利用二级指针删除单向链表
2013-12-26 14:59
337 查看
http://coolshell.cn/articles/8990.html
Linus举了一个单向链表的例子,但给出的代码太短了,一般的人很难搞明白这两个代码后面的含义。正好,有个编程爱好者阅读了这段话,并给出了一个比较完整的代码。他的话我就不翻译了,下面给出代码说明。
如果我们需要写一个remove_if(link*, rm_cond_func*)的函数,也就是传入一个单向链表,和一个自定义的是否删除的函数,然后返回处理后的链接。
这个代码不难,基本上所有的教科书都会提供下面的代码示例,而这种写法也是大公司的面试题标准模板:
这里remove_fn由调用查提供的一个是否删除当前实体结点的函数指针,其会判断删除条件是否成立。这段代码维护了两个节点指针prev和curr,标准的教科书写法——删除当前结点时,需要一个previous的指针,并且还要这里还需要做一个边界条件的判断——curr是否为链表头。于是,要删除一个节点(不是表头),只要将前一个节点的next指向当前节点的next指向的对象,即下一个节点(即:prev->next = curr->next),然后释放当前节点。
但在Linus看来,这是不懂指针的人的做法。那么,什么是core low-level coding呢?那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。代码如下:
同上一段代码有何改进呢?我们看到:不需要prev指针了,也不需要再去判断是否为链表头了,但是,curr变成了一个指向指针的指针。这正是这段程序的精妙之处。(注意,我所highlight的那三行代码)
让我们来人肉跑一下这个代码,对于——
删除节点是表头的情况,输入参数中传入head的二级指针,在for循环里将其初始化curr,然后entry就是*head(*curr),我们马上删除它,那么第8行就等效于*head = (*head)->next,就是删除表头的实现。
删除节点不是表头的情况,对于上面的代码,我们可以看到——
1)[b](第12行)如果不删除当前结点 —— curr保存的是当前结点next指针的地址[/b]。
2)(第5行) entry 保存了 *curr [b]—— 这意味着在下一次循环:entry就是prev->next指针所指向的内存。[/b]
3)(第8行)删除结点:*curr = entry->next; —— 于是:prev->next 指向了 entry -> next;
是不是很巧妙?我们可以只用一个二级指针来操作链表,对所有节点都一样。
如果你对上面的代码和描述理解上有困难的话,你可以看看下图的示意:
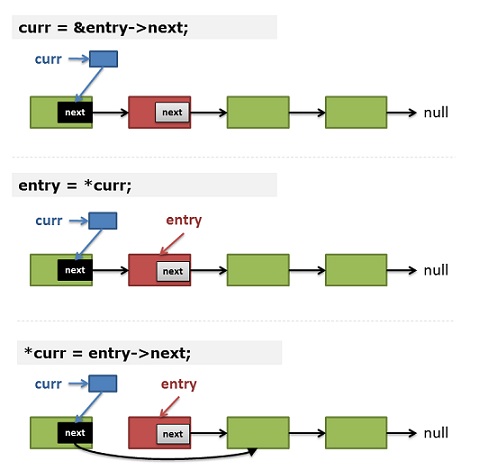
换言之,如果一个单向链表,next是第一个字段,我们可以用一个二级指针dummy引用一条链表上的所有节点。
struct node **dummy = &head->next;
一次解引用*dummy指向头结点head
二次解引用**dummy指向head下一个节点
三次解引用*(*(*dummy))指向第三个节点
以此类推……
如果我们需要找到从head开始的第N个节点,那么对dummy进行N次解引用即可,当然现实工程中一般不会用到这么tricky的语法糖,但使用一个变量同时引用相邻三个节点是很有用的;-)。
给还不明白的同学论证一下,见如下代码
typedef struct list_s{
struct list_s * next;
int a;
int b;
} list_t;
main()
{
list_t lA, lB, lC, lD;
list_t ** phead = &lA.next;
lA.next = &lB;
lA.a = 11;
lA.b = 12;
lB.next = &lC;
lB.a = 21;
lB.b = 22;
lC.next = &lD;
lC.a = 31;
lC.b = 32;
lD.next = NULL;
lD.a = 41;
lD.b = 42;
printf(“%d\n”, ((list_t *)phead)->a);
printf(“%d\n”, (**(list_t**)phead).a);
printf(“%d\n”, (***(list_t***)phead).a);
printf(“%d\n”, (****(list_t****)phead).a);
printf(“%d\n”, ((list_t *)phead)->b);
printf(“%d\n”, (**(list_t**)phead).b);
printf(“%d\n”, (***(list_t***)phead).b);
printf(“%d\n”, (****(list_t****)phead).b);
}
gcc的结果是
11
21
31
41
12
22
32
42
Linus举了一个单向链表的例子,但给出的代码太短了,一般的人很难搞明白这两个代码后面的含义。正好,有个编程爱好者阅读了这段话,并给出了一个比较完整的代码。他的话我就不翻译了,下面给出代码说明。
如果我们需要写一个remove_if(link*, rm_cond_func*)的函数,也就是传入一个单向链表,和一个自定义的是否删除的函数,然后返回处理后的链接。
这个代码不难,基本上所有的教科书都会提供下面的代码示例,而这种写法也是大公司的面试题标准模板:
但在Linus看来,这是不懂指针的人的做法。那么,什么是core low-level coding呢?那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。代码如下:
让我们来人肉跑一下这个代码,对于——
删除节点是表头的情况,输入参数中传入head的二级指针,在for循环里将其初始化curr,然后entry就是*head(*curr),我们马上删除它,那么第8行就等效于*head = (*head)->next,就是删除表头的实现。
删除节点不是表头的情况,对于上面的代码,我们可以看到——
1)[b](第12行)如果不删除当前结点 —— curr保存的是当前结点next指针的地址[/b]。
