各种数据结构优缺点分析
2014-02-21 11:35
399 查看
http://shellblog.sinaapp.com/?p=52
数组
优点:插入块如果知道坐标可以快速去地存取
缺点:查找慢,删除慢,大小固定
有序数组
优点:比无序数组查找快
缺点:删除和插入慢,大小固定
栈
优点:提供后进先出的存取方式
缺点:存取其他项很慢
队列
优点:提供先进先出的存取方式
缺点:存取其他项都很慢
链表
优点:插入快,删除快
缺点:查找慢
二叉树
优点:查找,插入,删除都快(如果数保持平衡)
缺点:删除算法复杂
红-黑树
优点:查找,插入,删除都快,树总是平衡的
缺点:算法复杂
2-3-4树
优点:查找,插入,删除都快,树总是平衡的。类似的树对磁盘存储有用
缺点:算法复杂
哈希表
优点:如果关键字已知则存取速度极快,插入块
缺点:删除慢,如果不知道关键则存取很慢,对存储空间使用不充分
堆
优点:插入,删除块,对最大数据的项存取很快
缺点:对其他数据项存取很慢
图
优点:对现实世界建模
缺点:有些算法慢且复杂
http://www.cppblog.com/cxiaojia/archive/2012/08/06/186432.html
二叉树首先是一棵树,每个节点都不能有多于两个的儿子,也就是树的度不能超过2。二叉树的两个儿子分别称为“左儿子”和“右儿子”,次序不能颠倒。
一种是满二叉树,除了最后一层的叶子节点外,每一层的节点都必须有两个儿子节点。
另一种是完全二叉树,一棵二叉树去掉最后一层后剩下的节点组成的树为满二叉树,最后一层的节点从左到右连续,没有空出的节点,这样的树称为完全二叉树。
http://blog.csdn.net/v_JULY_v/article/details/6105630
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
任意节点的左、右子树也分别为二叉查找树。
没有键值相等的节点(no duplicate nodes)。
平衡树是计算机科学中的一类数据结构。
平衡树是计算机科学中的一类改进的二叉查找树。一般的二叉查找树的查询复杂度是跟目标结点到树根的距离(即深度)有关,因此当结点的深度普遍较大时,查询的均摊复杂度会上升,为了更高效的查询,平衡树应运而生了。
几乎所有平衡树的操作都基于树旋转操作,通过旋转操作可以使得树趋于平衡。 对一棵查找树(search tree)进行查询/新增/删除 等动作, 所花的时间与树的高度h 成比例, 并不与树的容量 n 成比例。如果可以让树维持矮矮胖胖的好身材, 也就是让h维持在O(lg n)左右, 完成上述工作就很省时间。能够一直维持好身材,
不因新增删除而长歪的搜寻树, 叫做balanced search tree(平衡树)。
而红黑树,能保证在最坏情况下,基本的动态几何操作的时间均为O(lgn)。
ok,我们知道,红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。
一般的,红黑树,满足以下性质,即只有满足以下全部性质的树,我们才称之为红黑树:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
(注:上述第3、5点性质中所说的NULL结点,包括wikipedia.算法导论上所认为的叶子结点即为树尾端的NIL指针,或者说NULL结点。然百度百科以及网上一些其它博文直接说的叶结点,则易引起误会,因,此叶结点非子结点)
/article/1439367.html
2-3-4 树把数据存储在叫做元素的单独单元中。那么请问,到底什么是2-3-4树呢?顾名思义,就是有2个子女,3个子女,或4个子女的结点,这些含有2、3、或4个子女的结点就构成了我们的2-3-4树。所以,它们组合成结点,每个结点都是下列之一:
2-节点,就是说,它包含 1 个元素和 2 个儿子,
3-节点,就是说,它包含 2 个元素和 3 个儿子,
4-节点,就是说,它包含 3 个元素和 4 个儿子 。
/article/1439368.html
B 树又叫平衡多路查找树。一棵m阶的B 树 (注:切勿简单的认为一棵m阶的B树是m叉树,虽然存在四叉树,八叉树,KD树,及vp/R树/R*树/R+树/X树/M树/线段树/希尔伯特R树/优先R树等空间划分树,但与B树完全不等同)的特性如下:
树中每个结点最多含有m个孩子(m>=2);
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);(读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@研究者July:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:
一棵R树满足如下的性质:
1. 除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
2. 对于所有在叶子中存储的记录(条目),I是最小的可以在空间中完全覆盖这些记录所代表的点的矩形(注意:此处所说的“矩形”是可以扩展到高维空间的)。
3. 每一个非叶子结点拥有m至M个孩子结点,除非它是根结点。
4. 对于在非叶子结点上的每一个条目,i是最小的可以在空间上完全覆盖这些条目所代表的店的矩形(同性质2)。
5. 所有叶子结点都位于同一层,因此R树为平衡树。
其中,tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。I=(I0,I1,…,In-1)。其结构如下图所示:

下图描述的就是在二维空间中的叶子结点所要存储的信息。
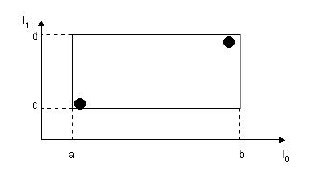
在这张图中,I所代表的就是图中的矩形,其范围是a<=I0<=b,c<=I1<=d。有两个tuple-identifier,在图中即表示为那两个点。这种形式完全可以推广到高维空间。大家简单想想三维空间中的样子就可以了。这样,叶子结点的结构就介绍完了。
同样道理,R树的非叶子结点存放的数据结构为:(I, child-pointer)。
其中,child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。这边有点拗口,但我想不是很难懂?给张图:
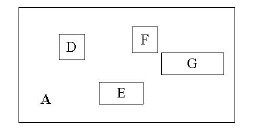
D,E,F,G为孩子结点所对应的矩形。A为能够覆盖这些矩形的更大的矩形。这个A就是这个非叶子结点所对应的矩形。这时候你应该悟到了吧?无论是叶子结点还是非叶子结点,它们都对应着一个矩形。树形结构上层的结点所对应的矩形能够完全覆盖它的孩子结点所对应的矩形。根结点也唯一对应一个矩形,而这个矩形是可以覆盖所有我们拥有的数据信息在空间中代表的点的。
我个人感觉这张图画的不那么精确,应该是矩形A要恰好覆盖D,E,F,G,而不应该再留出这么多没用的空间了。但为尊重原图的绘制者,特不作修改。
http://zh.wikipedia.org/wiki/%E5%93%88%E5%B8%8C%E8%A1%A8
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名

到首字母

的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则

,存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
http://dongxicheng.org/structure/heap/
http://zh.wikipedia.org/wiki/%E5%A0%86_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
http://www.cppblog.com/guogangj/archive/2009/10/29/99729.html
堆(英语:heap)亦被称为:优先队列(英语:priority queue),是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。在队列中,调度程序反复提取队列中第一个作业并运行,因而实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构。
首先说说数据结构概念——堆(Heap),其实也没什么大不了,简单地说就是一种有序队列而已,普通的队列是先入先出,而二叉堆是:最小先出。
这不是很简单么?如果这个队列是用数组实现的话那用打擂台的方式从头到尾找一遍,把最小的拿出来不就行了?行啊,可是出队的操作是很频繁的,而每次都得打一遍擂台,那就低效了,打擂台的时间复杂度为Ο(n),那如何不用从头到尾fetch一遍就出队呢?二叉堆能比较好地解决这个问题,不过之前先介绍一些概念。
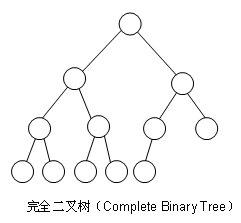
完全树(Complete Tree):从下图中看出,在第n层深度被填满之前,不会开始填第n+1层深度,还有一定是从左往右填满。
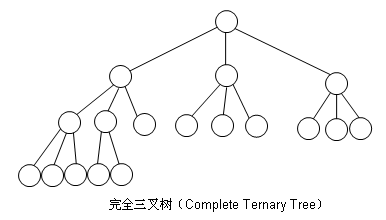
再来一棵完全三叉树:
这样有什么好处呢?好处就是能方便地把指针省略掉,用一个简单的数组来表示一棵树,如图:
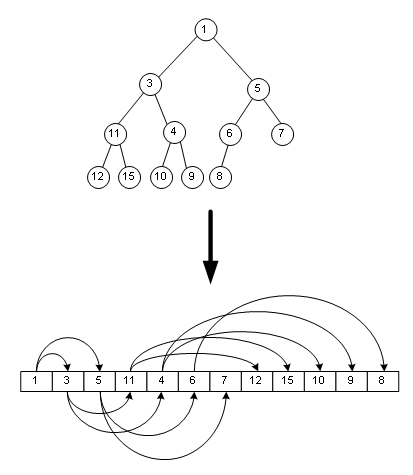
http://blog.chinaunix.net/uid-21813514-id-3866951.html
一、图的存储结构
1.1 邻接矩阵
图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:

看一个实例,下图左就是一个无向图。

从上面可以看出,无向图的边数组是一个对称矩阵。所谓对称矩阵就是n阶矩阵的元满足aij =
aji。即从矩阵的左上角到右下角的主对角线为轴,右上角的元和左下角相对应的元全都是相等的。
从这个矩阵中,很容易知道图中的信息。
(1)要判断任意两顶点是否有边无边就很容易了;
(2)要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
(3)求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点;
而有向图讲究入度和出度,顶点vi的入度为1,正好是第i列各数之和。顶点vi的出度为2,即第i行的各数之和。
若图G是网图,有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:

这里的wij表示(vi,vj)上的权值。无穷大表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。下面左图就是一个有向网图,右图就是它的邻接矩阵。

数组
优点:插入块如果知道坐标可以快速去地存取
缺点:查找慢,删除慢,大小固定
有序数组
优点:比无序数组查找快
缺点:删除和插入慢,大小固定
栈
优点:提供后进先出的存取方式
缺点:存取其他项很慢
队列
优点:提供先进先出的存取方式
缺点:存取其他项都很慢
链表
优点:插入快,删除快
缺点:查找慢
二叉树
优点:查找,插入,删除都快(如果数保持平衡)
缺点:删除算法复杂
红-黑树
优点:查找,插入,删除都快,树总是平衡的
缺点:算法复杂
2-3-4树
优点:查找,插入,删除都快,树总是平衡的。类似的树对磁盘存储有用
缺点:算法复杂
哈希表
优点:如果关键字已知则存取速度极快,插入块
缺点:删除慢,如果不知道关键则存取很慢,对存储空间使用不充分
堆
优点:插入,删除块,对最大数据的项存取很快
缺点:对其他数据项存取很慢
图
优点:对现实世界建模
缺点:有些算法慢且复杂
http://www.cppblog.com/cxiaojia/archive/2012/08/06/186432.html
二叉树首先是一棵树,每个节点都不能有多于两个的儿子,也就是树的度不能超过2。二叉树的两个儿子分别称为“左儿子”和“右儿子”,次序不能颠倒。
一种是满二叉树,除了最后一层的叶子节点外,每一层的节点都必须有两个儿子节点。
另一种是完全二叉树,一棵二叉树去掉最后一层后剩下的节点组成的树为满二叉树,最后一层的节点从左到右连续,没有空出的节点,这样的树称为完全二叉树。
http://blog.csdn.net/v_JULY_v/article/details/6105630
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
任意节点的左、右子树也分别为二叉查找树。
没有键值相等的节点(no duplicate nodes)。
平衡树是计算机科学中的一类数据结构。
平衡树是计算机科学中的一类改进的二叉查找树。一般的二叉查找树的查询复杂度是跟目标结点到树根的距离(即深度)有关,因此当结点的深度普遍较大时,查询的均摊复杂度会上升,为了更高效的查询,平衡树应运而生了。
几乎所有平衡树的操作都基于树旋转操作,通过旋转操作可以使得树趋于平衡。 对一棵查找树(search tree)进行查询/新增/删除 等动作, 所花的时间与树的高度h 成比例, 并不与树的容量 n 成比例。如果可以让树维持矮矮胖胖的好身材, 也就是让h维持在O(lg n)左右, 完成上述工作就很省时间。能够一直维持好身材,
不因新增删除而长歪的搜寻树, 叫做balanced search tree(平衡树)。
而红黑树,能保证在最坏情况下,基本的动态几何操作的时间均为O(lgn)。
ok,我们知道,红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。
一般的,红黑树,满足以下性质,即只有满足以下全部性质的树,我们才称之为红黑树:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点(叶结点即指树尾端NIL指针或NULL结点)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对于任一结点而言,其到叶结点树尾端NIL指针的每一条路径都包含相同数目的黑结点。
