关于Oracle10.2.0.5+linux5+raid5 IO问题分析
2014-03-28 18:42
441 查看
系统环境:CentOS release 5.10
应用环境:Oracle 10.2.0.5 + php5.2.17
硬 件 :DELL R720,1T*3 7200r,raid5
业务环境:每5分钟sqlload入库5分钟内有效数据,数据大小30M左右
问题原由:
最近做了一次数据迁移,硬件由之前的300G*3 7200r变为1T*3 7200r并硬件raid5,其他环境对等迁移,但是迁移过后,感觉io写的效率极低,开始分析io是否存在瓶颈。
分析过程:
刚发现io写效率低是在业务写的同时手工进行一个大文件的io写,业务写被完全阻塞,同时服务器负载曾一度高至50左右(负载最高时cpu wait 45%左右,iowait 35%左右),看到这个负载,立马在oracle里面跑了一下相关sql【select * from v$locked_objects;select * from v$lock where request <> 0
or block <> 0;】,没有产生锁阻塞,还是觉得跑下awr,对比一下迁移之前和迁移之后做个对比吧,结果跑完之后,挺让人惊讶的(结果有一部分原因也算有点情理之中)
awr信息:2:00-3:00,纯业务,无其他操作,业务操作量相同,oracle配置完全相同(除redolog路径):
179数据库(迁移前):
Top 5 Timed Events
51数据库(迁移后):【由于仅有的3块硬盘被做成了raid5,所以redolog只能被放在raid5阵列上】:
Top 5 Timed Events
wait time一部分原因是redo同datafile一起被放到了raid5上,io争用导致的,但也可以看出这个io整体的效率,还是要比之前差很多
所以针对io,做了一系列的测试,包括os上的dd测试(dd if=/dev/zero of=/Data/apps/oracle/product/10.2.0/oradata/detail/detail//1Gb.file bs=1024 count=1000000),往两个服务器上分别dd一个临时文件,然后用iostat观察io情况,结果如下:
179服务器(迁移前):
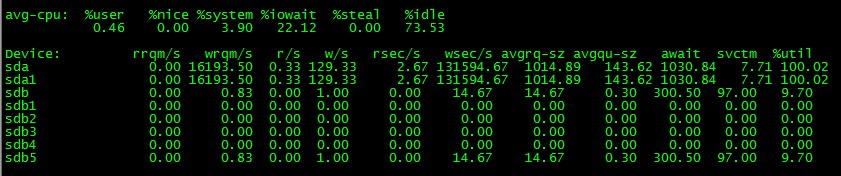
51服务器(迁移后):

看到这两个IO对比,发现51服务器的dm-0各项数值很高,远大于数据盘sda2和sda的io数值,先来研究一下dm-0的各项数据 。
首先w/s显示,写请求次数对比数据盘的sda和sda2来说,写请求2242.33太高,而相对应的avgrq-sz可以看到,每次平均写才8,基本都是小文件,但请求很频繁,%iowait 24.81%,再结合avgqu-sz、svctm和%util来看,导致io队列太长,io负载已经很高,确定存在瓶颈。
同时对比sda,sda2数据盘的io数据,差异比较大的首先就是wsec/s(每秒写扇区数),迁移前后,wsec/s差了8.9倍,在同样业务,同样数据量的情况下,差这么多,完全不正常,个人觉得,估计就是迁移后,频繁的小io写请求,加之硬盘转速不够,导致io瓶颈被放大。而在同样数据量、业务逻辑的两个io环境,迁移后io为何出现如此频繁的小io写请求,猜测应该和raid5数据交叉校验有关。RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上,每次写数据都会用其他盘区的校验数据去校验正在
io的数据是否有效和一致,应该就是造成频繁小IO写的原因之一。
以上只是个人的一个认识和理解,由于刚刚恶补IO这块的知识,所以错误在所难免,欢迎纠错!
相关介绍:
=====================================================
=====================iostat详解========================
=====================================================
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
rsec/s: 每秒读扇区数.即 delta(rsect)/s
wsec/s: 每秒写扇区数.即 delta(wsect)/s
rkB/s: 每秒读K字节数.是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)
wkB/s: 每秒写K字节数.是 wsect/s 的一半.(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度.即 delta(aveq)/s/1000 (因为aveq的单位为毫秒).
await: 平均每次设备I/O操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的.即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈.
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外 await 的参数也要多和 svctm 来参考.差的过高就一定有 IO 的问题.
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小.如果数据拿的大,才IO 的数据会高.也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s.也就是讲,读定速度是这个来决定的.
另外还可以参考
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加.await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式.如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核
elevator 算法,优化应用,或者升级 CPU.
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水.
