Hadoop MapReduce之MapTask任务执行(二)
2013-11-14 18:16
337 查看
(为了简单起见,我们这里分析官方文档中使用的WordCount程序)
上一篇我们已经看到自己的map函数是如何被调用的,这是一个循环调用的过程,这里我们分析下,从KV读入到KV写出的过程,通常我们只要写map函数就可以了,但在一些特殊的情况下我们也可以覆盖run函数,来实现自己的执行流程。
这个例子中我们使用默认的InputFormat,在初始化的时候被初始化为TextInputFormat,循环读取KV的时候用的RecordReader是LineRecordReader,这也是由TextInputFormat决定的。
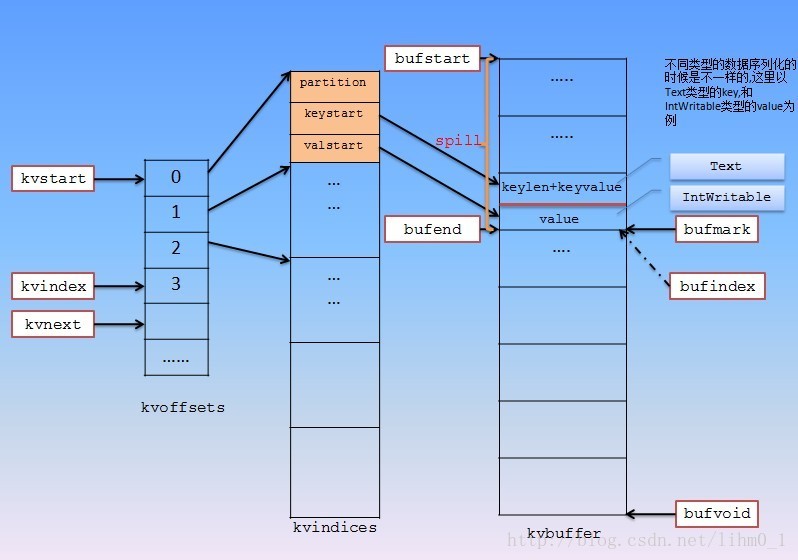
map函数操作完后会写入buffer中,这是由MapTask的内部类MapOutputBuffer来维护的来维护的,与该buffer相关的还有其他一些内部类,如Buffer,BlockingBuffer都会协同MapOutputBuffer来操作这个缓冲区,缓冲区的大小由io.sort.mb参数决定,单位是M,可以通过io.sort.spill.percent和io.sort.record.percent来控制该buffer的刷新频率,刷新时会将buffer中的部分内容写入spill文件,一旦写入完成,空出来的空间就可以重写了,缓存这部分的刷新机制稍显复杂,因为有太多的控制变量,内存结构的概览图如下:
下面我们开始从Mapper.run函数执行进入,分析KV读取,map处理、写入缓存的过程。
上一篇我们已经看到自己的map函数是如何被调用的,这是一个循环调用的过程,这里我们分析下,从KV读入到KV写出的过程,通常我们只要写map函数就可以了,但在一些特殊的情况下我们也可以覆盖run函数,来实现自己的执行流程。
这个例子中我们使用默认的InputFormat,在初始化的时候被初始化为TextInputFormat,循环读取KV的时候用的RecordReader是LineRecordReader,这也是由TextInputFormat决定的。
map函数操作完后会写入buffer中,这是由MapTask的内部类MapOutputBuffer来维护的来维护的,与该buffer相关的还有其他一些内部类,如Buffer,BlockingBuffer都会协同MapOutputBuffer来操作这个缓冲区,缓冲区的大小由io.sort.mb参数决定,单位是M,可以通过io.sort.spill.percent和io.sort.record.percent来控制该buffer的刷新频率,刷新时会将buffer中的部分内容写入spill文件,一旦写入完成,空出来的空间就可以重写了,缓存这部分的刷新机制稍显复杂,因为有太多的控制变量,内存结构的概览图如下:
下面我们开始从Mapper.run函数执行进入,分析KV读取,map处理、写入缓存的过程。
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
//注意这里使用的Context是org.apache.hadoop.mapreduce.Mapper.Context类型,他是Mapper的一个内部类
setup(context);//先执行setup函数,我们可以在这里设置一些全局变量
while (context.nextKeyValue()) {//通过context循环读取下一个KV值
//这里调用我们自己的map函数来处理,并使用context进行输入,使用新的API
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);//最后调用cleanup函数进行清理操作
}下面分析下读取KV的过程,实际调用了org.apache.hadoop.mapred.MapTask.NewTrackingRecordReader.nextKeyValue(),NewTrackingRecordReader类的初始化在上一篇我们已经看到过了,其中会初始化自己的RecordReader,在读取KV值的时候最终还是会调用读取器的函数来读数据。下面我们看下读取过程:public boolean nextKeyValue() throws IOException, InterruptedException {
boolean result = false;
try {
long bytesInPrev = getInputBytes(fsStats);
result = real.nextKeyValue();//读取一组KV,具体流程看下面源码
long bytesInCurr = getInputBytes(fsStats);
//计数器更新
if (result) {
inputRecordCounter.increment(1);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}
reporter.setProgress(getProgress());//更新进度
} catch (IOException ioe) {
if (inputSplit instanceof FileSplit) {
FileSplit fileSplit = (FileSplit) inputSplit;
LOG.error("IO error in map input file "
+ fileSplit.getPath().toString());
throw new IOException("IO error in map input file "
+ fileSplit.getPath().toString(), ioe);
}
throw ioe;
}
return result;
} 在具体实践中我们可能用到各种各样的InputFormat,里面会包装不同的读取器,所里这里分析LineRecordReader已经不具有代表性了,因为我们完全可以自定义读取器,所以对于读取动作这里就不过分深入分析了,只看下读取KV的过程:public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);//设置KEY的值,也就是偏移量
if (value == null) {
value = new Text();
}
int newSize = 0;
while (pos < end) {
//设置value的值,并返回读取长度,用于判断是否超出最大行长度
newSize = in.readLine(value, maxLineLength,
Math.max((int)Math.min(Integer.MAX_VALUE, end-pos),
maxLineLength));
if (newSize == 0) {
break;
}
pos += newSize;//偏移量更新
if (newSize < maxLineLength) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
//读取长度为0,则说明什么都没读到,返回空
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
} 上面分析的是读取的动作,我们再取出并使用的操作,在上面取值操作完成后,KV值已经存放在RecordReader的成员变量中了,在使用的时候可以直接取出并传递给我们的map函数://取key的操作