(注:上述第3、5点性质中所说的NULL结点,包括wikipedia.算法导论上所认为的叶子结点即为树尾端的NIL指针,或者说NULL结点。然百度百科以及网上一些其它博文直接说的叶结点,则易引起误会,因,此叶结点非子结点)
/article/1439367.html
2-3-4 树把数据存储在叫做元素的单独单元中。那么请问,到底什么是2-3-4树呢?顾名思义,就是有2个子女,3个子女,或4个子女的结点,这些含有2、3、或4个子女的结点就构成了我们的2-3-4树。所以,它们组合成结点,每个结点都是下列之一:
2-节点,就是说,它包含 1 个元素和 2 个儿子,
3-节点,就是说,它包含 2 个元素和 3 个儿子,
4-节点,就是说,它包含 3 个元素和 4 个儿子 。
/article/1439368.html
B 树又叫平衡多路查找树。一棵m阶的B 树 (注:切勿简单的认为一棵m阶的B树是m叉树,虽然存在四叉树,八叉树,KD树,及vp/R树/R*树/R+树/X树/M树/线段树/希尔伯特R树/优先R树等空间划分树,但与B树完全不等同)的特性如下:
树中每个结点最多含有m个孩子(m>=2);
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);(读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@研究者July:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:
一棵R树满足如下的性质:
1. 除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
2. 对于所有在叶子中存储的记录(条目),I是最小的可以在空间中完全覆盖这些记录所代表的点的矩形(注意:此处所说的“矩形”是可以扩展到高维空间的)。
3. 每一个非叶子结点拥有m至M个孩子结点,除非它是根结点。
4. 对于在非叶子结点上的每一个条目,i是最小的可以在空间上完全覆盖这些条目所代表的店的矩形(同性质2)。
5. 所有叶子结点都位于同一层,因此R树为平衡树。
叶子结点的结构
先来探究一下叶子结点的结构。叶子结点所保存的数据形式为:(I, tuple-identifier)。其中,tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。I=(I0,I1,…,In-1)。其结构如下图所示:
下图描述的就是在二维空间中的叶子结点所要存储的信息。
在这张图中,I所代表的就是图中的矩形,其范围是a<=I0<=b,c<=I1<=d。有两个tuple-identifier,在图中即表示为那两个点。这种形式完全可以推广到高维空间。大家简单想想三维空间中的样子就可以了。这样,叶子结点的结构就介绍完了。
非叶子结点
非叶子结点的结构其实与叶子结点非常类似。想象一下B树就知道了,B树的叶子结点存放的是真实存在的数据,而非叶子结点存放的是这些数据的“边界”,或者说也算是一种索引(有疑问的读者可以回顾一下上述第一节中讲解B树的部分)。同样道理,R树的非叶子结点存放的数据结构为:(I, child-pointer)。
其中,child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。这边有点拗口,但我想不是很难懂?给张图:
D,E,F,G为孩子结点所对应的矩形。A为能够覆盖这些矩形的更大的矩形。这个A就是这个非叶子结点所对应的矩形。这时候你应该悟到了吧?无论是叶子结点还是非叶子结点,它们都对应着一个矩形。树形结构上层的结点所对应的矩形能够完全覆盖它的孩子结点所对应的矩形。根结点也唯一对应一个矩形,而这个矩形是可以覆盖所有我们拥有的数据信息在空间中代表的点的。
我个人感觉这张图画的不那么精确,应该是矩形A要恰好覆盖D,E,F,G,而不应该再留出这么多没用的空间了。但为尊重原图的绘制者,特不作修改。
http://zh.wikipedia.org/wiki/%E5%93%88%E5%B8%8C%E8%A1%A8
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名
到首字母
的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则