=====================================================
========================raid
5========================
=====================================================
RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。
RAID 5可以理解为是RAID 0和RAID 1的折中方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID
5的磁盘空间利用率要比RAID 1高,存储成本相对较低。
运作
以四个硬盘组成的RAID 5为例,其数据存储方式如概述中的图片所示:图中,P0为D0、D1和D2的奇偶校验信息,其它以此类推。由图中可以看出,RAID
5不对存储的数据进行备份,而是把数据和与其相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
校验
RAID5校验位算法原理
P=D1 xor D2 xor D3 … xor Dn (D1,D2,D3 … Dn为数据块,P为校验,xor为异或运算)
XOR(Exclusive OR)的校验原理如下表:
这里的A与B值就代表了两个位,从中可以发现,A与B一样时,XOR结果为0,A与B不一样时,XOR结果就是1,而且知道XOR结果和A与B中的任何一个数值,就可以反推出另一个数值。比如A为1,XOR结果为1,那么B肯定为0,如果XOR结果为0,那么B肯定为1。这就是XOR编码与校验的基本原理。
读写
用简单的语言来表示,至少使用3块硬盘(也可以更多)组建RAID5磁盘阵列,当有数据写入硬盘的时候,按照1块硬盘的方式就是直接写入这块硬盘的磁道,如果是RAID5的话这次数据写入会根据算法分成3部分,然后写入这3块硬盘,写入的同时还会在这3块硬盘上写入校验信息,当读取写入的数据的时候会分别从3块硬盘上读取数据内容,再通过检验信息进行校验。当其中有1块硬盘出现损坏的时候,就从另外2块硬盘上存储的数据可以计算出第3块硬盘的数据内容。也就是说raid5这种存储方式只允许有一块硬盘出现故障,出现故障时需要尽快更换。当更换故障硬盘后,在故障期间写入的数据会进行重新校验。
如果在未解决故障又坏1块,那就是灾难性的了。
存储
RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
应用环境:Oracle 10.2.0.5 + php5.2.17
硬 件 :DELL R720,1T*3 7200r,raid5
业务环境:每5分钟sqlload入库5分钟内有效数据,数据大小30M左右
问题原由:
最近做了一次数据迁移,硬件由之前的300G*3 7200r变为1T*3 7200r并硬件raid5,其他环境对等迁移,但是迁移过后,感觉io写的效率极低,开始分析io是否存在瓶颈。
分析过程:
刚发现io写效率低是在业务写的同时手工进行一个大文件的io写,业务写被完全阻塞,同时服务器负载曾一度高至50左右(负载最高时cpu wait 45%左右,iowait 35%左右),看到这个负载,立马在oracle里面跑了一下相关sql【select * from v$locked_objects;select * from v$lock where request <> 0
or block <> 0;】,没有产生锁阻塞,还是觉得跑下awr,对比一下迁移之前和迁移之后做个对比吧,结果跑完之后,挺让人惊讶的(结果有一部分原因也算有点情理之中)
awr信息:2:00-3:00,纯业务,无其他操作,业务操作量相同,oracle配置完全相同(除redolog路径):
179数据库(迁移前):
Top 5 Timed Events
| Event | Waits | Time(s) | Avg Wait(ms) | % Total Call Time | Wait Class |
|---|---|---|---|---|---|
| CPU time | 348 | 95.6 | |||
| log file sync | 12,706 | 12 | 1 | 3.3 | Commit |
| log file parallel write | 13,531 | 12 | 1 | 3.2 | System I/O |
| enq: TM - contention | 4 | 9 | 2,362 | 2.6 | Application |
| control file parallel write | 2,102 | 6 | 3 | 1.7 | System I/O |
Top 5 Timed Events
| Event | Waits | Time(s) | Avg Wait(ms) | % Total Call Time | Wait Class |
|---|---|---|---|---|---|
| log file parallel write | 12,626 | 220 | 17 | 87.2 | System I/O |
| log file sync | 12,940 | 217 | 17 | 86.2 | Commit |
| control file parallel write | 1,734 | 85 | 49 | 33.7 | System I/O |
| CPU time | 37 | 14.8 | |||
| log file switch completion | 16 | 3 | 172 | 1.1 | Configuration |
所以针对io,做了一系列的测试,包括os上的dd测试(dd if=/dev/zero of=/Data/apps/oracle/product/10.2.0/oradata/detail/detail//1Gb.file bs=1024 count=1000000),往两个服务器上分别dd一个临时文件,然后用iostat观察io情况,结果如下:
179服务器(迁移前):
51服务器(迁移后):
看到这两个IO对比,发现51服务器的dm-0各项数值很高,远大于数据盘sda2和sda的io数值,先来研究一下dm-0的各项数据 。
首先w/s显示,写请求次数对比数据盘的sda和sda2来说,写请求2242.33太高,而相对应的avgrq-sz可以看到,每次平均写才8,基本都是小文件,但请求很频繁,%iowait 24.81%,再结合avgqu-sz、svctm和%util来看,导致io队列太长,io负载已经很高,确定存在瓶颈。
同时对比sda,sda2数据盘的io数据,差异比较大的首先就是wsec/s(每秒写扇区数),迁移前后,wsec/s差了8.9倍,在同样业务,同样数据量的情况下,差这么多,完全不正常,个人觉得,估计就是迁移后,频繁的小io写请求,加之硬盘转速不够,导致io瓶颈被放大。而在同样数据量、业务逻辑的两个io环境,迁移后io为何出现如此频繁的小io写请求,猜测应该和raid5数据交叉校验有关。RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上,每次写数据都会用其他盘区的校验数据去校验正在
io的数据是否有效和一致,应该就是造成频繁小IO写的原因之一。
以上只是个人的一个认识和理解,由于刚刚恶补IO这块的知识,所以错误在所难免,欢迎纠错!
