链表:顺序链表和单链表
2013-10-27 20:09
211 查看
在介绍链表之前,我们首先来了解一下线性表。线性表是最基本、最简单、也是最常用的一种数据结构。线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。线性表的逻辑结构简单,便于实现和操作。因此,线性表这种数据结构在实际应用中是广泛采用的一种数据结构。
链表是一种最常见的线性表,栈、队列是两种特殊的线性表。
下面,我们开始学习“顺序存储的线性表”和“链式存储的线性表”。
(1)顺序存储线性表
1、采用数组来存储顺序线性表的各元素。
2、基本结构:
3、数组的长度(最大线性表长度)大小不能够改变,但是线性表的长度(元素的个数)可以改变。
4、通过下标索引可以直接获取顺序线性表中的各个元素。
5、插入:判断下标是否越界、判断是否在最后插入,元素后移、插入元素;
删除:取出删除的元素(参数是指针形式)、判断是否在最后删除,元素前移。
6、插入、删除时需要移动大量的元素;当线性表长度过长时,难以确定存储空间的容量(数组大小)。
(2)链式存储线性表
1、结点:数据域+指针域
链表:n个结点链接成一个链表(a1->a2->a3->……->an)。
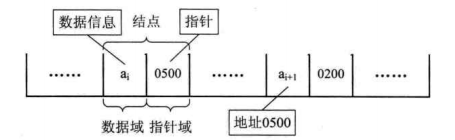
2、头指针:链表中第一个结点的存储位置(特别注意:不是第一个节点中的指针,而是指向第一个结点的一个指针)。有时候,为了方便对链表进行操作,我们也会在第一个结点前附加一个结点,作为“头结点”,但头结点的数据不能够存储任何数据。头指针具有标识的作用,通常会将其视为链表的名字。
尾指针:最后一个结点的指针域,此指针为空(NULL)。
关于“头指针”和“头结点”,可以参考资料:http://blog.csdn.net/passball/article/details/6125767,这里讲的很透彻。
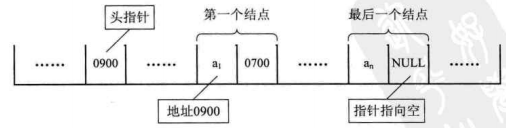
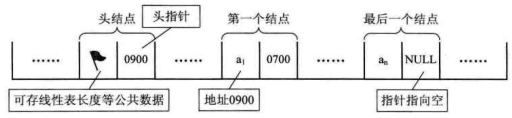
3、单链表存储结构:
另外,很多参考数据上,还有许多其他的形式;但数据结构是一样的,只是写法不一样,如:
4、单链表的基本操作
1)读取单链表中的元素
2)单链表的插入
3)单链表结点的删除
4)单链表的创建
5)显示链表(遍历链表)
链表是一种最常见的线性表,栈、队列是两种特殊的线性表。
下面,我们开始学习“顺序存储的线性表”和“链式存储的线性表”。
(1)顺序存储线性表
1、采用数组来存储顺序线性表的各元素。
2、基本结构:
#define MAXSIZE 20
typedef int Elemtype;
typedef struct
{
Elemtype data[MAXSIZE]; //采用数组存储线性表
int length; //线性表的长度,即线性表元素的个数
}sqList;3、数组的长度(最大线性表长度)大小不能够改变,但是线性表的长度(元素的个数)可以改变。
4、通过下标索引可以直接获取顺序线性表中的各个元素。
5、插入:判断下标是否越界、判断是否在最后插入,元素后移、插入元素;
删除:取出删除的元素(参数是指针形式)、判断是否在最后删除,元素前移。
6、插入、删除时需要移动大量的元素;当线性表长度过长时,难以确定存储空间的容量(数组大小)。
(2)链式存储线性表
1、结点:数据域+指针域
链表:n个结点链接成一个链表(a1->a2->a3->……->an)。
2、头指针:链表中第一个结点的存储位置(特别注意:不是第一个节点中的指针,而是指向第一个结点的一个指针)。有时候,为了方便对链表进行操作,我们也会在第一个结点前附加一个结点,作为“头结点”,但头结点的数据不能够存储任何数据。头指针具有标识的作用,通常会将其视为链表的名字。
尾指针:最后一个结点的指针域,此指针为空(NULL)。
关于“头指针”和“头结点”,可以参考资料:http://blog.csdn.net/passball/article/details/6125767,这里讲的很透彻。
3、单链表存储结构:
typedef int Elemtype;
typedef struct ListNode
{
Elemtype data;
struct ListNode *next;
};
typedef struct ListNode *LinkList; //基础理解:这里已经将LinkList定义成了一个指针类型了,因此,如果定义一个链表指针时,就不能再加“*”了,直接用:LinkList p, q;而不是像其他参考资料:LinkList *p,*q;另外,很多参考数据上,还有许多其他的形式;但数据结构是一样的,只是写法不一样,如:
struct ListNode
{
int data;
struct ListNode * next;
}Node, *ListNode; //在使用的过程中,要区分使用Node(非指针)和LinkList(指针)4、单链表的基本操作
1)读取单链表中的元素
//取出单链表L(头指针)中第i个结点中的数据,并存储在e中
bool GetElem(LinkList L, int i, Elemtype *e)
{
int n=1;
LinkList p;
p = L->next;//p指向第一个结点(第一个元素所在的结点),不是头结点
while(p && n < i)
{
p = p->next;
n++;
}
if(!p || n > i)
return 0;
*e = p->data;//是*e,而不是e;参数中,采用的是指针形式,这样就能达到存储的效果
return 1;
}2)单链表的插入
//在单链表L中第i个位置之前插入新的数据元素e
bool ListInsert(LinkList *L, int i, Elemtype e)//形参,采用了指针传参(LinkList本身就是指针,再加上*L后,起到了指针传参的作用),但是函数体中使用时,一定要记得(*L)一起使用,而不是像一些资料中的直接用L;当然这里可以改用引用传参,写成LinkList &L即可,这样的话,函数体中使用时就不用再加*了,调用这个函数时,也直接用L(头指针)就行了
{
int n;
LinkList p, s;//s用来存储数据元素e,此时s不是结点,而是指针
p = (*L) -> next;
while(p && n < i)
{
p = p->next;
n++;
}
if(!p || n>i)
return 0;
s =(LinkList)malloc(sizeof(Node));//易错:计算的是Node结点的长度,而不是LinkList(指针)的长度
s->data = e;
s->next = p->next;
p->next = s;
return 1;
}3)单链表结点的删除
//删除单链表L中第i个数据元素,并用e返回其值
bool ListDelete(LinkList *L, int i, Elemtype *e)
{
int n = 1;
LinkList p, q;
p = (*L)->next;
while(p && n<i)
{
p = p->next;
n++;
}
if(!p || n>i)
return 0;
q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return 1;
}4)单链表的创建
/*使用*L的原因:指针传参-为了让创建后的链表任然能够传递到主函数中,否则会有错误*/
void CreatList(LinkList *L, int i)
{
LinkList p;
int n=1;
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL;
while(n++ <= i)
{
p = (LinkList)malloc(sizeof(Node));
p->data = rand()%100;
p->next = (*L)->next;
(*L)->next = p;
}
}5)显示链表(遍历链表)
void ShowList(LinkList L)
{
LinkList p;
p = L->next;
while(p)
{
printf("%d ",p->data);
p = p->next;
}
}

相关文章推荐
- 顺序表链表经典面试题之逆序打印单链表
- 顺序表、单链表、循环单链表、循环双链表、有序单链表的排序的实现
- 单链表与双向链表
- 【链表】得到单链表中倒数第k个结点
- 数据结构实验之链表一:顺序建立链表
- 【链表】反转单链表
- 【练习题】编写打印出一个单链表的所有元素的程序【链表】
- 单链表的逆置,排序,合并有序链表,不带环相交
- 顺序二叉树链表实现<模版>
- 顺序表与链表的比较
- [I0A]链表-单链表
- 顺序表与链表的面试题【菜鸟学习日记】
- 链表的C语言实现之单链表的实现
- 顺序链表插入
- 数据结构【线性表(二)链表】项目之自建算法库—单链表
- 删除不带头结点的单链表的非尾结点&&逆序打印单链表
- 查找单链表的倒数第k个节点,要求只能遍历一次链表
- 设一个没有头结点指针的单链表。一个指针指向此单链表中间的一个结点(不是第一个,也不是最后一个结点),将该结点从单链表中删除,要求时间复杂度O(1)。
- 【单链表面试题】--------链表的逆置
- 链表结构之单链表