STL源码剖析之哈希表 hashtable【2013.12.06】
2013-12-06 12:35
239 查看
STL源码剖析之哈希表 hashtable【2013.12.06】
欢迎加入我们的QQ群,无论你是否工作,学生,只要有c / vc / c++ 编程经验,就来吧!158427611
哈希表,一种键值对用的关系。具有关联性。
也称散列表,主要是通过特殊算法建立值和键的关系,然后根据键值对应存储和搜索。
因为是键值对应的关系,所以再键的存储上面,会出现一种【碰撞】问题,即根据算法计算两个不同的值对应了同一个键,因为导致键的存储冲突。
哈希表根据解决【碰撞】的方案不同而产生了几种存储表现,不同的存储表现有不同的存储搜索效率。
线性探测,二次探测,开链。
【一】线性探测
在哈希表的连续空间上,当发生冲突的时候,向后存储。

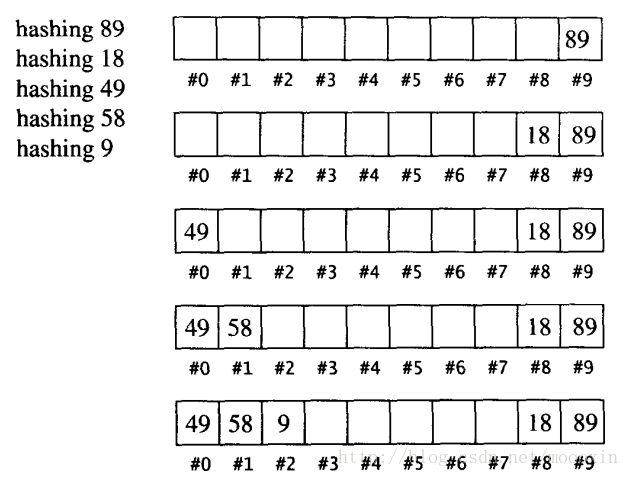
这种探测方法产生的问题:
需要一个很大的空间,而且依赖于数据的独立性(尽量使数据对应独立的键)。
【二次探测】
二次探测其实是对 线性探测的一种优化,即当第一次探测出现碰撞问题的时候,再进行算法探测,的算法探测就是一种二次方算法:

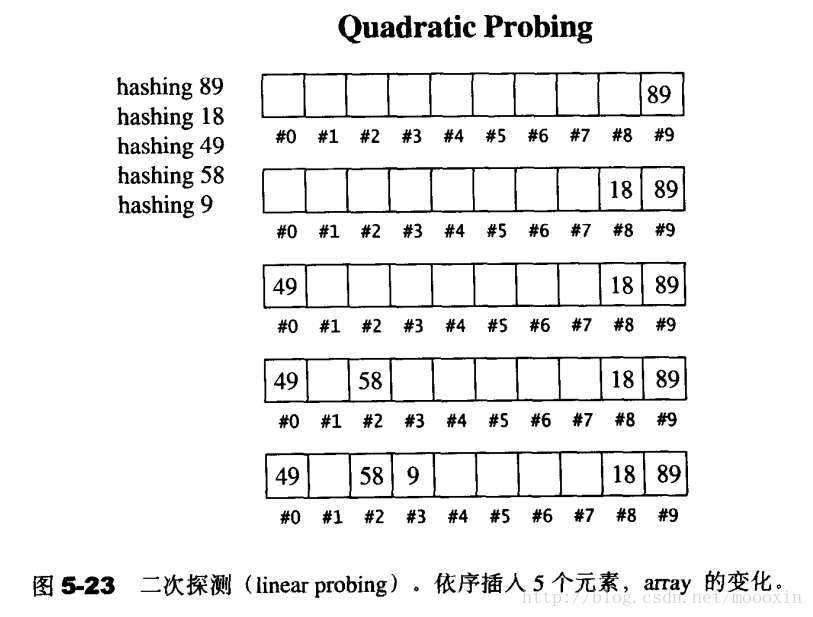
二次探测虽然表上解决了线性探测的问题,
但是他其实值是推迟了线性探测的问题,也以来数据独立性。
【开链】
开链的方法,就是在对应键下面维护一个链表,链表维护键对应下的所有值。


SGI STL中 hashtable容器的内部实现就是使用的【开链】方法。
其中键值序列,使用的是vector,而vector的大小,取的是一个质数集合,一共28个常数,大于53,且相邻质数的关系为:2的倍数中最接近的质数。
如果传入的键大小为50,那么hashtable建立的时候,就会取出__stl_prime_list的53,并建立vector。

