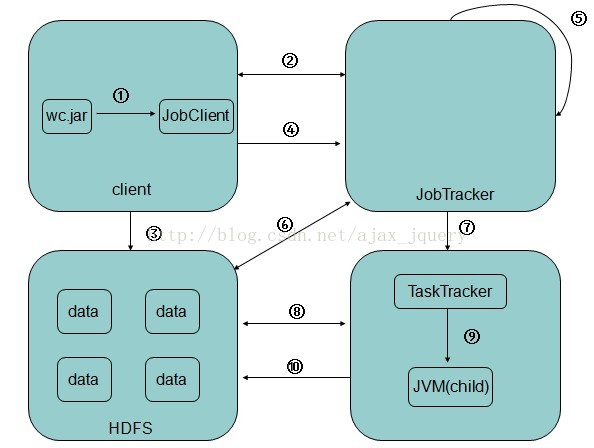
根据源码分析作业的提交流程时序图如下
MR的作业流程图:
1.在客户端启动一个作业。
2.通过JobClient向JobTracker请求一个Job ID和资源文件存放路径。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息(通过阅读源码获得分片的计算公式为:splitSize = max(minsize,min(maxsize,blockSize)),minsize默认值是1L,maxsize默认值是2的63次方减1)。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job
ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制)。
4.开始提交任务(任务的描述信息,不是jar)。
5.JobTracker进程初始化任务,JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度。
6.读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask。
7.TaskTracker通过心跳机制向JobTracker汇报当前运行情况和资源使用情况,JobTracker根据TaskTracker的汇报情况分配不同的执行任务。
8.TaskTracker根据分配到的任务下载所需的jar,配置文件等。
9.TaskTracker启动一个java child进程,用来执行具体的任务(MapperTask或ReducerTask)。
10.将结果写入到HDFS当中
到此MR的作业运行流程介绍完毕。

相关文章推荐
- 004_012 Python 将列表中的元素交替的作为键和值来创建字典
- 监理进度控制2
- 在web.xml中classpath和classpath*的区别
- 怎样制作页面标签
- 张孝祥读写锁(学习笔记)
- Codeforces Round #239 (Div. 1)(A,B)
- Ubuntu13.04设置静态ip(无论笔记本、台式、虚拟机)
- InitCommonControlsEx Function|MFC通用控件初始化
- 浙大PAT 5-05. QQ帐户的申请与登陆 (解题思路)
- oracle的索引使用
- 异常exception与error-code
- 2014 MVP Open Day 见闻(下)
- 程序员:提高编程效率的技巧
- iOS 播放音频的几种方法
- 黑马程序员_java关于子类的继承
- Spring声明式事务配置管理方法
- oracle用户权限传递
- 最接近点对
- 一场相遇 一种相惜一分心疼一段心灵之约
- Firebug 调试 JS入门--如何调试JS