poj 2635(筛素数+同模余定理+缩位)
2013-11-17 10:56
330 查看
The Embarrassed Cryptographer
Description
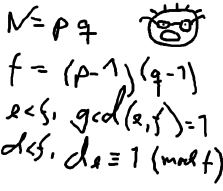
The young and very promising cryptographer Odd Even has implemented the security module of a large system with thousands of users, which is now in use in
his company. The cryptographic keys are created from the product of two primes, and are believed to be secure because there is no known method for factoring such a product effectively.
What Odd Even did not think of, was that both factors in a key should be large, not just their product. It is now possible that some of the users of the system have weak keys. In a desperate attempt not to be fired, Odd Even secretly goes through all the users
keys, to check if they are strong enough. He uses his very poweful Atari, and is especially careful when checking his boss' key.
Input
The input consists of no more than 20 test cases. Each test case is a line with the integers 4 <= K <= 10100 and 2 <= L <= 106. K is the key itself, a product of two primes. L is the
wanted minimum size of the factors in the key. The input set is terminated by a case where K = 0 and L = 0.
Output
For each number K, if one of its factors are strictly less than the required L, your program should output "BAD p", where p is the smallest factor in K. Otherwise, it should output "GOOD". Cases should be separated by
a line-break.
Sample Input
Sample Output
Source
Nordic 2005
非常好的数论题目。
用到了筛素数法+缩位法+大数除法(同模余定理)。
首先我们把0-10^6内的素数都“筛”出来,存入一个list中(程序中是prime数组)。注意10^6是100万而不是10万。已经因为这个贡献了好多次WA了。
long:
这里用到了缩位技术:如A=1234567=[ 1][234][567] ,则B
= [567][234][1 ]
假设输入的字符串是A,显然这个字符时从高位向低位排。我们的divide函数要求A从低位向高位排。因此需要做转化:
lena - i 是 这位逆着数是第几个。
(lena - i + (base-1)) / base 就是B中应该放入的bucket。
这里x + (base-1) / base 实际上就是 x / base上取整!!
最后再减1,就是bucket的index
缩位代码如下:
提交记录:
1、TLE一次,因为没有缩位。
2、TLE一次,因为没有用筛素数。
3、WA一次,因为rem用的是int溢出,应该改为long long.
4、WA一次,居然因为A[i] - '0' 写成了 A[i-'0']
不忍直视。。。。。
4、Accepted
代码:
| Time Limit: 2000MS | Memory Limit: 65536K | |
| Total Submissions: 11525 | Accepted: 3074 |
The young and very promising cryptographer Odd Even has implemented the security module of a large system with thousands of users, which is now in use in
his company. The cryptographic keys are created from the product of two primes, and are believed to be secure because there is no known method for factoring such a product effectively.
What Odd Even did not think of, was that both factors in a key should be large, not just their product. It is now possible that some of the users of the system have weak keys. In a desperate attempt not to be fired, Odd Even secretly goes through all the users
keys, to check if they are strong enough. He uses his very poweful Atari, and is especially careful when checking his boss' key.
Input
The input consists of no more than 20 test cases. Each test case is a line with the integers 4 <= K <= 10100 and 2 <= L <= 106. K is the key itself, a product of two primes. L is the
wanted minimum size of the factors in the key. The input set is terminated by a case where K = 0 and L = 0.
Output
For each number K, if one of its factors are strictly less than the required L, your program should output "BAD p", where p is the smallest factor in K. Otherwise, it should output "GOOD". Cases should be separated by
a line-break.