public KEYIN getCurrentKey() throws IOException, InterruptedException {
return reader.getCurrentKey();
}
//取value的操作
public VALUEIN getCurrentValue() throws IOException, InterruptedException {
return reader.getCurrentValue();
}
//map调用操作
map(context.getCurrentKey(), context.getCurrentValue(), context); 下面看我们自定义的map函数,主要关心map的输出:protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
word.set(st.nextToken());
context.write(word, one);//这里会执行输出操作
}
};
输出时会调用TaskInputOutputContext的write函数,因为传入的Mapper.Context是其子类
public void write(KEYOUT key, VALUEOUT value
) throws IOException, InterruptedException {
output.write(key, value);
}而后会调用MapTask的write函数public void write(K key, V value) throws IOException, InterruptedException {
//这里出现了partitoner,因此在KV向缓冲区写入的时候其分区信息就已经确定了
//默认使用的Partitioner是HashPartitioner,他会把KV尽量均匀的分布在各个Reduce
//需要注意的是分区的返回值是个整数
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}先看下默认的分区算法:public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
//使用hash后取模的算法,算是比较均匀了
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}下面继续分析collect函数,这里包含了写入缓存的操作public synchronized void collect(K key, V value, int partition
) throws IOException {
reporter.progress();//回报进度
//判断KV类型
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", recieved "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", recieved "
+ value.getClass().getName());
}
//获得record index的下一个位置,注意这里是循环使用的,
//kvindex正常情况都会超出kvoffsets,因此这里使用取模的小算法
final int kvnext = (kvindex + 1) % kvoffsets.length;
spillLock.lock();
try {
boolean kvfull;
do {
//判断是否溢写异常
if (sortSpillException != null) {
throw (IOException)new IOException("Spill failed"
).initCause(sortSpillException);
}
// 判断kvoffsets是否已经写满,如果两值相等,则说明该缓冲区已经完全用完,需要刷新
kvfull = kvnext == kvstart;
//判断是否超出软限制
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);
if (kvstart == kvend && kvsoftlimit) {
LOG.info("Spilling map output: record full = " + kvsoftlimit);
startSpill();//如果缓冲区达到软限制则执行spill
}
if (kvfull) {
try {
while (kvstart != kvend) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException(
"Collector interrupted while waiting for the writer"
).initCause(e);
}
}
} while (kvfull);//等待缓冲区刷新完毕
} finally {
spillLock.unlock();
}
//序列化KV数据
try {
// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; reset required
bb.reset();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
int valend = bb.markRecord();
//判断分区数是否异常
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
//计数器更新
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(valend >= keystart
? valend - keystart
: (bufvoid - keystart) + valend);
//数据写入成功则更新元数据信息,注意需要同时更新kvoffsets和kvindices,从这也可以看出元数据的记录结构
int ind = kvindex * ACCTSIZE;
kvoffsets[kvindex] = ind;
kvindices[ind + PARTITION] = partition;
kvindices[ind + KEYSTART] = keystart;
kvindices[ind + VALSTART] = valstart;
kvindex = kvnext;
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}下面是缓冲区的初始化操作:public MapOutputBuffer(TaskUmbilicalProtocol umbilical, JobConf job,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
this.job = job;
this.reporter = reporter;
localFs = FileSystem.getLocal(job);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)localFs).getRaw();
indexCacheList = new ArrayList<SpillRecord>();
//缓冲区开始spill操作的百分比
final float spillper = job.getFloat("io.sort.spill.percent",(float)0.8);