相关介绍:
=====================================================
=====================iostat详解========================
=====================================================
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
rsec/s: 每秒读扇区数.即 delta(rsect)/s
wsec/s: 每秒写扇区数.即 delta(wsect)/s
rkB/s: 每秒读K字节数.是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)
wkB/s: 每秒写K字节数.是 wsect/s 的一半.(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度.即 delta(aveq)/s/1000 (因为aveq的单位为毫秒).
await: 平均每次设备I/O操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的.即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈.
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外 await 的参数也要多和 svctm 来参考.差的过高就一定有 IO 的问题.
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小.如果数据拿的大,才IO 的数据会高.也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s.也就是讲,读定速度是这个来决定的.
另外还可以参考
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加.await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式.如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核
elevator 算法,优化应用,或者升级 CPU.
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水.
=====================================================
========================raid
5========================
=====================================================
RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。
RAID 5可以理解为是RAID 0和RAID 1的折中方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID
5的磁盘空间利用率要比RAID 1高,存储成本相对较低。
运作
以四个硬盘组成的RAID 5为例,其数据存储方式如概述中的图片所示:图中,P0为D0、D1和D2的奇偶校验信息,其它以此类推。由图中可以看出,RAID
5不对存储的数据进行备份,而是把数据和与其相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
校验
RAID5校验位算法原理
P=D1 xor D2 xor D3 … xor Dn (D1,D2,D3 … Dn为数据块,P为校验,xor为异或运算)
XOR(Exclusive OR)的校验原理如下表:
| A值 | B值 | Xor结果 |
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
读写
用简单的语言来表示,至少使用3块硬盘(也可以更多)组建RAID5磁盘阵列,当有数据写入硬盘的时候,按照1块硬盘的方式就是直接写入这块硬盘的磁道,如果是RAID5的话这次数据写入会根据算法分成3部分,然后写入这3块硬盘,写入的同时还会在这3块硬盘上写入校验信息,当读取写入的数据的时候会分别从3块硬盘上读取数据内容,再通过检验信息进行校验。当其中有1块硬盘出现损坏的时候,就从另外2块硬盘上存储的数据可以计算出第3块硬盘的数据内容。也就是说raid5这种存储方式只允许有一块硬盘出现故障,出现故障时需要尽快更换。当更换故障硬盘后,在故障期间写入的数据会进行重新校验。
如果在未解决故障又坏1块,那就是灾难性的了。
存储
RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。

相关文章推荐
- 关于Oracle full outer join 的bug问题分析及处理
- 关于oracle 锁机制锁问题的详细分析(处理锁定)以及死锁的解决方案
- 关于oracle安装讲解和问题分析
- 关于Mysql数据库longblob格式数据的插入com.mysql.jdbc.PreparedStatement.setBinaryStream(ILjava/io/InputStream;J)V问题分析
- 关于Linux下安装Oracle时报错:out of memory的问题分析说明
- 关于Oracle在where子句中引用列别名问题的分析
- 2019年6月关于Oracle DB_link和SCN补丁问题分析, 想说爱你不容易
- 关于Linux下安装Oracle时报错:out of memory的问题分析说明
- [转自Oracle官方中文博客]关于sys CPU usage 100%问题的分析
- 关于Oracle中varchar2和dbms_output.put_line的长度限制问题小结
- Oracle Sql Loader 的使用关于Windows 上回车换行符的问题 最后一个字段使用 terminated by '\r'
- 关于enq: TX - allocate ITL entry的问题分析
- 关于oracle锁表以及解锁问题
- 关于asp调用oracle存储过程的问题
- Oracle IO问题解析
- oracle中关于varchar2的最大长度问题
- 关于数值分析和LCP问题的一些开源项目
- 关于硬链接与软连接占用磁盘空间问题的分析研究
- 关于形如--error LNK2005: xxx 已经在 msvcrtd.lib ( MSVCR90D.dll ) 中定义--的问题分析解决