2)(第5行) entry 保存了 *curr [b]—— 这意味着在下一次循环:entry就是prev->next指针所指向的内存。[/b]
3)(第8行)删除结点:*curr = entry->next; —— 于是:prev->next 指向了 entry -> next;
是不是很巧妙?我们可以只用一个二级指针来操作链表,对所有节点都一样。
如果你对上面的代码和描述理解上有困难的话,你可以看看下图的示意:
#include <stdio.h>
#include <iostream>
using namespace std;
struct node {
int a;
node *next;
};
void print(node* head) {
for(;head!=NULL;head = head->next) {
cout << head->a << " ";
}
cout << endl;
}
//this method is brief
node* rm(node* head,int val) {
node *pre = NULL;
node *curr = head;
for (;curr != NULL;) {
node *next = curr->next;
if(curr->a%2 == val) {
if (pre == NULL) {
head = next;
}
else {
pre->next = next;
}
free(curr);
}
else {
pre = curr;
}
curr = next;
}
return head;
}
void remove(node **head, int val) {
//curr指向的是当前节点的指针的指针
//对于中间节点而言,当前节点的指针和其前一个节点的next是一样的,所以可以看做是前一个节点的next的指针
for (node** curr = head; *curr != NULL;) {
node *entry = *curr;//entry是当前节点的指针//1. curr是头节点,那么*curr = entry->next,就是指head指向了下一个节点//2.如果curr是中间节点,则curr是前一个节点next的指针
if (entry->a % 2 == val) {
*curr = entry->next;
free(entry);
}
else {
curr = &(entry->next);
}
}
}
int main() {
node *head = (node*)malloc(sizeof(node));
head->a = 1;
node *a = (node*)malloc(sizeof(node));
a->a = 2;
node *b = (node*)malloc(sizeof(node));
b->a = 3;
node *c = (node*)malloc(sizeof(node));
c->a = 4;
node *d = (node*)malloc(sizeof(node));
d->a = 5;
head->next = a;
a->next = b;
b->next = c;
c->next = d;
d->next = NULL;
print(head);
remove(&head,0);
print(head);
return 1;
}换言之,如果一个单向链表,next是第一个字段,我们可以用一个二级指针dummy引用一条链表上的所有节点。
struct node **dummy = &head->next;
一次解引用*dummy指向头结点head
二次解引用**dummy指向head下一个节点
三次解引用*(*(*dummy))指向第三个节点
以此类推……
如果我们需要找到从head开始的第N个节点,那么对dummy进行N次解引用即可,当然现实工程中一般不会用到这么tricky的语法糖,但使用一个变量同时引用相邻三个节点是很有用的;-)。
给还不明白的同学论证一下,见如下代码
typedef struct list_s{
struct list_s * next;
int a;
int b;
} list_t;
main()
{
list_t lA, lB, lC, lD;
list_t ** phead = &lA.next;
lA.next = &lB;
lA.a = 11;
lA.b = 12;
lB.next = &lC;
lB.a = 21;
lB.b = 22;
lC.next = &lD;
lC.a = 31;
lC.b = 32;
lD.next = NULL;
lD.a = 41;
lD.b = 42;
printf(“%d\n”, ((list_t *)phead)->a);
printf(“%d\n”, (**(list_t**)phead).a);
printf(“%d\n”, (***(list_t***)phead).a);
printf(“%d\n”, (****(list_t****)phead).a);
printf(“%d\n”, ((list_t *)phead)->b);
printf(“%d\n”, (**(list_t**)phead).b);
printf(“%d\n”, (***(list_t***)phead).b);
printf(“%d\n”, (****(list_t****)phead).b);
}
gcc的结果是
11
21
31
41
12
22
32
42

相关文章推荐
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表 | 酷壳 - CoolShell.cn
- Linus:利用二级指针删除单向链表
- 链表:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表 转自酷壳 – CoolShell.cn
- 【转】Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表
- Linus:利用二级指针删除单向链表-实例代码
- 利用二级指针删除单向链表节点
- 利用二级指针插入和删除单向链表