//保存非KV记录的的百分比
final float recper = job.getFloat("io.sort.record.percent",(float)0.05);
//缓冲区大小,默认100M
final int sortmb = job.getInt("io.sort.mb", 100);
//判断spill开始操作的百分比是否合理
if (spillper > (float)1.0 || spillper < (float)0.0) {
throw new IOException("Invalid \"io.sort.spill.percent\": " + spillper);
}
//判断非KV记录空间百分比是否合理
if (recper > (float)1.0 || recper < (float)0.01) {
throw new IOException("Invalid \"io.sort.record.percent\": " + recper);
}
//缓冲区分配是否合理
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException("Invalid \"io.sort.mb\": " + sortmb);
}
//构建排序器,默认为QuickSort
sorter = ReflectionUtils.newInstance(
job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job);
LOG.info("io.sort.mb = " + sortmb);
// 缓冲区分配转换为字节
int maxMemUsage = sortmb << 20;
int recordCapacity = (int)(maxMemUsage * recper);
recordCapacity -= recordCapacity % RECSIZE;
//开始分配缓冲区,注意这里分配的是KV数据的缓冲区
kvbuffer = new byte[maxMemUsage - recordCapacity];
//起始定位在KVbuffer的尾部
bufvoid = kvbuffer.length;
//计算记录数量并分配相应缓冲区
recordCapacity /= RECSIZE;
kvoffsets = new int[recordCapacity];
//分配record indes缓存
kvindices = new int[recordCapacity * ACCTSIZE];
//计算软限制
softBufferLimit = (int)(kvbuffer.length * spillper);
softRecordLimit = (int)(kvoffsets.length * spillper);
//日志输出格式 spill阈值/bufferLength
LOG.info("data buffer = " + softBufferLimit + "/" + kvbuffer.length);
LOG.info("record buffer = " + softRecordLimit + "/" + kvoffsets.length);
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
//获得序列化工厂,并打开输出流
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// counters
mapOutputByteCounter = reporter.getCounter(MAP_OUTPUT_BYTES);
mapOutputRecordCounter = reporter.getCounter(MAP_OUTPUT_RECORDS);
Counters.Counter combineInputCounter =
reporter.getCounter(COMBINE_INPUT_RECORDS);
combineOutputCounter = reporter.getCounter(COMBINE_OUTPUT_RECORDS);
fileOutputByteCounter = reporter.getCounter(MAP_OUTPUT_MATERIALIZED_BYTES);
// 获得压缩类
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
}
// 获得本地合并类
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, conf);
} else {
combineCollector = null;
}
//最小spill文件合并数量
minSpillsForCombine = job.getInt("min.num.spills.for.combine", 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
//启动spill线程
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException("Spill thread failed to initialize"
).initCause(sortSpillException);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw (IOException)new IOException("Spill thread failed to initialize"
).initCause(sortSpillException);
}
}

相关文章推荐
- Hadoop MapReduce之MapTask任务执行(一)
- Hadoop MapReduce之MapTask任务执行(四)
- Hadoop MapReduce之MapTask任务执行(三)
- 记Hadoop2.5.0线上mapreduce任务执行map任务划分的一次问题解决
- Hadoop MapReduce之ReduceTask任务执行(一)
- Hadoop MapReduce之ReduceTask任务执行(二)
- Hadoop MapReduce之ReduceTask任务执行(三)
- hadoop 里执行 MapReduce 任务的几种常见方式
- hadoop的mapreduce任务的执行流程
- Hadoop MapReduce 任务执行流程源代码详细解析
- 精通HADOOP(九) - MAPREDUCE任务的基础知识 - 执行作业
- Hadoop MapReduce 任务执行流程源代码详细解析
- Hadoop MapReduce之ReduceTask任务执行(一):远程拷贝map输出
- 浅析Hadoop中MapReduce任务执行流程
- 一个MapReuce作业的从开始到结束--第6章Hadoop以Jar包的方式执行MapReduce任务
- Hadoop MapReduce 任务执行流程源代码详细解析(转载)
- hadoop 8088 看不到mapreduce 任务的执行状态
- 【Hadoop】MapReduce笔记(一):MapReduce作业运行过程、任务执行
- Hadoop MapReduce之ReduceTask任务执行(五)
- hadoop执行mapreduce任务,能够map,不能reduce,Shuffle阶段报错