Sample Input
143 10 143 20 667 20 667 30 2573 30 2573 40 0 0
Sample Output
GOOD BAD 11 GOOD BAD 23 GOOD BAD 31
Source
Nordic 2005
非常好的数论题目。
用到了筛素数法+缩位法+大数除法(同模余定理)。
首先我们把0-10^6内的素数都“筛”出来,存入一个list中(程序中是prime数组)。注意10^6是100万而不是10万。已经因为这个贡献了好多次WA了。
bool flag[MAXN] = {0};
int prime[MAXN] = {0};
int primenum = 0;
void getprime() {//筛法求素数,得到的flag是标志数组,而prime是从2开始的素数链
int i, j;
memset(flag, true, sizeof(flag));
flag[0] = flag[1] = false;
for (i = 2; i < MAXN; i++) //从0开始
if (flag[i])
{
for (j = i*2; j < MAXN; j += i)
flag[j] = false; //不再是素数了
prime[primenum++] = i;
}
}之后枚举从2-L的所有素数,判断是否能被K整除。这里可以用大数除法运算的程序,但我们并不关心最后的除法结果,只关心余数rem,因此删掉计算C的部分,大数除法运算就变成了所谓的”同模余定理“。这里需要注意计算过程中rem可能会溢出,因此最好用longlong:
long long divide(int A[], int lena, int base, int divider) {//A由低位向高位排序
int pos;
long long rem = 0;
int sizeC = 0;
//char C[200] = {0};
for (pos = lena-1; pos >= 0; pos--) { //所谓的同余模定理就是不计算C的大数除法运算!除法运算一定从高位往低位算
rem = rem * base + A[pos]; //base是进制
//C[pos] = rem / divider; //得到C的那一位
//if (C[pos] > 0 && pos > sizeC) { // 第一个不为0的位,所以sizeC = pos
// sizeC = pos;
//}
rem = rem % divider;//这里模除的是divider!!!因此rem的值是divider数量级
}
return rem;
}如果只做上面的工作,可能会TLE。这是因为位数太碎了。十进制需要压缩到百进制或者千进制,甚至是万进制。这里用到了缩位技术:如A=1234567=[ 1][234][567] ,则B
= [567][234][1 ]
假设输入的字符串是A,显然这个字符时从高位向低位排。我们的divide函数要求A从低位向高位排。因此需要做转化:
lena - i 是 这位逆着数是第几个。
(lena - i + (base-1)) / base 就是B中应该放入的bucket。
这里x + (base-1) / base 实际上就是 x / base上取整!!
最后再减1,就是bucket的index
缩位代码如下:
int lena = strlen(A);
int B[200] = {0};
int base = 7;
for (i = 0; i < lena; i++) {
int index = (lena-i+(base-1)) / base - 1;//精确计算它是属于哪个bucket的!! lena-i就是逆序位置,加上base-1再整除base相当于上取整。最后再减1得到数组下标
B[index] = B[index] * 10 + A[i]-'0';//先到的一定是高位(也就是每个bucket内是按照原来的顺序)
}
int lenb = (lena+(base-1))/base;//上取整提交记录:
1、TLE一次,因为没有缩位。
2、TLE一次,因为没有用筛素数。
3、WA一次,因为rem用的是int溢出,应该改为long long.
4、WA一次,居然因为A[i] - '0' 写成了 A[i-'0']
不忍直视。。。。。
4、Accepted
代码:

相关文章推荐
- poj 2635...再来一道...
- POJ 2635 The Embarrassed Cryptographer
- POJ 2635, The Embarrassed Cryptographer
- POJ 2635 The Embarrassed Cryptographer
- poj 2635 高精度取模
- poj 2635 The Embarrassed Cryptographer
- poj 2635 The Embarrassed Cryptographer
- poj 2635 The Embarrassed Cryptographer
- poj2635
- poj 2635 The Embarrassed Cryptographer
- POJ 2635 The Embarrassed Cryptographer
- poj 2635
- poj 2635 高精度+素数
- POJ 2635 The Embarrassed Cryptographer 线性筛+高精度取模
- POJ 2635
- POJ 2635 The Embarrassed Cryptographer 大数取模
- POJ 2635 The Embarrassed Cryptographer
- poj 2635
- poj 2635(The Embarrassed Cryptographer(把…译成密码) 素数打表的最优方法+10进制转换成1000进制,大数取模
- poj 2635 The Embarrassed Cryptographer(数论)