VC 编译器将除法优化为乘法的策略
2014-03-26 11:40
337 查看
这是我今天破解一个crackme看到的
XOR EAX,ESI
ADD ESP,8
MOV ECX,EAX
MOV EAX,55555556
IMUL ECX
MOV EAX,EDX
POP ESI
SHR EAX,1F
ADD EDX,EAX
由于技术欠缺,对汇编不熟悉,转换成如下表达式,发现不会算,遂google之15890084????????h=(x shr 1f +x)=55555556h*(注册码h xor 55564949h)
发现原来是VC 编译器将除法优化为乘法的结果,好不容易搞明白,贴出两个对我帮助很大的帖子http://bbs.pediy.com/archive/index.php?t-68849.html
http://www.cppblog.com/huyutian/articles/124742.html
并作备份如下:
今天调试一个程序时遇到了一段奇怪的汇编代码
mov eax, 68DB8BADh
push edi
movsx ecx, word ptr [esi+0Eh]
imul ecx
sar edx, 0Ch
mov eax, edx
shr eax, 1Fh
add edx, eax
看了半天也没看明白,主要是这个68DB8BADh出现的很突兀,与前后代码在逻辑上都不相关联。到网上搜了下,还居然找到了答案。原来这是一段编译器将除法优化为乘法运算的典型代码。众所周知,除法是最耗CPU的,能够转化为等效的乘法就要快得多了。但不是每次除法都能这么优化的。对于一些特定数作为被除数时,这种优化还是很有效的。
http://www.thesolver.it/Manuali/Factotum/source/076.htm这里列出了一些典型数的除法转换表。
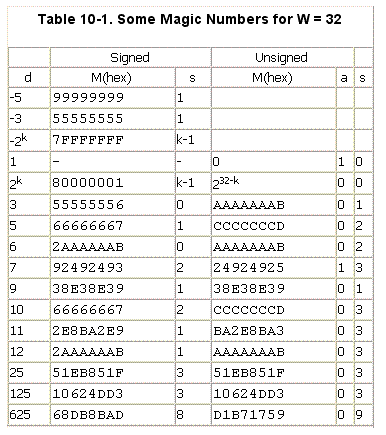
这个表是32位运算下除法转换为乘法的一些案例。比如68DB8BADh这个魔术数就是用来转换除以625的。要计算x/625 = (x * 68DB8BADh) >>8.所以上面的代码其实就是计算[esi +0Eh] / 10000.
下面这个表是64位运算时除法转换为乘法的一些魔术数,摘录在此,以防备忘

如果想搞清楚相关的运算原理可以看该网站的Chapter 10. Integer Division by Constants ,网址是http://www.thesolver.it/Manuali/Factotum/source/062.htm
大家也可以自己编一段小程序验证一下。
1 #include <stdio.h>
2
3 int main(int argc, char* argv[])
4 {
5 int a = getchar();
6 int b = a / 10000;
7 printf("a=%d\nb=a/10000=%d\n", a, b);
8 return 0;
9 }
10
在VC2008下设置项目编译属性Assembler Output,选择输出汇编代码,看看编译出来的代码与上面的完全一致。
———————————————————————————————————————————
#include <stdio.h>
int main()
{
int a;
int b;
b = rand();
a = b/9;
printf("b = %d, a= %d", b , a);
getchar();
}
.text:00401000 ; int __cdecl main(int argc, const char **argv, const char *envp)
.text:00401000 _main proc near ; CODE XREF: start+AFp
.text:00401000 E8 0E 02 00 00 call _rand
.text:00401005 8B C8 mov ecx, eax
.text:00401007 B8 39 8E E3 38 mov eax, 38E38E39h
.text:0040100C F7 E9 imul ecx
.text:0040100E D1 FA sar edx, 1
.text:00401010 8B C2 mov eax, edx
.text:00401012 C1 E8 1F shr eax, 1Fh
.text:00401015 03 D0 add edx, eax
.text:00401017 52 push edx
.text:00401018 51
XOR EAX,ESI
ADD ESP,8
MOV ECX,EAX
MOV EAX,55555556
IMUL ECX
MOV EAX,EDX
POP ESI
SHR EAX,1F
ADD EDX,EAX
由于技术欠缺,对汇编不熟悉,转换成如下表达式,发现不会算,遂google之15890084????????h=(x shr 1f +x)=55555556h*(注册码h xor 55564949h)
