Linxu环境下使用Eclipse直接调试mapreduce程序(不用插件)
2013-11-15 19:08
651 查看
Linxu环境下使用Eclipse直接调试mapreduce程序(不用插件)
前面介绍了hadoop的本地安装, vnc控制hadoop服务器的开发调试, hadoop的eclipse插件安装及运行等。 本文我们重点介绍如何在eclipse集成环境下如何debug调试hadoop程序,
充分利用debug工具的调试, 断点, 变量查看等等。
那么我们可以运行这个项目吗?
我们当然可以采用运行普通java项目的办法来运行这个java项目, 但是map reduce程序没办法正常的工作。
我们如何解决这个问题?要解决这个问题如何进行?首先要解决这个问题,需要了解hadoop的基本工作过程,特别是hadoop的工作过程中的classpath相关设置问题了。
关于hadoop的classpath问题, 请参考前面的一些体会,如下地址供您研究:
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
通过上面这些研究我们可以了解hadoop启动的关键时,如何配制hadoop运行的classpath的,通过这个classpath的脚本能找到配置文件, 然后根据配置文件能联系到各个服务组件, 然后在根据组件连接各个服务器然后决定如何进行下一步的工作。
有了以上,我们就可以断定, 我们的普通的java项目可以通过适当调整classpath设置然后能够运行hadoop的map reduce程序。 在普通java项目中可以应用 方便的各种调试工具来进行应用程序的调试、开发等。
下面我们将根据这个线索来逐步构建一个java的项目, 然后添加hadoop的配置文件等到项目中, 然后调试程序。
cp -r hadoop-1.2.1 hadoop-local
进入新拷贝的hadoop目录中, 执行下面的命令,
[sch@db conf]$ pwd // 显示当前目录, 输入命令时,不要包括注释部分
/work/apps/hadoop-local/conf // 当前目录是本地hadoop的配置文件目录
[sch@db conf]$ ls // 查看当前目录下的文件情况
capacity-scheduler.xml mapred-queue-acls.xml
configuration.xsl mapred-site.xml
core-site.xml masters
fair-scheduler.xml slaves
hadoop-env.sh ssl-client.xml.example
hadoop-metrics2.properties ssl-server.xml.example
hadoop-policy.xml taskcontroller.cfg
hdfs-site.xml task-log4j.properties
log4j.properties
[sch@db conf]$ cat core-site.xml // 查看 core-site.xml的配置情况, 可以用vi编辑到这个状况
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> // 请特别注意, 配置中是完全空的,
</configuration> // 全空表示 本地默认配置, 包括采用本地文件系统
[sch@db conf]$ cat hdfs-site.xml // 下面请看同上
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
</configuration>
[sch@db conf]$ cat mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
</configuration>
截图如下:
完成上述配置后,我们就完成了本地的hadoop的配置工作
命令如下:
[sch@db hadoop-local]$ mkdir input
[sch@db hadoop-local]$ cp conf/* input/
[sch@db hadoop-local]$ ls input/
也可以采用import命令,导入eclipse中,
采用哪个方法都行,总之最后结果如下
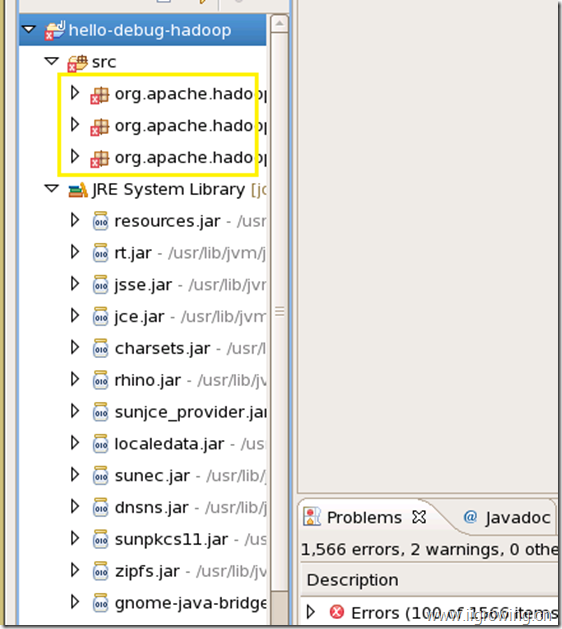
如上, 我们引进引入了全部hadoop的例子源代码, 但发现有大量的编译错误,下面解决编译错误的情况。
然后在弹出的对话框中, 选择下面系统目录, 然后选择里面的两个jar文件

