hadoop配置 - secondarynamenode配置与恢复
2013-10-08 17:46
441 查看
一、配置:
secondary namenoded 配置很容易被忽视,如果jps检查都正常,大家通常不会太关心,除非namenode发生问题的时候,才会想起还有个secondary namenode,它的配置共两步:
集群配置文件conf/master中添加secondarynamenode的机器
修改/添加 hdfs-site.xml中如下属性:
这两项配置OK后,启动集群。进入secondary namenode 机器,检查fs.checkpoint.dir(core-site.xml文件,默认为${hadoop.tmp.dir}/dfs/namesecondary)目录同步状态是否和namenode一致的。
如果不配置第二项则,secondary namenode同步文件夹永远为空,这时查看secondary namenode的log显示错误为:
可能用到的core-site.xml文件相关属性:
二、配置检查:
配置完成之后,我们需要检查一下是否成功。我们可以通过查看运行secondarynamenode的机器上文件目录来确定是否成功配置。首先输入jps查看是否存在secondarynamenode进程。如果存在,在查看对应的目录下是否有备份记录。如下图:
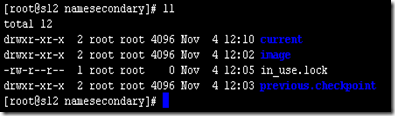
该目录一般存在于hadoop.tmp.dir/dfs/namesecondary/下面。
三、恢复:
1、配置完成了,如何恢复。首先我们kill掉namenode进程,然后将hadoop.tmp.dir目录下的数据删除掉。制造master挂掉情况。
2、在配置参数dfs.name.dir指定的位置建立一个空文件夹; 把检查点目录的位置赋值给配置参数fs.checkpoint.dir; 启动NameNode,并加上-importCheckpoint。(这句话抄袭的是hadoop-0.20.2/hadoop-0.20.2/docs/cn/hdfs_user_guide.html#Secondary+NameNode,看看文档,有说明)
3、启动namenode的时候采用hadoop namenode –importCheckpoint
4、如果namenode的IP配置有修改,手动重启各datanode节点
四、总结:
1、secondarynamenode可以配置多个,master文件里面多写几个就可以。
2、千万记得如果要恢复数据是需要手动拷贝到namenode机器上的。不是自动的(参看上面写的恢复操作)。
3、镜像备份的周期时间是可以修改的,如果不想一个小时备份一次,可以改的时间短点。core-site.xml中的fs.checkpoint.period值。
secondary namenoded 配置很容易被忽视,如果jps检查都正常,大家通常不会太关心,除非namenode发生问题的时候,才会想起还有个secondary namenode,它的配置共两步:
集群配置文件conf/master中添加secondarynamenode的机器
修改/添加 hdfs-site.xml中如下属性:
<property> <name>dfs.http.address</name> <value>192.168.1.11:50070</value> <description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.secondary.http.address</name> <value>192.168.1.12:50090</value> <description> The secondary namenode http server address and port. If the port is 0 then the server will start on a free port. </description> </property>
这两项配置OK后,启动集群。进入secondary namenode 机器,检查fs.checkpoint.dir(core-site.xml文件,默认为${hadoop.tmp.dir}/dfs/namesecondary)目录同步状态是否和namenode一致的。
如果不配置第二项则,secondary namenode同步文件夹永远为空,这时查看secondary namenode的log显示错误为:
2013-10-07 00:01:58,490 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Opening connection to http://0.0.0.0:50070/getimage?getimage=1 2013-10-07 00:01:58,492 ERROR org.apache.hadoop.security.UserGroupInformation: PriviledgedActionException as:root cause:java.net.ConnectException: Connection refused 2013-10-07 00:01:58,492 ERROR org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Exception in doCheckpoint: 2013-10-07 00:01:58,493 ERROR org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: java.net.ConnectException: Connection refused at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:198) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:391) at java.net.Socket.connect(Socket.java:579) at java.net.Socket.connect(Socket.java:528) at sun.net.NetworkClient.doConnect(NetworkClient.java:180) at sun.net.www.http.HttpClient.openServer(HttpClient.java:378) at sun.net.www.http.HttpClient.openServer(HttpClient.java:473) at sun.net.www.http.HttpClient.<init>(HttpClient.java:203) at sun.net.www.http.HttpClient.New(HttpClient.java:290) at sun.net.www.http.HttpClient.New(HttpClient.java:306) at sun.net.www.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.java:995) at sun.net.www.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:931) at sun.net.www.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:849) at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1299) at org.apache.hadoop.hdfs.server.namenode.TransferFsImage.getFileClient(TransferFsImage.java:172) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode$4.run(SecondaryNameNode.java:404) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode$4.run(SecondaryNameNode.java:393) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.downloadCheckpointFiles(SecondaryNameNode.java:393) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.doCheckpoint(SecondaryNameNode.java:494) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.doWork(SecondaryNameNode.java:369) at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.run(SecondaryNameNode.java:332) at java.lang.Thread.run(Thread.java:722)
可能用到的core-site.xml文件相关属性:
<property>
<name>fs.checkpoint.dir</name>
<value>${hadoop.tmp.dir}/dfs/namesecondary</value>
<description>Determines where on the local filesystem the DFS secondary
name node should store the temporary images to merge.