SGI STL 中hashtable的键确定方法:为用值对大小(就是上面的这28个常数)取模。
而对应键的值序列用的单向的List,List是时时增长大小的,所以不用像键序列一样需要确定大小
由于值序列的List是单向的,所以hashtable只能 ++ 不能 --;
而且值List的最后一个指向的是下一个键节点。这样能够保证顺序遍历的高效。
同样,由于hashtable的存储方式,不能像红黑树一样做排序。即遍历出来的元素不是排序的,这和红黑树是不同的。
【注意】当hashtable的键vector大小重新分配的时候,hashtable原键的值List会重新分配,因为vector重建了,相当于键增加,那么原来的值对应的键可能就不同与原来分配的键,这样的情况就需要重新确定值的键。主要触发方法为hashtable<T>::resize(size_t )
如下:buchets为原键vector,tmp为新的。
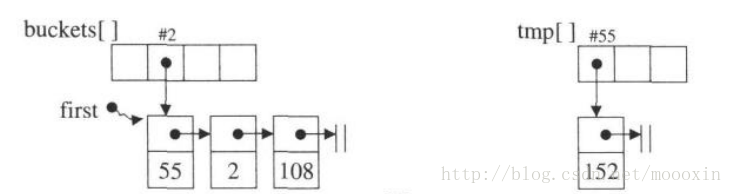
原来的hashtable大小为53,所以【55】【2】【108】这些元素 % 53都等于2
那么这些元素都存在键序列中值为2的节点下的List中。
当hashtable进行resize变成97的大小后,【52】%97 = 55 【2】%97 = 2【108】= 2 很明显取模97的值不全是2,
52元素要移到键序列值为 55 下的List中,所以要重整键序列下的List。
如图:

SGI STL为hashtable提供了hash function 在<stl_hash_fun.h>头文件中
全都是仿函数。
SGI STL中 hashtable的键确定方式就是取模,所以这些仿函数都是将各种类型做类型转换并返回原值(char . int . long 等)
唯独 不同的是 string char* 等字符串类型;做了不一样的转换:
如string

代码很清楚,就是遍历字符串字符,并运算,再返回无符号long。
至于字符指针char * 和const char *也是调用的string方法。

其他可以缺省转为整数的类型就不上代码了。
所以hashtable的键 其实都是要声明成为整形数据的,不然默认的方法是无法使用(因为默认的键确定方法是对值与28个常数取模,如果键声明为string,取出的模无法转成string,自然会编译错误的)的,当然你也可以自定义自己的键确定方法,并加到hashtable的声明中去,就可以正常使用了
string hashtable的错误使用方法如下:

如上声明方法,已经将key声明成string,但是没有指定符合要求的hash_func(确定key的仿函数)依旧是用的默认的。所以当插入数据的时候就无法生成正确的代码副本,当然就会编译错误。
上述代码,只要将hashtable的key声明为int 就可以了,其他不用变。
有兴趣的可以悄悄代码就知道了。
【hashtable正确运用范例】