然后点击ok按钮
添加hadoop的lib目录中的文件到项目中, 如下图

添加完成, 可能还有些错误, 也可能没有。情况如下:

这里面设置的java版本是1.4的版本, 我们需要将这个版本提高, 否则会有很多错误

如上, 设置java版本到达1.6, 然后选择确定按钮。
编译错误都没有了。

如上图, 我们选择了 添加外部的目录作为classpath进行了,然后还需要调整一下相关顺序,如下图:

请特别注意上图中, 不同颜色的区域, 是配置好这个情况的关键
配置完成后, 选择ok按钮, 完成相关配置

然后选择右键,设置断点, 如下图, 选择debug as 菜单, 选择debug配置

有可能程序还没有创建调试项目, 我们选择创建java的项目

在弹出的对话框中, 选择arg参数tab页面, 输入如下的调试参数, 注意这里面的文件路径是绝对路径
/work/apps/hadoop-local/input /work/apps/hadoop-local/output ‘dfs[a-z.]+’

然后点击应用, 然后点击调试按钮。

如上图,已经进入了相关项目的运行了, 进入了debug模式, 现在可以利用debug的各种功能了。
为了更进一步证明这个调试模式的作用, 在下面图中, 断点处选择 蓝色区域, 选择f3键, 寻找相关源代码

按照如下图中,号码顺序,先选择添加 源代码按钮, 在弹出对话框中,选择2中按钮, 然后在对话框中选择相应文件目录中相关代码

然后在编辑器中设置如下图中的断点, 然后运行程序, 最后停止到相关断点上, 然后查看图中不同区域的查看相关调试信息:

本文转载自:http://www.iigrowing.cn/diao-shi-eclipse-xia-hadoop-de-map-reduce-cheng-xu.html
前面介绍了hadoop的本地安装, vnc控制hadoop服务器的开发调试, hadoop的eclipse插件安装及运行等。 本文我们重点介绍如何在eclipse集成环境下如何debug调试hadoop程序,
充分利用debug工具的调试, 断点, 变量查看等等。
一.调试hadoop要解决的问题:
在上一篇文章中, 我们已经可以采用插件的方法, 来运行hadoop项目, 但是我们没办法用debug方式来运行您的hadoop项目。那么我们可以运行这个项目吗?
我们当然可以采用运行普通java项目的办法来运行这个java项目, 但是map reduce程序没办法正常的工作。
我们如何解决这个问题?要解决这个问题如何进行?首先要解决这个问题,需要了解hadoop的基本工作过程,特别是hadoop的工作过程中的classpath相关设置问题了。
关于hadoop的classpath问题, 请参考前面的一些体会,如下地址供您研究:
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
通过上面这些研究我们可以了解hadoop启动的关键时,如何配制hadoop运行的classpath的,通过这个classpath的脚本能找到配置文件, 然后根据配置文件能联系到各个服务组件, 然后在根据组件连接各个服务器然后决定如何进行下一步的工作。
有了以上,我们就可以断定, 我们的普通的java项目可以通过适当调整classpath设置然后能够运行hadoop的map reduce程序。 在普通java项目中可以应用 方便的各种调试工具来进行应用程序的调试、开发等。
下面我们将根据这个线索来逐步构建一个java的项目, 然后添加hadoop的配置文件等到项目中, 然后调试程序。
二.配置并测试一个hadoop的本地系统
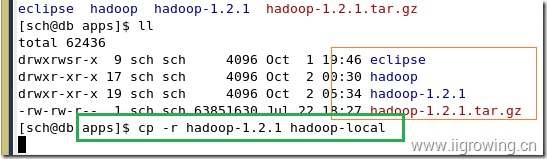
如下图, 在hadoop安装目录的上级目录,拷贝一个hadoop的本地系统,如下图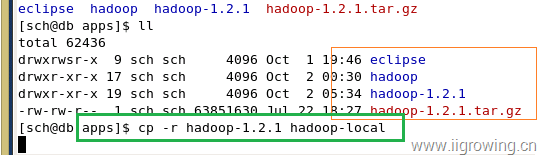
cp -r hadoop-1.2.1 hadoop-local
进入新拷贝的hadoop目录中, 执行下面的命令,
[sch@db conf]$ pwd // 显示当前目录, 输入命令时,不要包括注释部分
/work/apps/hadoop-local/conf // 当前目录是本地hadoop的配置文件目录
[sch@db conf]$ ls // 查看当前目录下的文件情况
capacity-scheduler.xml mapred-queue-acls.xml
configuration.xsl mapred-site.xml
core-site.xml masters
fair-scheduler.xml slaves
hadoop-env.sh ssl-client.xml.example
hadoop-metrics2.properties ssl-server.xml.example
hadoop-policy.xml taskcontroller.cfg
hdfs-site.xml task-log4j.properties
log4j.properties
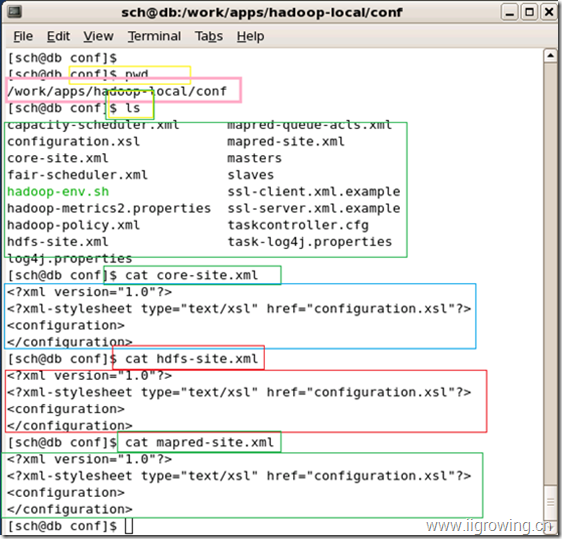
[sch@db conf]$ cat core-site.xml // 查看 core-site.xml的配置情况, 可以用vi编辑到这个状况
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration> // 请特别注意, 配置中是完全空的,
</configuration> // 全空表示 本地默认配置, 包括采用本地文件系统
[sch@db conf]$ cat hdfs-site.xml // 下面请看同上
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
</configuration>