发现原来是VC 编译器将除法优化为乘法的结果,好不容易搞明白,贴出两个对我帮助很大的帖子http://bbs.pediy.com/archive/index.php?t-68849.html
http://www.cppblog.com/huyutian/articles/124742.html
并作备份如下:
今天调试一个程序时遇到了一段奇怪的汇编代码
mov eax, 68DB8BADh
push edi
movsx ecx, word ptr [esi+0Eh]
imul ecx
sar edx, 0Ch
mov eax, edx
shr eax, 1Fh
add edx, eax
看了半天也没看明白,主要是这个68DB8BADh出现的很突兀,与前后代码在逻辑上都不相关联。到网上搜了下,还居然找到了答案。原来这是一段编译器将除法优化为乘法运算的典型代码。众所周知,除法是最耗CPU的,能够转化为等效的乘法就要快得多了。但不是每次除法都能这么优化的。对于一些特定数作为被除数时,这种优化还是很有效的。
http://www.thesolver.it/Manuali/Factotum/source/076.htm这里列出了一些典型数的除法转换表。
这个表是32位运算下除法转换为乘法的一些案例。比如68DB8BADh这个魔术数就是用来转换除以625的。要计算x/625 = (x * 68DB8BADh) >>8.所以上面的代码其实就是计算[esi +0Eh] / 10000.
下面这个表是64位运算时除法转换为乘法的一些魔术数,摘录在此,以防备忘
如果想搞清楚相关的运算原理可以看该网站的Chapter 10. Integer Division by Constants ,网址是http://www.thesolver.it/Manuali/Factotum/source/062.htm
大家也可以自己编一段小程序验证一下。
1 #include <stdio.h>
2
3 int main(int argc, char* argv[])
4 {
5 int a = getchar();
6 int b = a / 10000;
7 printf("a=%d\nb=a/10000=%d\n", a, b);
8 return 0;
9 }
10
在VC2008下设置项目编译属性Assembler Output,选择输出汇编代码,看看编译出来的代码与上面的完全一致。
———————————————————————————————————————————
#include <stdio.h>
int main()
{
int a;
int b;
b = rand();
a = b/9;
printf("b = %d, a= %d", b , a);
getchar();
}
.text:00401000 ; int __cdecl main(int argc, const char **argv, const char *envp)
.text:00401000 _main proc near ; CODE XREF: start+AFp
.text:00401000 E8 0E 02 00 00 call _rand
.text:00401005 8B C8 mov ecx, eax
.text:00401007 B8 39 8E E3 38 mov eax, 38E38E39h
.text:0040100C F7 E9 imul ecx
.text:0040100E D1 FA sar edx, 1
.text:00401010 8B C2 mov eax, edx
.text:00401012 C1 E8 1F shr eax, 1Fh
.text:00401015 03 D0 add edx, eax
.text:00401017 52 push edx
.text:00401018 51

相关文章推荐
- VC++编译器对整数除法的优化
- VC6/VS2003编译器优化造成的bug
- JAVA对于乘法除法和模运算的优化,是否需要转换成位运算
- VC编译器“与或非”优化技巧
- VC编译器优化设置
- 【黑客免杀攻防】读书笔记11 - 加法与减法、乘法与除法优化原理
- 《黑客免杀攻防》读书笔记-软件逆向工程(8)乘法与除法的识别与优化原理
- VC6/VS2003编译器优化造成的bug
- 看看编译器是怎样用乘法代替除法的
- 编译器是如何实现32位整型的常量整数除法优化的?[C/C++]
- 基于ARM的除法运算优化策略
- vc编译exe的体积最小优化(附编译器参数)
- ARM的除法运算优化策略
- 编译器也会出错--由VC优化引起的BUG
- 逆向VC对乘法的优化
- 【矩阵乘法优化DP】Codeforces 717D Dexterina’s Lab
- 高性能Linux服务器优化策略一:优化配置
- (转)gcc编译与vc编译器区别
- VC编译器设置
- Android性能优化之线程池策略和对线程池的了解