MySQL 5.5 分区性能测试之索引使用情况
2014-03-11 11:04
866 查看
[align=center]MySQL 5.5 分区性能测试之索引使用情况[/align]
1.创建一个测试表
[sql]
view plaincopy
CREATE TABLE test (
id VARCHAR(20) NOT NULL,
name VARCHAR(20) NOT NULL,
submit_time DATETIME NOT NULL,
index time_index (submit_time),
index id_index (id)
)ENGINE=MyISAM
PARTITION BY RANGE COLUMNS(submit_time)
(
PARTITION p1 VALUES LESS THAN ('2010-02-01'),
PARTITION p2 VALUES LESS THAN ('2010-03-01'),
PARTITION p3 VALUES LESS THAN ('2010-04-01'),
PARTITION p4 VALUES LESS THAN ('2010-05-01'),
PARTITION p5 VALUES LESS THAN ('2010-06-01'),
PARTITION p6 VALUES LESS THAN ('2010-07-01'),
PARTITION p7 VALUES LESS THAN ('2010-08-01'),
PARTITION p8 VALUES LESS THAN ('2010-09-01'),
PARTITION p9 VALUES LESS THAN ('2010-10-01'),
PARTITION p10 VALUES LESS THAN ('2010-11-01'),
PARTITION p11 VALUES LESS THAN ('2010-12-01')
);
2.写一个存储过程,插入数据
[sql]
view plaincopy
delimiter //
CREATE PROCEDURE mark_test()
begin
declare v int default 0;
while v < 8000
do
insert into test values (v,'testing partitions',adddate('2010-01-01', INTERVAL v hour));
set v = v + 1;
end while;
end //
delimiter ;
3.实验开始

上面可以看到,这个是查某一个分区里面的某一些内容,所以完全可以用到index.效果很好..

上面可以看到,跨分区查询,效果也非常不错.

上面可以到看,跨分区查询是,如果某个分区没有用到索引(p4就是全表扫描),整个也没有用到index.但好的是,只扫描需要的分区

上面可以看到,如果你不用分区的字段查询,是很杯具的,因为MySQL不知道你分区的index是分别存放到哪个分区上,所以要全index扫描,
3.顺便看看表结构
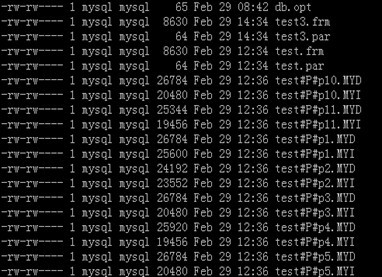
a. 图中test3 是innodb的存储引擎,
test3.frm是表结构.
test3.par是分区表的信息.
数据和索引都是存放在表空间里面在
b.图中test是myisam的存储引擎,
test.frm是表结构,
test.par是分区表的信息.
test#P#p10.MYD是数据文件之一,
test#P#p10.MYI是索引文件之一
1.创建一个测试表
[sql]
view plaincopy
CREATE TABLE test (
id VARCHAR(20) NOT NULL,
name VARCHAR(20) NOT NULL,
submit_time DATETIME NOT NULL,
index time_index (submit_time),
index id_index (id)
)ENGINE=MyISAM
PARTITION BY RANGE COLUMNS(submit_time)
(
PARTITION p1 VALUES LESS THAN ('2010-02-01'),
PARTITION p2 VALUES LESS THAN ('2010-03-01'),
PARTITION p3 VALUES LESS THAN ('2010-04-01'),
PARTITION p4 VALUES LESS THAN ('2010-05-01'),
PARTITION p5 VALUES LESS THAN ('2010-06-01'),
PARTITION p6 VALUES LESS THAN ('2010-07-01'),
PARTITION p7 VALUES LESS THAN ('2010-08-01'),
PARTITION p8 VALUES LESS THAN ('2010-09-01'),
PARTITION p9 VALUES LESS THAN ('2010-10-01'),
PARTITION p10 VALUES LESS THAN ('2010-11-01'),
PARTITION p11 VALUES LESS THAN ('2010-12-01')
);
2.写一个存储过程,插入数据
[sql]
view plaincopy
delimiter //
CREATE PROCEDURE mark_test()
begin
declare v int default 0;
while v < 8000
do
insert into test values (v,'testing partitions',adddate('2010-01-01', INTERVAL v hour));
set v = v + 1;
end while;
end //
delimiter ;
3.实验开始
上面可以看到,这个是查某一个分区里面的某一些内容,所以完全可以用到index.效果很好..
上面可以看到,跨分区查询,效果也非常不错.
上面可以到看,跨分区查询是,如果某个分区没有用到索引(p4就是全表扫描),整个也没有用到index.但好的是,只扫描需要的分区
上面可以看到,如果你不用分区的字段查询,是很杯具的,因为MySQL不知道你分区的index是分别存放到哪个分区上,所以要全index扫描,
3.顺便看看表结构
a. 图中test3 是innodb的存储引擎,
test3.frm是表结构.
test3.par是分区表的信息.
数据和索引都是存放在表空间里面在
b.图中test是myisam的存储引擎,
test.frm是表结构,
test.par是分区表的信息.
test#P#p10.MYD是数据文件之一,
test#P#p10.MYI是索引文件之一

相关文章推荐
- cqchi mysql常用的日期加减函数与实例教程
- MySQL命令使用手记
- mysql分页pagination
- mysql 基本使用
- mysql和sql时间 字段比较大小的问题
- win7系统用sqlyog连接ubuntu虚拟机上的mysql数据库
- mysql之主从复制
- 遇到的一些mysql语句
- MySQL:讨人喜欢的 MySQL replace into 用法(insert into 的增强版)
- mysql的基本语句(一)
- 【MySQL索引】Hash索引与B-Tree索引 介绍及区别
- ubuntu12.04 下设置mysql显示中文乱码问题
- MySQL的Galera Cluster介绍及其配置说明
- 超详细mysql left join,right join,inner join用法分析
- Mysql事物处理
- mysql读写分离
- mysql 中插入语句的错误
- MySQL 主主同步配置
- 【十分钟系列课程】第一集~MySQL 的安装启动和关闭
- MySQL-Cluster7.2.5安装和配置