[sch@db conf]$ cat mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
</configuration>
截图如下:
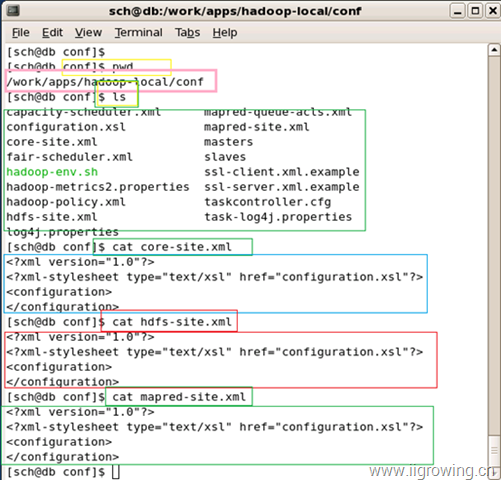
完成上述配置后,我们就完成了本地的hadoop的配置工作
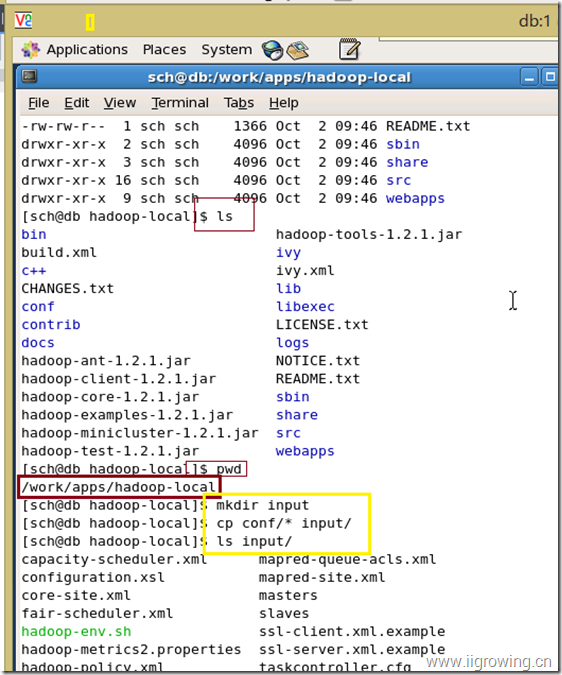
三.准备测试hadoop项目的测试数据
如下图, 我们在刚刚安装好的 hadoop目录中,创建input目录, 并且把conf目录下的相关文件拷贝过去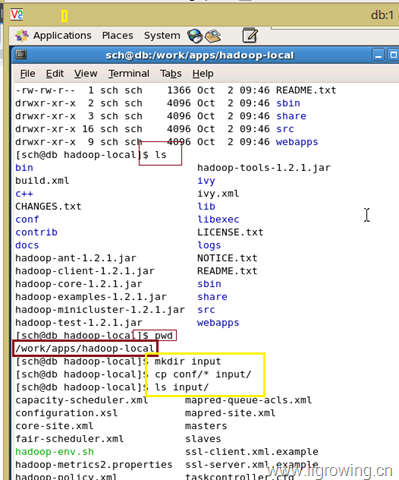
命令如下:
[sch@db hadoop-local]$ mkdir input
[sch@db hadoop-local]$ cp conf/* input/
[sch@db hadoop-local]$ ls input/
四.在eclipse中创建一个普通的java项目
1. Java项目的创建
Eclispe中如何创建一个普通的java项目就省略, 读者应该都会了, 项目创建完成如下结构。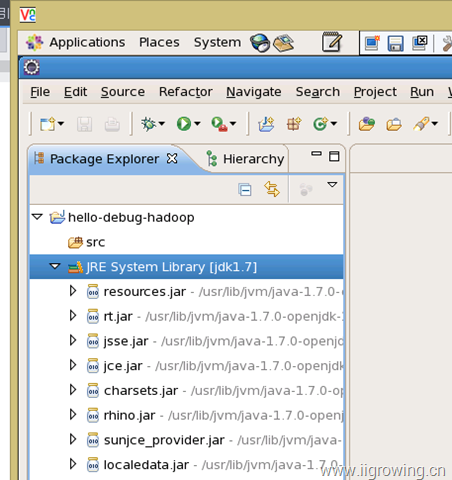
2. Hadoop源代码的引入
Hadoop源代码的引入可以采用拷贝源代码到src中也可以采用import命令,导入eclipse中,
采用哪个方法都行,总之最后结果如下
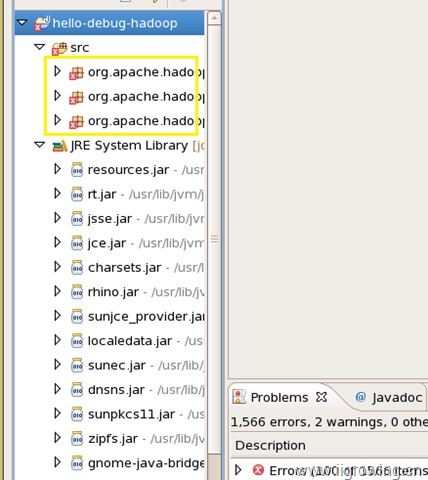
如上, 我们引进引入了全部hadoop的例子源代码, 但发现有大量的编译错误,下面解决编译错误的情况。
3. 导入hadoop的包,解决java项目的编译错误问题
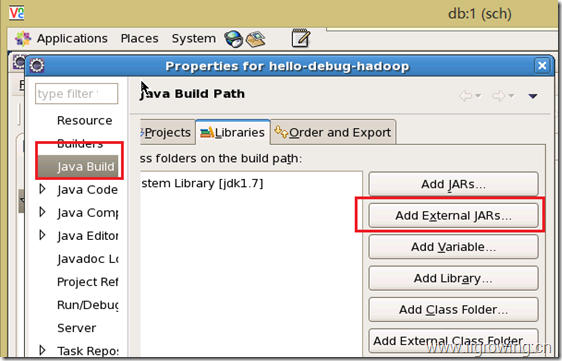
在java的编译属性上, 选择lib相关标签, 然后选择添加外部jar文件的按钮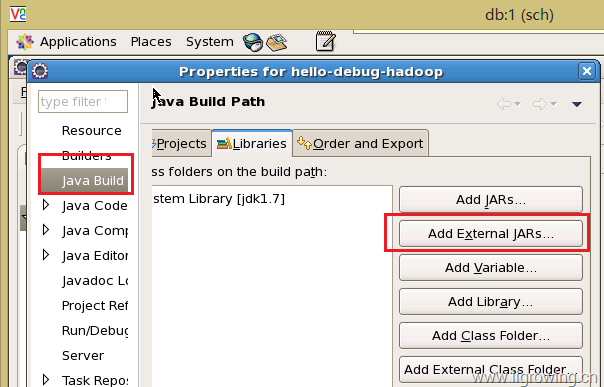
然后在弹出的对话框中, 选择下面系统目录, 然后选择里面的两个jar文件
然后点击ok按钮
添加hadoop的lib目录中的文件到项目中, 如下图
添加完成, 可能还有些错误, 也可能没有。情况如下:
这里面设置的java版本是1.4的版本, 我们需要将这个版本提高, 否则会有很多错误
如上, 设置java版本到达1.6, 然后选择确定按钮。
编译错误都没有了。
五.添加hadoop的配置到eclipse的java项目中
前面已经叙述了, 这个hadoop的配置文件目录作为classpath添加到java项目的重要性, 下面我们来操作,然后可以进行项目调试了。如上图, 我们选择了 添加外部的目录作为classpath进行了,然后还需要调整一下相关顺序,如下图:
请特别注意上图中, 不同颜色的区域, 是配置好这个情况的关键
配置完成后, 选择ok按钮, 完成相关配置
六.Debug 创建hadoop项目
如下图, 从源代码文件中选择下图中的类, 然后在主函数中设置断点然后选择右键,设置断点, 如下图, 选择debug as 菜单, 选择debug配置
有可能程序还没有创建调试项目, 我们选择创建java的项目
在弹出的对话框中, 选择arg参数tab页面, 输入如下的调试参数, 注意这里面的文件路径是绝对路径
/work/apps/hadoop-local/input /work/apps/hadoop-local/output ‘dfs[a-z.]+’
然后点击应用, 然后点击调试按钮。
如上图,已经进入了相关项目的运行了, 进入了debug模式, 现在可以利用debug的各种功能了。
为了更进一步证明这个调试模式的作用, 在下面图中, 断点处选择 蓝色区域, 选择f3键, 寻找相关源代码
按照如下图中,号码顺序,先选择添加 源代码按钮, 在弹出对话框中,选择2中按钮, 然后在对话框中选择相应文件目录中相关代码
然后在编辑器中设置如下图中的断点, 然后运行程序, 最后停止到相关断点上, 然后查看图中不同区域的查看相关调试信息:
本文转载自:http://www.iigrowing.cn/diao-shi-eclipse-xia-hadoop-de-map-reduce-cheng-xu.html