由最后的遍历输出,可以看出,遍历hashtable得到的结果并不是排序的,这是和红黑树不同的一点。
原因就是变量是对键序列下值List的遍历。可能很大的值对应的键却很小。
欢迎加入我们的QQ群,无论你是否工作,学生,只要有c / vc / c++ 编程经验,就来吧!158427611
欢迎加入我们的QQ群,无论你是否工作,学生,只要有c / vc / c++ 编程经验,就来吧!158427611
哈希表,一种键值对用的关系。具有关联性。
也称散列表,主要是通过特殊算法建立值和键的关系,然后根据键值对应存储和搜索。
因为是键值对应的关系,所以再键的存储上面,会出现一种【碰撞】问题,即根据算法计算两个不同的值对应了同一个键,因为导致键的存储冲突。
哈希表根据解决【碰撞】的方案不同而产生了几种存储表现,不同的存储表现有不同的存储搜索效率。
线性探测,二次探测,开链。
【一】线性探测
在哈希表的连续空间上,当发生冲突的时候,向后存储。
这种探测方法产生的问题:
需要一个很大的空间,而且依赖于数据的独立性(尽量使数据对应独立的键)。
【二次探测】
二次探测其实是对 线性探测的一种优化,即当第一次探测出现碰撞问题的时候,再进行算法探测,的算法探测就是一种二次方算法:
二次探测虽然表上解决了线性探测的问题,
但是他其实值是推迟了线性探测的问题,也以来数据独立性。
【开链】
开链的方法,就是在对应键下面维护一个链表,链表维护键对应下的所有值。
SGI STL中 hashtable容器的内部实现就是使用的【开链】方法。
其中键值序列,使用的是vector,而vector的大小,取的是一个质数集合,一共28个常数,大于53,且相邻质数的关系为:2的倍数中最接近的质数。
如果传入的键大小为50,那么hashtable建立的时候,就会取出__stl_prime_list的53,并建立vector。
SGI STL 中hashtable的键确定方法:为用值对大小(就是上面的这28个常数)取模。
而对应键的值序列用的单向的List,List是时时增长大小的,所以不用像键序列一样需要确定大小
由于值序列的List是单向的,所以hashtable只能 ++ 不能 --;
而且值List的最后一个指向的是下一个键节点。这样能够保证顺序遍历的高效。
同样,由于hashtable的存储方式,不能像红黑树一样做排序。即遍历出来的元素不是排序的,这和红黑树是不同的。
【注意】当hashtable的键vector大小重新分配的时候,hashtable原键的值List会重新分配,因为vector重建了,相当于键增加,那么原来的值对应的键可能就不同与原来分配的键,这样的情况就需要重新确定值的键。主要触发方法为hashtable<T>::resize(size_t )
如下:buchets为原键vector,tmp为新的。
原来的hashtable大小为53,所以【55】【2】【108】这些元素 % 53都等于2
那么这些元素都存在键序列中值为2的节点下的List中。
当hashtable进行resize变成97的大小后,【52】%97 = 55 【2】%97 = 2【108】= 2 很明显取模97的值不全是2,
52元素要移到键序列值为 55 下的List中,所以要重整键序列下的List。
如图:
SGI STL为hashtable提供了hash function 在<stl_hash_fun.h>头文件中
全都是仿函数。
SGI STL中 hashtable的键确定方式就是取模,所以这些仿函数都是将各种类型做类型转换并返回原值(char . int . long 等)
唯独 不同的是 string char* 等字符串类型;做了不一样的转换:
如string
代码很清楚,就是遍历字符串字符,并运算,再返回无符号long。
至于字符指针char * 和const char *也是调用的string方法。
其他可以缺省转为整数的类型就不上代码了。
所以hashtable的键 其实都是要声明成为整形数据的,不然默认的方法是无法使用(因为默认的键确定方法是对值与28个常数取模,如果键声明为string,取出的模无法转成string,自然会编译错误的)的,当然你也可以自定义自己的键确定方法,并加到hashtable的声明中去,就可以正常使用了
string hashtable的错误使用方法如下:
如上声明方法,已经将key声明成string,但是没有指定符合要求的hash_func(确定key的仿函数)依旧是用的默认的。所以当插入数据的时候就无法生成正确的代码副本,当然就会编译错误。
上述代码,只要将hashtable的key声明为int 就可以了,其他不用变。
有兴趣的可以悄悄代码就知道了。
【hashtable正确运用范例】
由最后的遍历输出,可以看出,遍历hashtable得到的结果并不是排序的,这是和红黑树不同的一点。
原因就是变量是对键序列下值List的遍历。可能很大的值对应的键却很小。
欢迎加入我们的QQ群,无论你是否工作,学生,只要有c / vc / c++ 编程经验,就来吧!158427611

相关文章推荐
- STL源码剖析-关联式容器之hashtable
- STL源码剖析——hashtable
- STL源码剖析学习十一:hashtable
- Hashtable源码剖析
- 在C#中应用哈希表(Hashtable)[转摘]
- STL源码剖析之算法:iter_swap & swap
- STL源码剖析——STL算法之sort排序算法
- 哈希表(HashTable)的用法
- STL源码剖析之算法:prev_permutation
- Hashtable源码剖析
- STL源码剖析之Deque的Adapter
- C++ 哈希表(hashtable)
- (转)C# (线程安全的哈希表)Hashtable Synchronized vs SyncRoot
- HashSet, HashTable,HashMap区别剖析
- C#中的哈希表(Hashtable)应用
- STL源码剖析 - 第2章 空间配置器
- 哈希表(HashTable)
- 哈希表(HashTable)探究(转)
- C#使用foreach遍历哈希表(hashtable)的方法
- STL源码剖析之slist【2013.11.26】