,存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
http://dongxicheng.org/structure/heap/
http://zh.wikipedia.org/wiki/%E5%A0%86_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
http://www.cppblog.com/guogangj/archive/2009/10/29/99729.html
堆(英语:heap)亦被称为:优先队列(英语:priority queue),是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。在队列中,调度程序反复提取队列中第一个作业并运行,因而实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构。
首先说说数据结构概念——堆(Heap),其实也没什么大不了,简单地说就是一种有序队列而已,普通的队列是先入先出,而二叉堆是:最小先出。
这不是很简单么?如果这个队列是用数组实现的话那用打擂台的方式从头到尾找一遍,把最小的拿出来不就行了?行啊,可是出队的操作是很频繁的,而每次都得打一遍擂台,那就低效了,打擂台的时间复杂度为Ο(n),那如何不用从头到尾fetch一遍就出队呢?二叉堆能比较好地解决这个问题,不过之前先介绍一些概念。
完全树(Complete Tree):从下图中看出,在第n层深度被填满之前,不会开始填第n+1层深度,还有一定是从左往右填满。
再来一棵完全三叉树:
这样有什么好处呢?好处就是能方便地把指针省略掉,用一个简单的数组来表示一棵树,如图:
http://blog.chinaunix.net/uid-21813514-id-3866951.html
一、图的存储结构
1.1 邻接矩阵
图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
看一个实例,下图左就是一个无向图。
从上面可以看出,无向图的边数组是一个对称矩阵。所谓对称矩阵就是n阶矩阵的元满足aij =
aji。即从矩阵的左上角到右下角的主对角线为轴,右上角的元和左下角相对应的元全都是相等的。
从这个矩阵中,很容易知道图中的信息。
(1)要判断任意两顶点是否有边无边就很容易了;
(2)要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
(3)求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点;
而有向图讲究入度和出度,顶点vi的入度为1,正好是第i列各数之和。顶点vi的出度为2,即第i行的各数之和。
若图G是网图,有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
这里的wij表示(vi,vj)上的权值。无穷大表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。下面左图就是一个有向网图,右图就是它的邻接矩阵。

相关文章推荐
- 数据结构实验:哈希表
- 哈希表算法
- 数据结构--快速、冒泡、选择排序C语言实现
- 数据结构上机实验之二分查找
- MySql无限分类数据结构--预排序遍历树算法
- 教你如何迅速秒杀掉:99%的海量数据处理
- 数据结构-链表创建,删除,插入,反转,连接
- 【数据结构和算法那些事】--【2】--选择排序
- POJ 3468 A Simple Problem with Integers 线段树 (成段更新)
- 数据结构——双向链表(C语言)
- 数据结构上机测试1:顺序表的应用!!!
- 数据结构学习笔记7(树)
- 数据结构上机测试1:顺序表的应用
- 【数据结构和算法那些事】--【1】--冒泡排序
- POJ - 1703 Find them, Catch them (并查集2)
- 数据结构实验之栈四:括号匹配
- 数据结构实验图论一:基于邻接矩阵的广度优先搜索遍历
- 数据结构学习笔记7(第三章作业)
- POJ - 2236 Wireless Network (并查集)
- Step By Step(Lua数据结构)