相关文章推荐
- Eclipse下使用Hadoop单机模式调试MapReduce程序
- 如何在本地Windows环境中用Eclipse中调试MapReduce程序
- Eclipse下使用Hadoop单机模式调试MapReduce程序
- Eclipse下使用Hadoop单机模式调试MapReduce程序
- 搭建Android开发环境:直接使用官网提供的 ADT Bundle(带Eclipse、ADT插件、SDK)
- window7使用eclipse环境本地运行MapReduce程序方法
- eclipse直接使用tomcat安装程序的webapp目录调试
- Windows下使用eclipse插件运行自己的MapReduce程序
- 搭建java web开发环境、使用eclipse编写第一个java web程序
- 使用 Eclipse 调试 Java 程序的 10 个技巧(转载)
- 怎样在Eclipse中使用debug调试程序
- linux环境中的arm程序编辑器eclipse安装及使用方法
- 使用Eclipse调试PHP程序
- 关于使用gdbserver和eclipse共同调试一个嵌入式程序的方法大纲
- 怎样在Eclipse中使用debug调试程序?(转)
- 使用Eclipse调试Java 程序的10个技巧
- Linux环境下使用eclipse开发C++动态链接库程序
- python环境安装和在eclipse中插件的使用
- 使用JDB指令模拟Eclipse调试java程序.
- 怎样在Eclipse中使用debug调试程序?