If this is a comma-delimited list of directories then the image is
replicated in all of the directories for redundancy.
</description>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>二、配置检查:
配置完成之后,我们需要检查一下是否成功。我们可以通过查看运行secondarynamenode的机器上文件目录来确定是否成功配置。首先输入jps查看是否存在secondarynamenode进程。如果存在,在查看对应的目录下是否有备份记录。如下图:
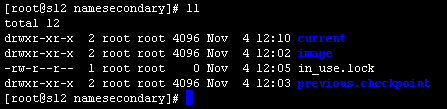
该目录一般存在于hadoop.tmp.dir/dfs/namesecondary/下面。
三、恢复:
1、配置完成了,如何恢复。首先我们kill掉namenode进程,然后将hadoop.tmp.dir目录下的数据删除掉。制造master挂掉情况。
2、在配置参数dfs.name.dir指定的位置建立一个空文件夹; 把检查点目录的位置赋值给配置参数fs.checkpoint.dir; 启动NameNode,并加上-importCheckpoint。(这句话抄袭的是hadoop-0.20.2/hadoop-0.20.2/docs/cn/hdfs_user_guide.html#Secondary+NameNode,看看文档,有说明)
3、启动namenode的时候采用hadoop namenode –importCheckpoint
4、如果namenode的IP配置有修改,手动重启各datanode节点
四、总结:
1、secondarynamenode可以配置多个,master文件里面多写几个就可以。
2、千万记得如果要恢复数据是需要手动拷贝到namenode机器上的。不是自动的(参看上面写的恢复操作)。
3、镜像备份的周期时间是可以修改的,如果不想一个小时备份一次,可以改的时间短点。core-site.xml中的fs.checkpoint.period值。

相关文章推荐
- 如何配置Hadoop的 Secondary节点 & NameNode节点失效恢复
- Hadoop配置启动SecondaryNameNode
- [zz]hadoop下运行多个SecondaryNameNode的配置
- hadoop下运行多个SecondaryNameNode的配置
- hadoop2.X如何将namenode与SecondaryNameNode分开配置
- SecondaryNamenode配置与NameNode故障恢复
- secondaryNamenode配置与nameNode故障恢复
- Hadoop根据SecondaryNameNode恢复NameNode
- Hadoop secondarynamenode两种配置方式
- hadoop secondarynamenode的两种配置方式
- Hadoop根据SecondaryNameNode恢复NameNode
- hadoop下运行多个SecondaryNameNode的配置
- hadoop 根据SecondaryNameNode恢复Namenode
- hadoop 2.4.1 secondaryNameNode 配置及启动:
- 第117讲:Hadoop集群之安装IP配置、Slaves、namenode和secondarynamenode的配置学习笔记
- hadoop2.X如何将namenode与SecondaryNameNode分开配置
- Hadoop2.2.0中配置SecondaryNameNode
- hadoop 根据SecondaryNameNode恢复Namenode
- Hadoop 从SecondaryNamenode 恢复NameNode
- SecondaryNameNode配置和恢复