分布式锁服务ZooKeeper
2014-01-24 11:52
183 查看
ZooKeeper的安装和配置:
下载ZooKeeper
解压:tar -xzvf zookeeper-3.4.3.tar.gz
在conf目录下创建一个配置文件zoo.cfg,tickTime=2000
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog clientPort=2181
启动ZooKeeper的Server:sh bin/zkServer.sh start, 如果想要关闭,输入:zkServer.sh stop
创建myid文件,server1机器的内容为:1,server2机器的内容为:2,server3机器的内容为:3
在conf目录下创建一个配置文件zoo.cfg,tickTime=2000
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
clientPort=2181
initLimit=5
syncLimit=2
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
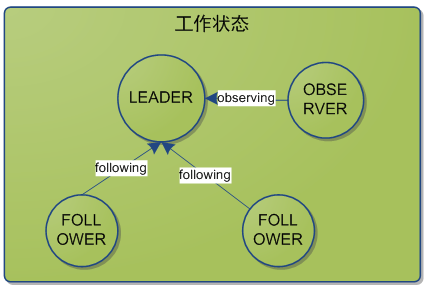
ZooKeeper的角色:
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方

ZooKeeper的工作原理:
Zookeeper的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在Broadcast状态,直到leader崩溃了或者leader失去了大部分的followers支持。
广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64为的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
leader选举
每个Server启动以后都询问其它的Server它要投票给谁?
对于其他server的询问,server每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统启动时每个server都会推荐自己)
收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。
计算这过程中获得票数最多的的sever为获胜者,如果获胜者的票数超过半数,则改server被选为leader。否则,继续这个过程,直到leader被选举出来。
leader就会开始等待server连接
Follower连接leader,将最大的zxid发送给leader
Leader根据follower的zxid确定同步点
完成同步后通知follower 已经成为uptodate状态
Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。

Zookeeper
下载ZooKeeper
解压:tar -xzvf zookeeper-3.4.3.tar.gz
在conf目录下创建一个配置文件zoo.cfg,tickTime=2000
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog clientPort=2181
启动ZooKeeper的Server:sh bin/zkServer.sh start, 如果想要关闭,输入:zkServer.sh stop
创建myid文件,server1机器的内容为:1,server2机器的内容为:2,server3机器的内容为:3
在conf目录下创建一个配置文件zoo.cfg,tickTime=2000
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
clientPort=2181
initLimit=5
syncLimit=2
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
ZooKeeper的角色:
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方
ZooKeeper的工作原理:
Zookeeper的核心是原子广播,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server的完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
一旦leader已经和多数的follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个server加入zookeeper服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步。待到同步结束,它也参与消息广播。Zookeeper服务一直维持在Broadcast状态,直到leader崩溃了或者leader失去了大部分的followers支持。
广播模式需要保证proposal被按顺序处理,因此zk采用了递增的事务id号(zxid)来保证。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64为的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch。低32位是个递增计数。
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的server都恢复到一个正确的状态。
leader选举
每个Server启动以后都询问其它的Server它要投票给谁?
对于其他server的询问,server每次根据自己的状态都回复自己推荐的leader的id和上一次处理事务的zxid(系统启动时每个server都会推荐自己)
收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。
计算这过程中获得票数最多的的sever为获胜者,如果获胜者的票数超过半数,则改server被选为leader。否则,继续这个过程,直到leader被选举出来。
leader就会开始等待server连接
Follower连接leader,将最大的zxid发送给leader
Leader根据follower的zxid确定同步点
完成同步后通知follower 已经成为uptodate状态
Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。
Zookeeper

相关文章推荐
- Numbering conventions of strings and bitsets
- CloudStack 实现VM高可用特性
- linux使用scp命令备份文件 scp拷贝文件
- sql 查询
- 声音和电磁波
- 关于未来超高效存储设备的设想
- GNS3路由器与模拟三层交换的交换模块相连时不能全双工
- iOS应用程序生命周期(前后台切换,应用的各种状态)详解
- 如何让CloudStack使用KVM创建Windows实例成功识别并挂载数据盘
- 石基信息:战略性收购思迅软件,线下支付平台布局完善
- C#調用User32api
- timer-----内核定时器
- 特写:逐浪CMS失败的五个支点兼谈中国软件业的发展之现状
- windows下体验Redis
- Effective JavaScript 读书笔记 1 严格模式
- 如何打造一份超级简历
- 使用Google code + SVN进行多人开发
- header导出Excel你做过吗?
- Java编程中实现Cloneable接口,让类的对象可以复制
- IT运维外包甩不掉的包袱